






一、什么是大模型微调?
1、概念
大模型微调(Fine-tuning)是指在一个预训练好的大规模机器学习模型(如GPT、BERT、ResNet等)的基础上,通过少量领域或任务相关的数据进一步调整模型参数,使其更适应特定任务或场景的技术。它是迁移学习的核心方法之一。
2、为什么要进行微调?
基座模型具有“通才困境”。像ChatGPT、Llama这类预训练大模型,本质上是通过海量通用数据(书籍、网页、百科等)学习了“通识能力”——比如理解语法、基础逻辑、常见知识。但这也意味着:
-
缺乏垂直领域深度:对医学、法律、金融等专业术语的理解停留在表面,可能混淆概念。
-
无法适配特定格式:生成内容的结构可能不符合行业规范(如医疗报告需包含“主诉、病史、诊断”等固定模块)。
-
缺少私有信息:无法回答组织内部知识(如某医院独有的病历模板、科室术语缩写)。
3、微调的方法
大模型微调的常见方法可以根据参数调整的范围、资源消耗和实现方式分为以下几类:全参数微调(Full Fine-tuning)、部分参数微调(Partial Fine-tuning)、适配器微调(Adapter Tuning)、提示微调(Prompt Tuning)、LoRA(Low-Rank Adaptation)、前缀微调(Prefix Tuning)、知识蒸馏(Knowledge Distillation) 、SFT(有监督微调)等。
接下来以SFT为例 → 通常语言模型的初始训练是无监督的,但微调是有监督的。
二、基于阿里qwen2.5进行实操
1、环境配置
为方便练习,我们选用免费的魔塔社区(首页 · 魔搭社区)进行大模型微调学习。成功创建账号登录后,我们可以进入模型库进行模型选择,本文以qwen2.5的7B模型作为实操用例。原因如下:① 下载等待时间不会太长;② 整体模型大小适中,不会超出持久化存储占用的100G限制。
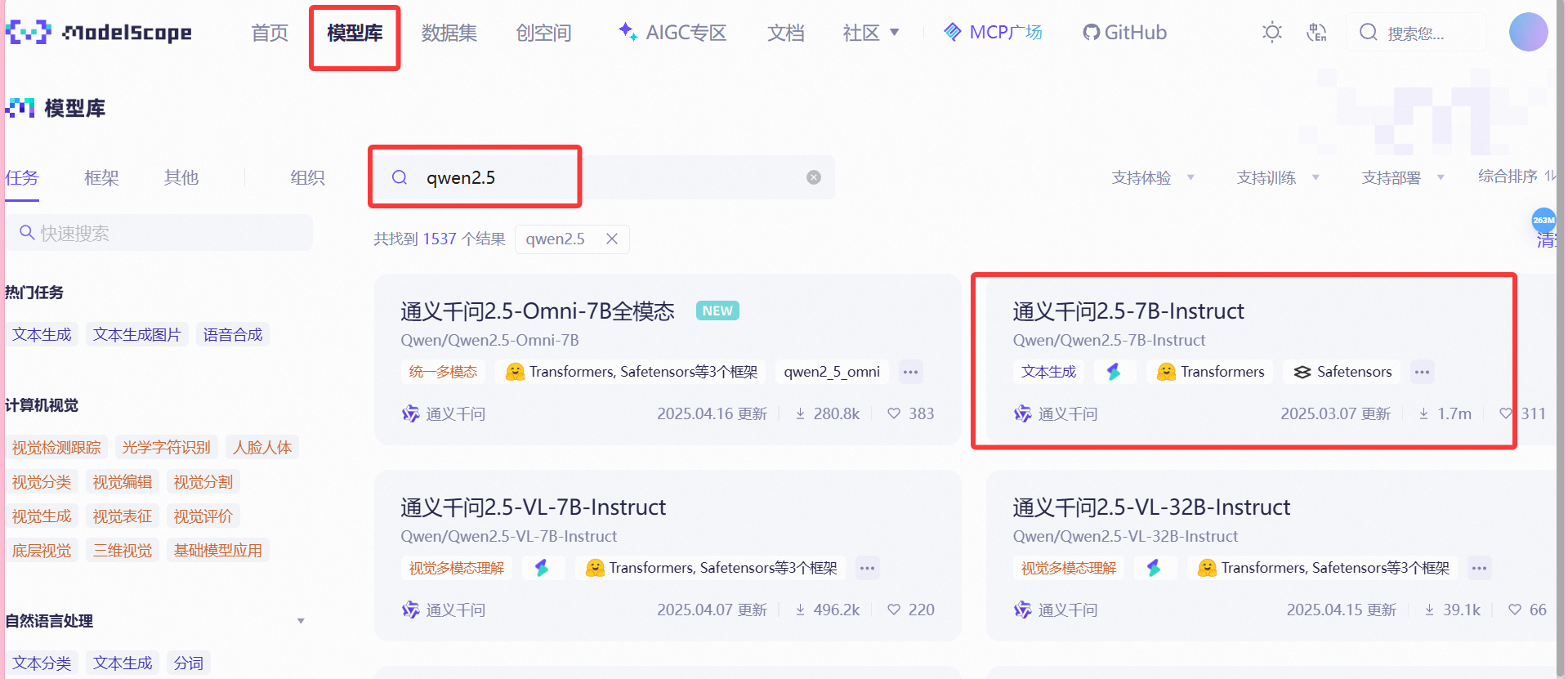
当然,你也可以选择其他的模型,但记得提前查看估算模型总大小是否会超出100G的限制:
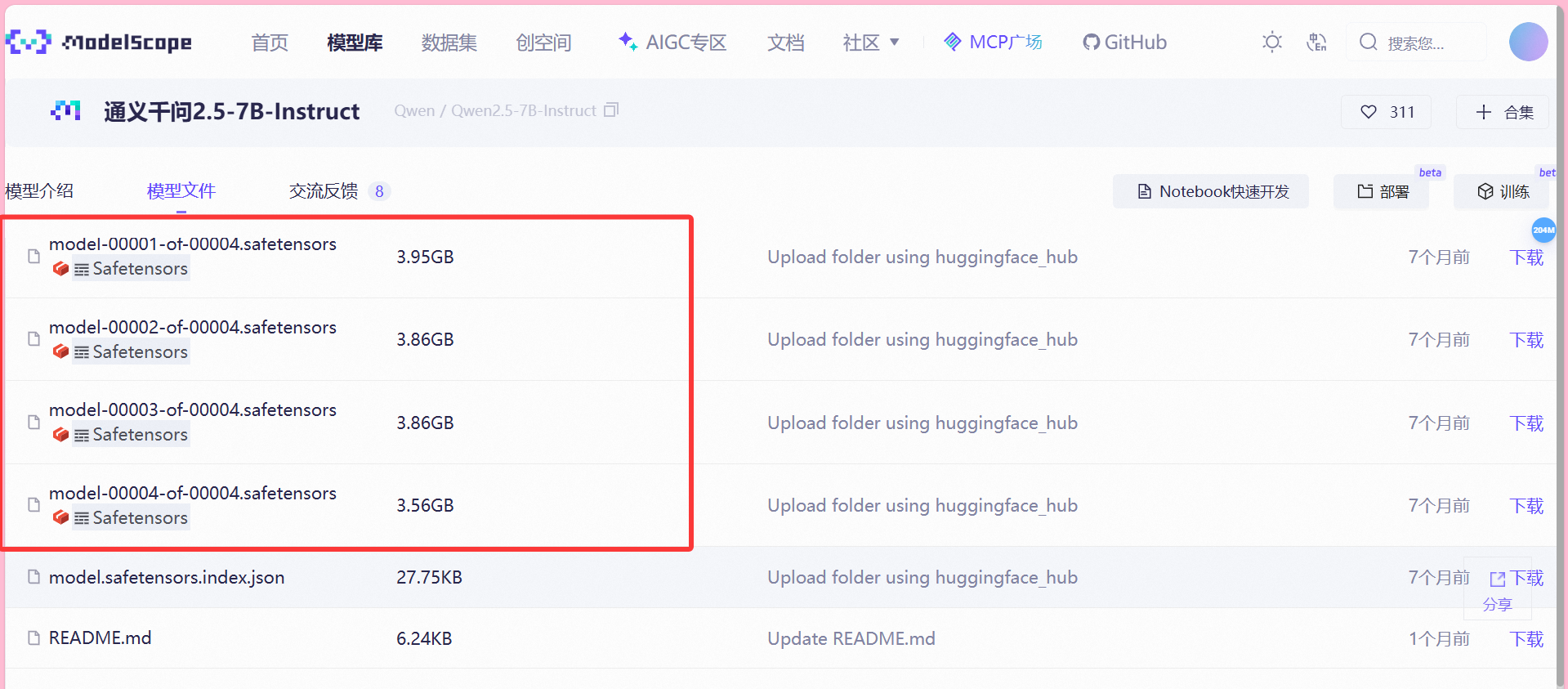 之后我们选择右上角的Notebook快速开发 → 使用魔塔平台提供的免费实例
之后我们选择右上角的Notebook快速开发 → 使用魔塔平台提供的免费实例
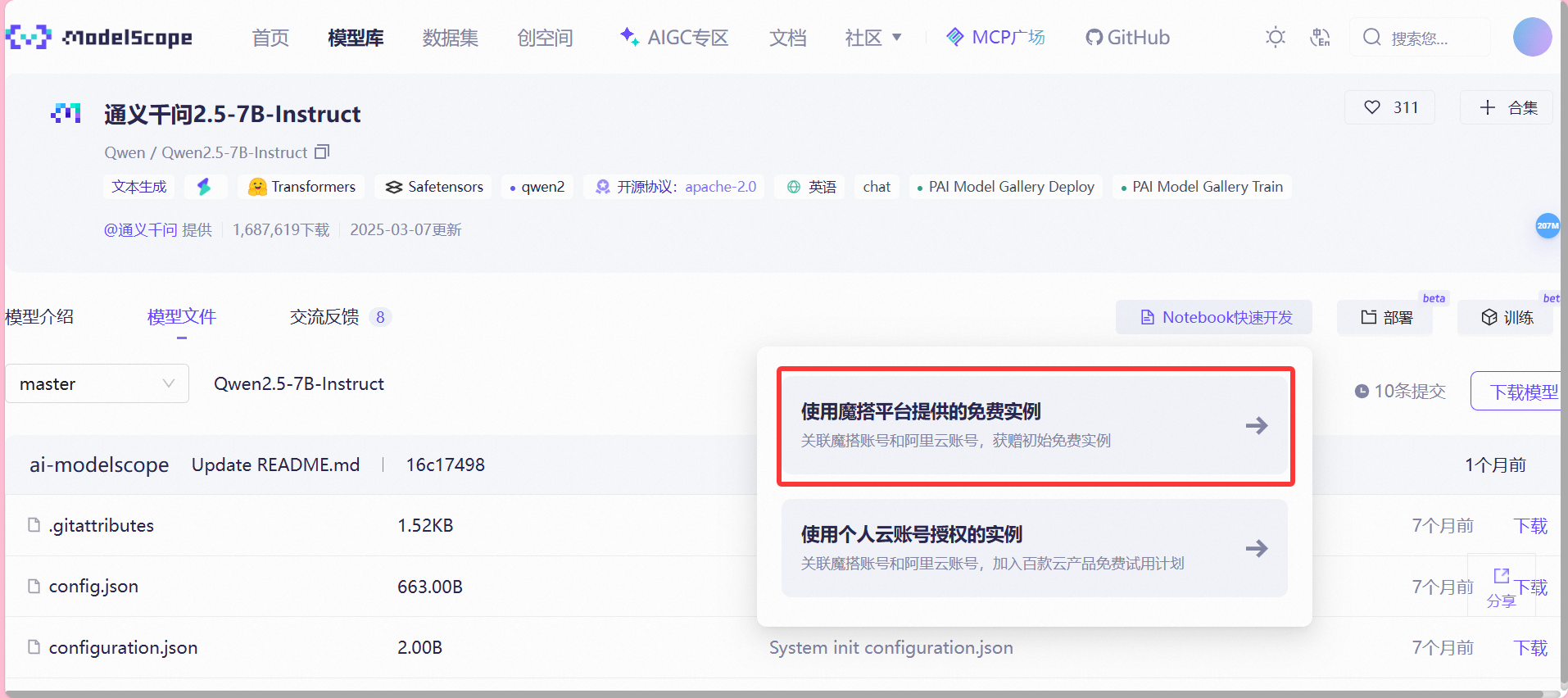
并选择GPU环境,接着左下角启动。等GPU环境启动好以后点击"查看NoteBook"进入
进入如下界面视为成功,同时我们进入Notebook
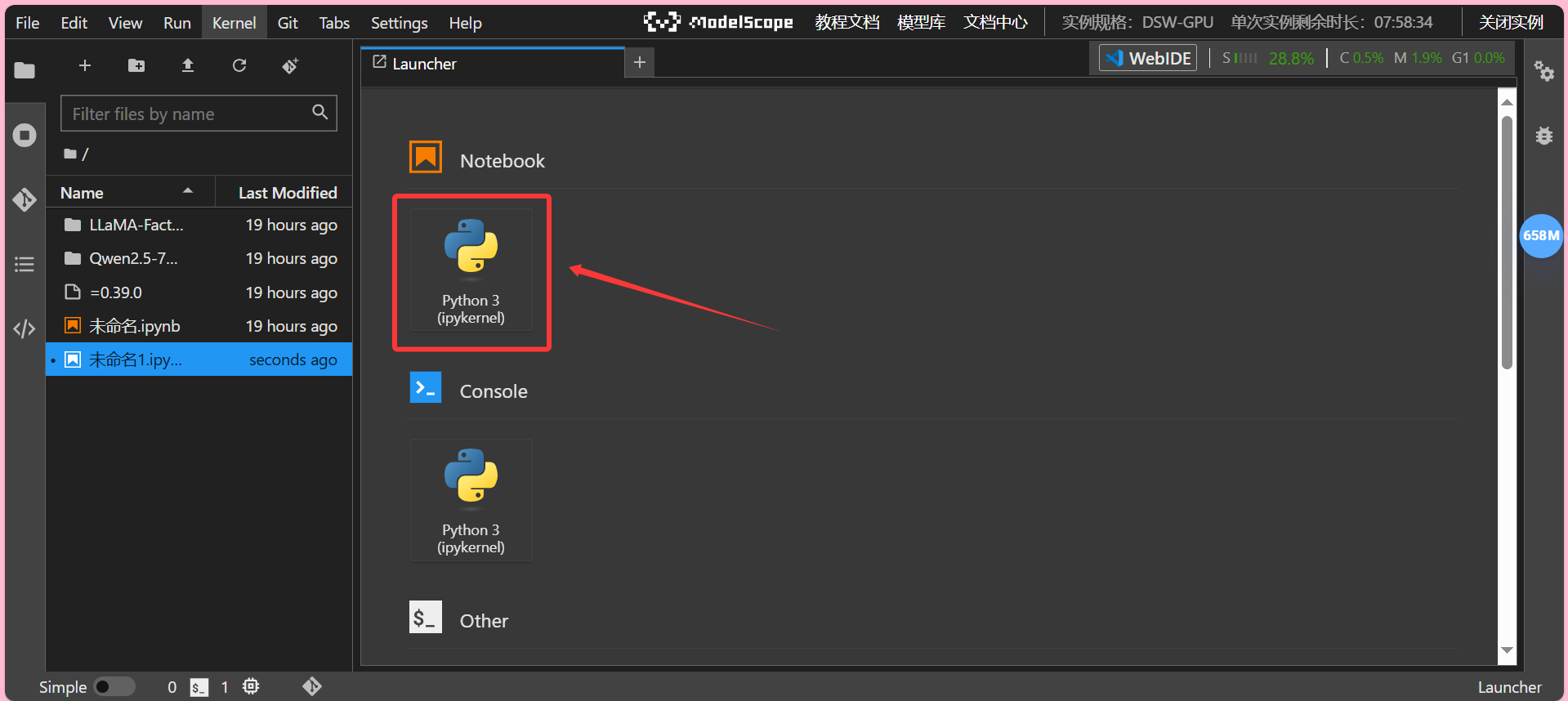 在代码块中先进行环境配置,输入如下:
在代码块中先进行环境配置,输入如下:
!pip3 install --upgrade pip
!pip3 install bitsandbytes>=0.39.0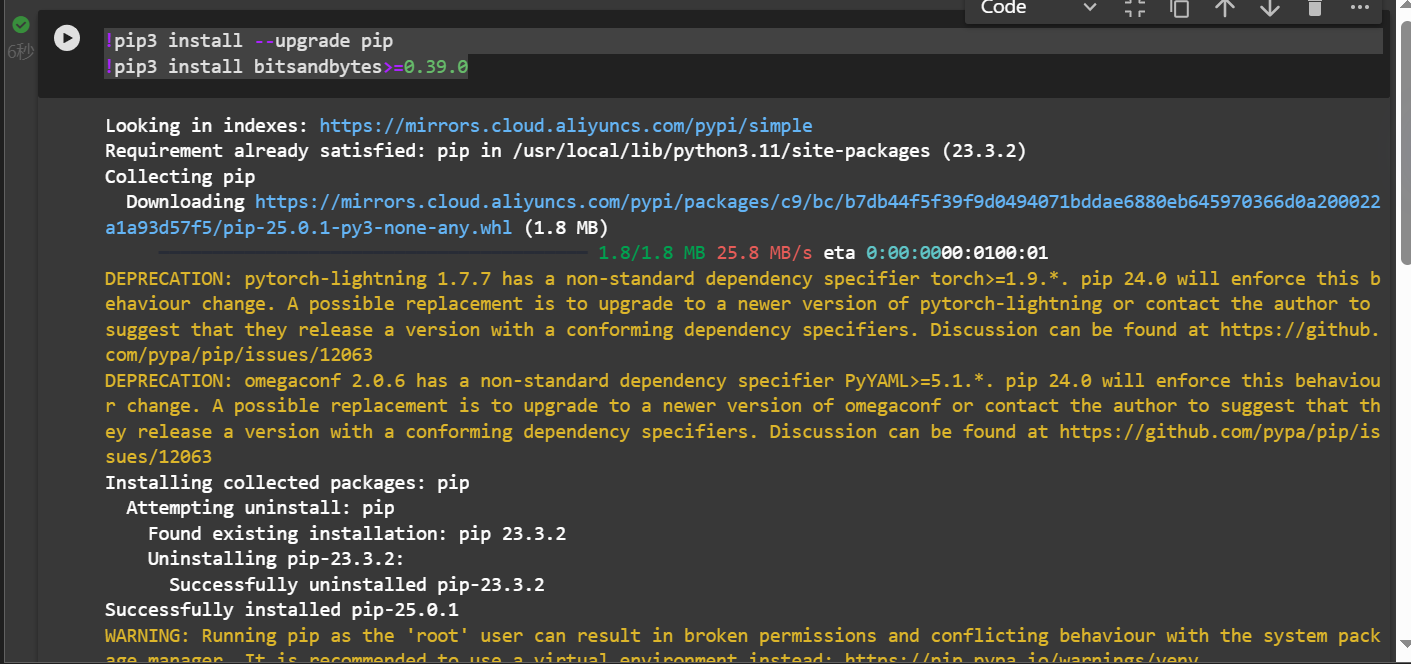
接着我们需要拉取LLaMA-Factory ,使用下面命令拉取:
!git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
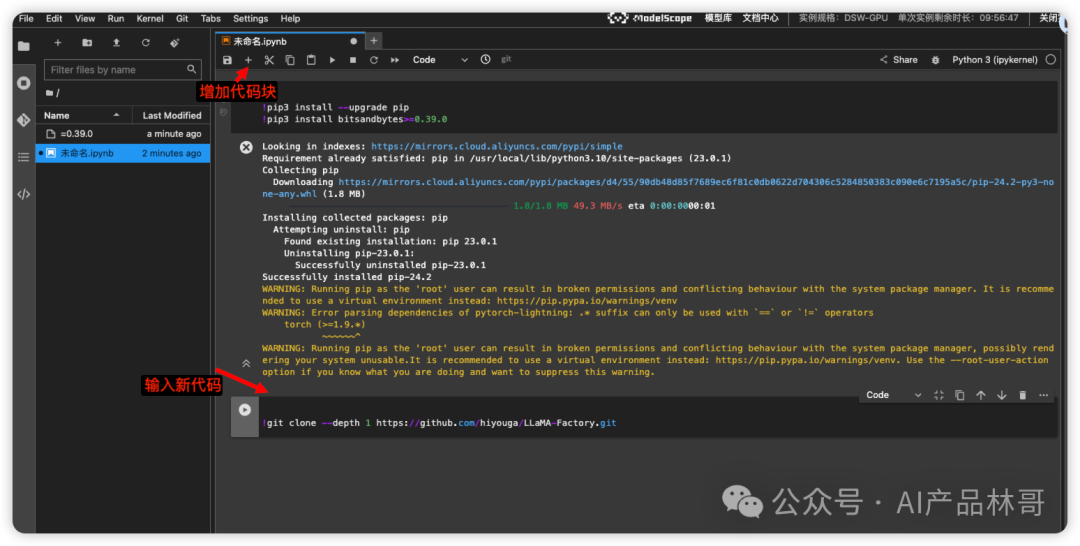LLaMA Factory是一款开源低代码大模型微调框架,集成了业界广泛使用的微调技术,想进一步深入了解的可以跳转:github.com
拉取成功后,我们左侧的目录中会出现名为LLaMA-Factory的文件夹,这时我们选择窗口栏的“+”回到Launcher 并打开一个新的Terminal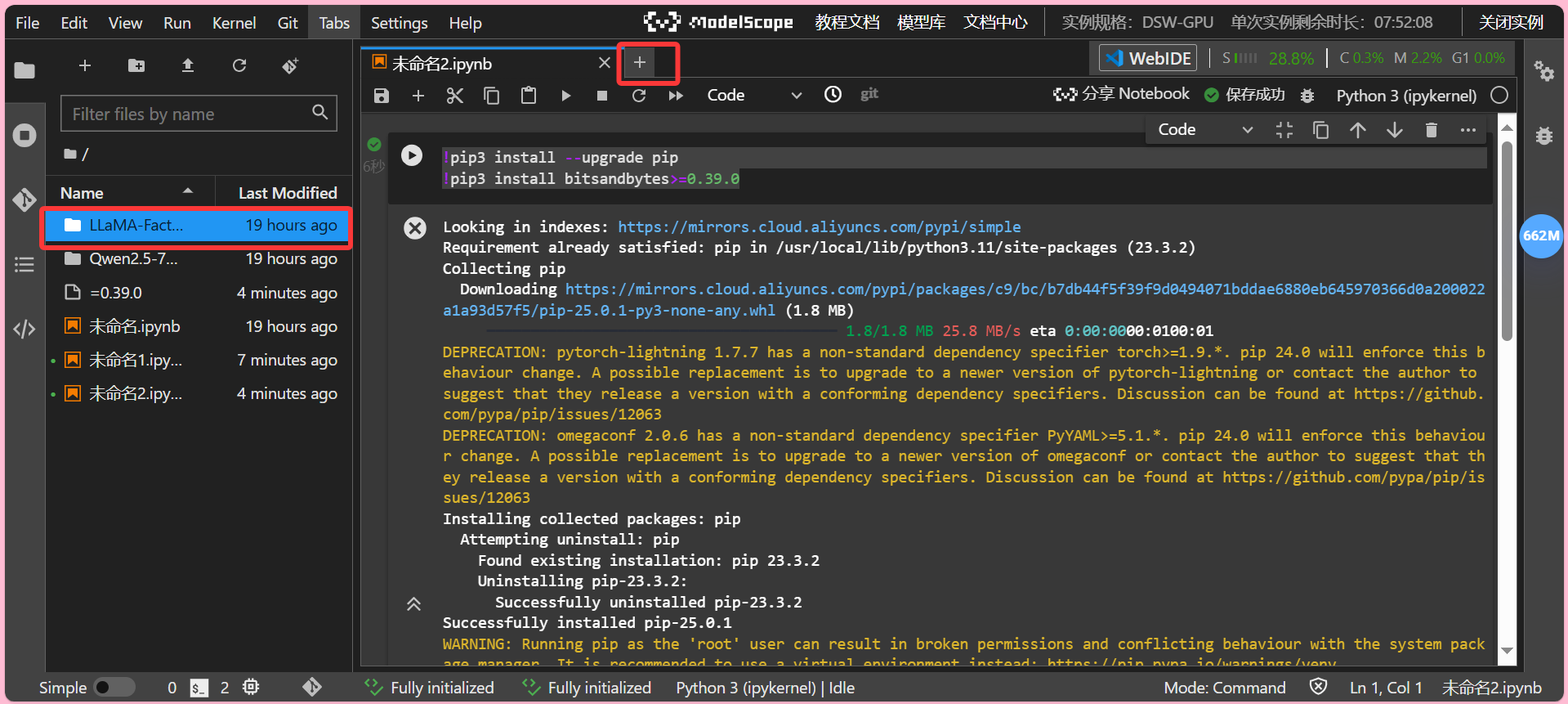
在Terminal中我们依次输入如下命令,安装依赖的软件:
cd LLaMA-Factory
pip3 install -e ".[torch,metrics]"当然,可能会出现如下报错:
error: invalid-installed-package
× Cannot process installed package omegaconf 2.0.6 in '/usr/local/lib/python3.11/site-packages' because it has an invalid requirement:
│ .* suffix can only be used with `==` or `!=` operators
│ PyYAML (>=5.1.*)
│ ~~~~~~^
╰─> Starting with pip 24.1, packages with invalid requirements can not be processed.
hint: To proceed this package must be uninstalled.我们先执行升级omegaconf的命令,再重新执行前面的安装步骤即可:
pip install --upgrade omegaconf
pip3 install -e ".[torch,metrics]"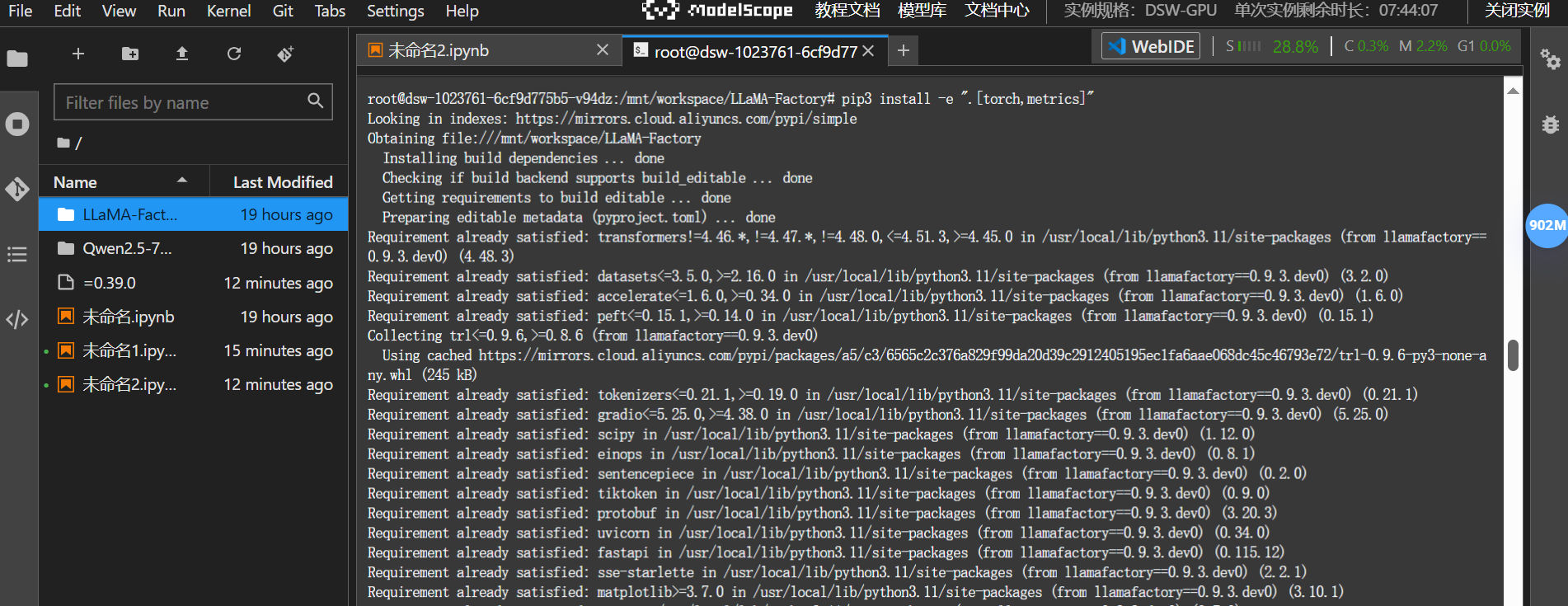
2、模型下载
上述执行完成后,我们模型文件界面,选择下载模型,并复制git方式的链接: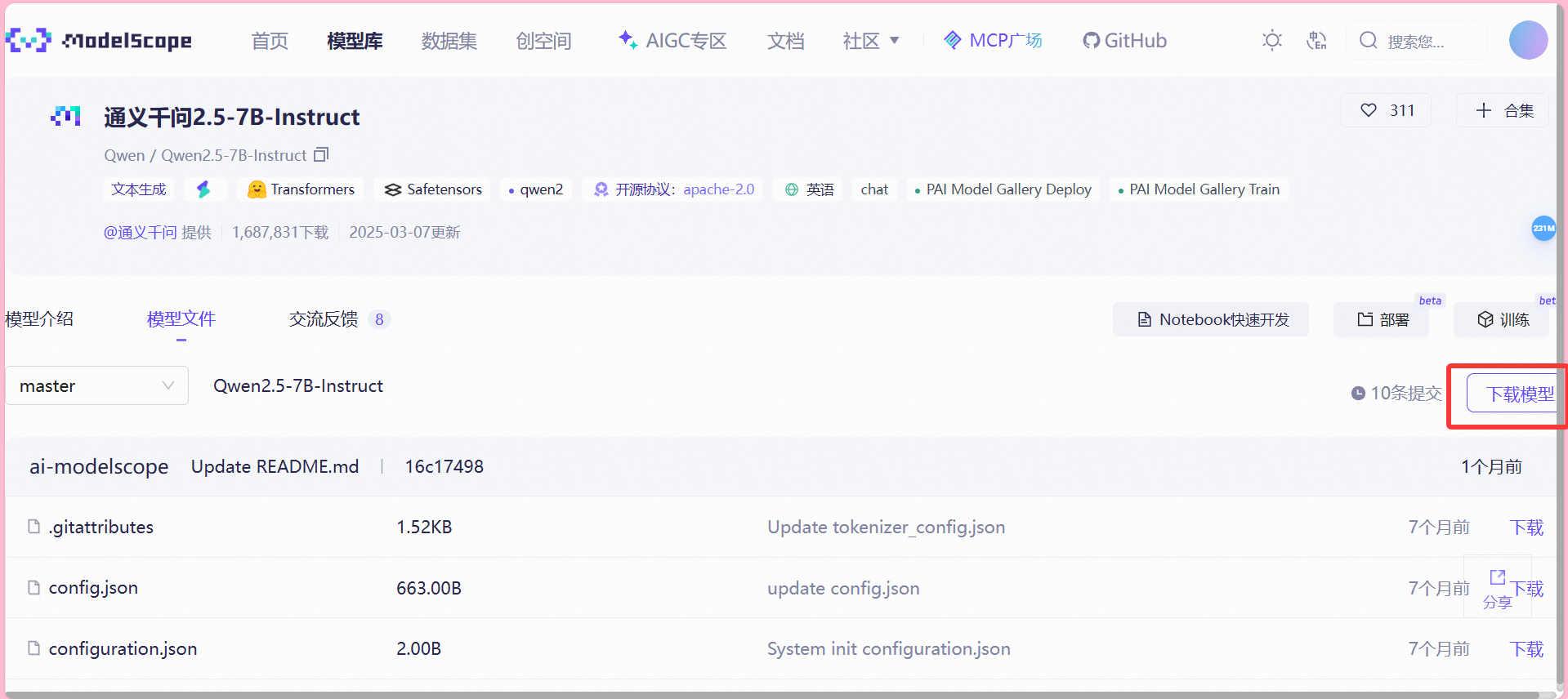
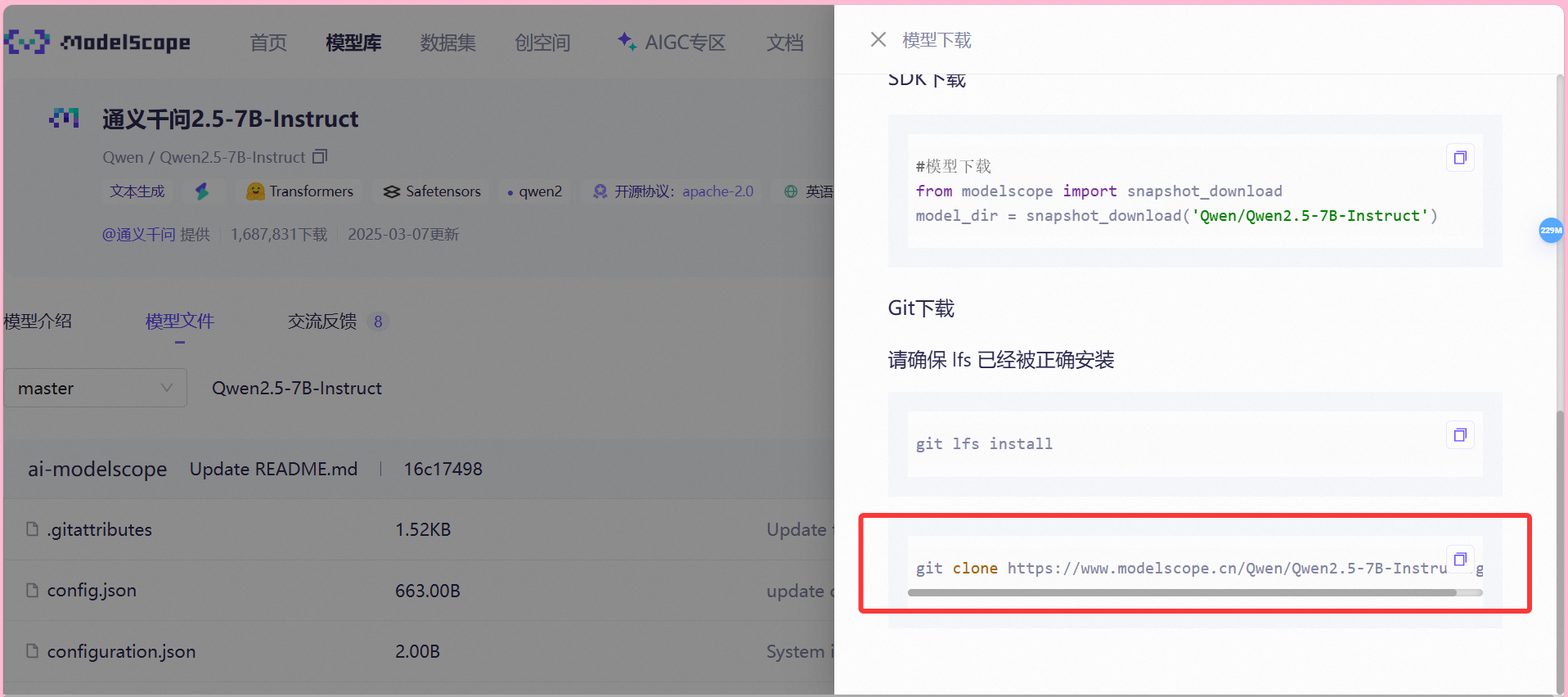
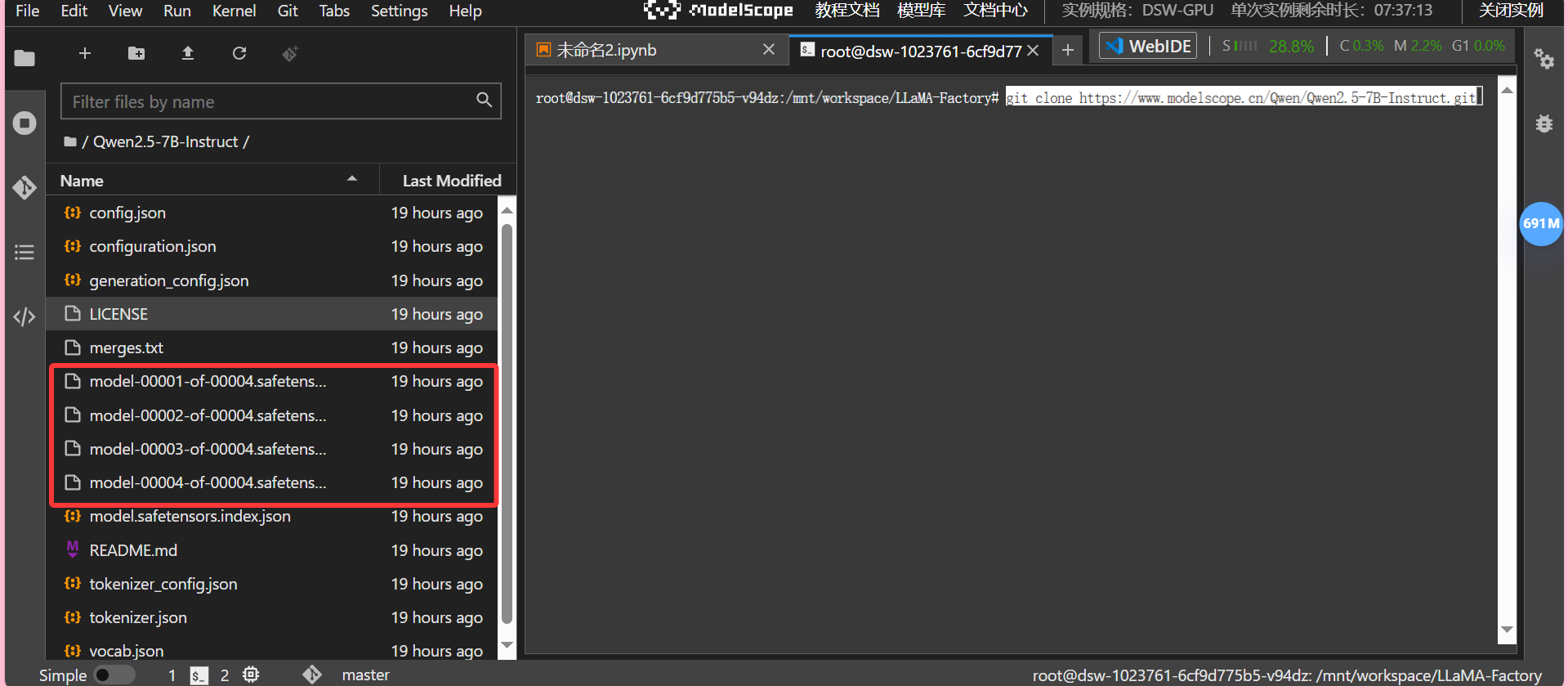
回到Terminal输入链接命令,拉取模型文件,完成后,左侧文件栏会出现模型文件夹(请稍等片刻,让主要的四个模型文件都拉取完毕)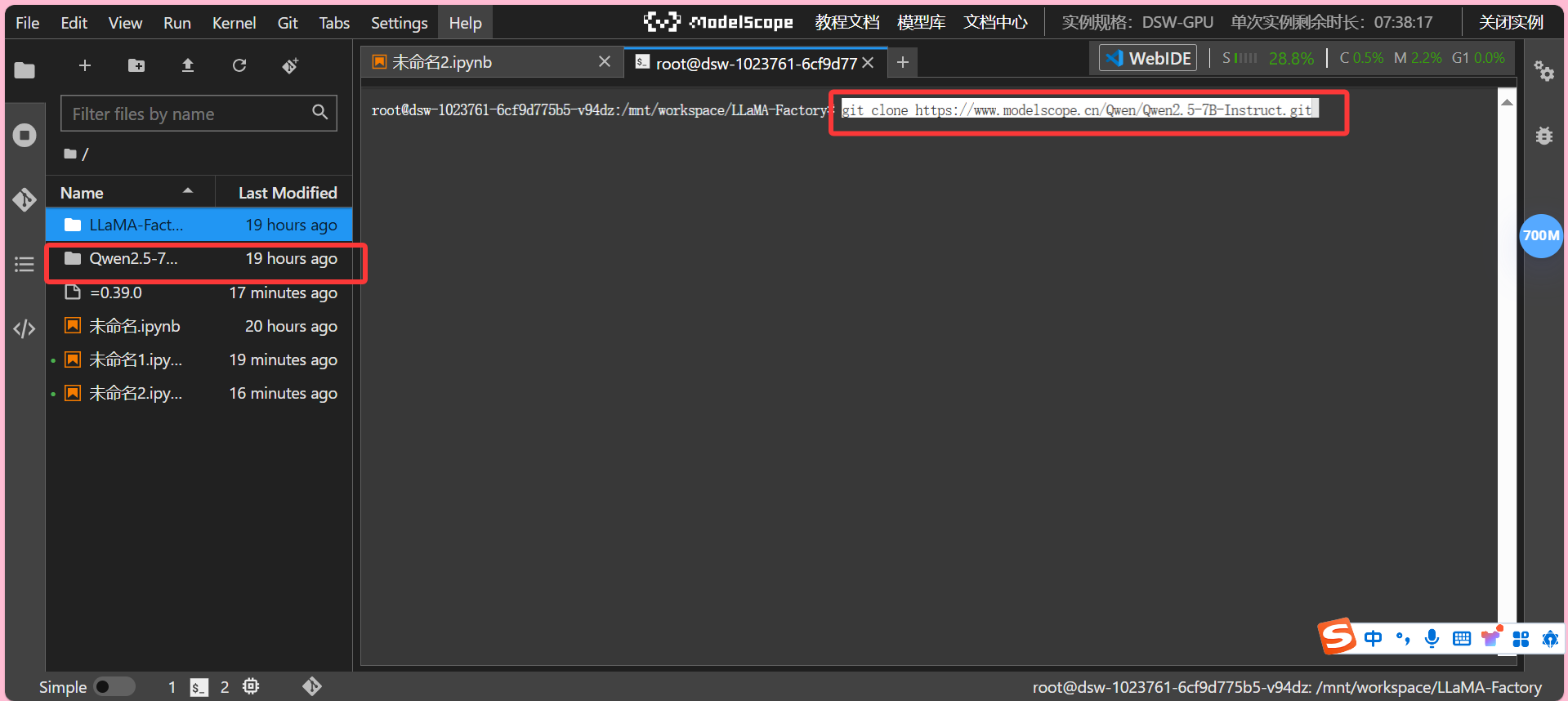
 3、配置文件
3、配置文件
从左侧文件列表的LLaMA-Factory/examples/train_qlora/ 来到配置文件放置的目录,根据自己的喜好,从任意yaml配置文件中复制一份模板至自己新建的配置文件中,例如我复制llama3_lora_sft_awq.yaml 中的 内容至我自己的 exercise.yaml文件中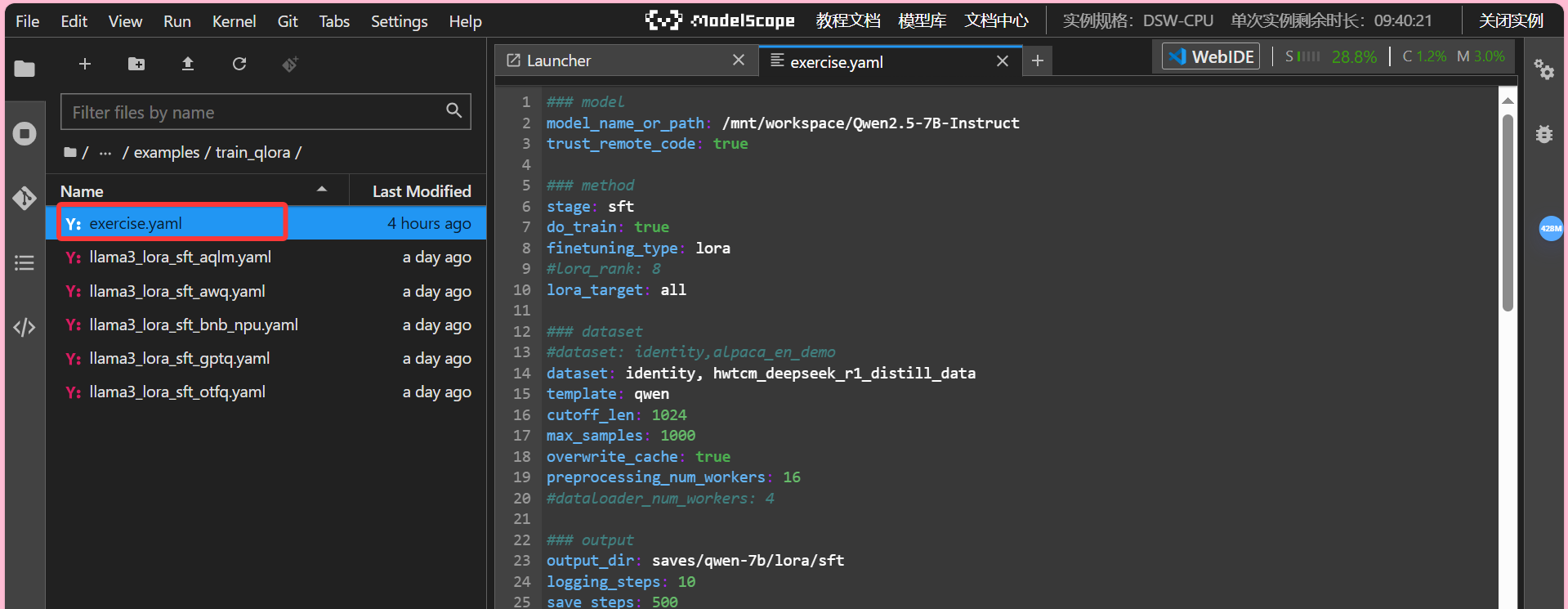
现在开始修改里面的参数,第一行为我们之前下载模型的位置,默认为
/mnt/workspace/Qwen2.5-7B-Instruct我的具体参数如下 :
### model
model_name_or_path: /mnt/workspace/Qwen2.5-7B-Instruct
trust_remote_code: true
### method
stage: sft
do_train: true
finetuning_type: lora
#lora_rank: 8
lora_target: all
### dataset
#dataset: identity,alpaca_en_demo
dataset: identity, hwtcm_deepseek_r1_distill_data
template: qwen
cutoff_len: 1024
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16
#dataloader_num_workers: 4
### output
output_dir: saves/qwen-7b/lora/sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
#save_only_model: false
#report_to: none # choices: [none, wandb, tensorboard, swanlab, mlflow]
### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
#ddp_timeout: 180000000
### eval
val_size: 0.1
per_device_eval_batch_size: 1
eval_strategy: steps
eval_steps: 500
详细的参数解释可以参考调优算法 - LLaMA Factory下面是我的理解:
一、model(基础模型设置)
model_name_or_path
指定要加载的预训练模型路径或名称,此处指向本地的Qwen2.5-7B-Instruct。trust_remote_code
是否信任来自 Hub 上数据集/模型的代码执行。
二、method(微调方式)
stage
微调阶段,这里sft表示监督微调(Supervised Fine-Tuning)。do_train
是否执行训练流程,true则会进入训练。finetuning_type
微调类型,此处为lora,即使用 LoRA (低秩适配)参数高效微调。lora_target
指定应用 LoRA 的模块范围,all表示对模型的所有部分都应用 LoRA 微调。
三、dataset(数据集与预处理)
dataset
指定了使用的数据集identity和hwtcm_deepseek_r1_distill_data两部分。template
数据输入的模板类型,qwen表示采用 Qwen 系列推荐的 prompt 模板。cutoff_len
文本截断长度上限(Token 数),超过则裁剪,降低显存占用,此处为 1024。max_samples
从数据集中抽取的最大样本数,1000表示本次训练最多取一千条。overwrite_cache
是否在预处理时强制重新生成缓存,true可确保每次都用最新逻辑切分。preprocessing_num_workers
数据预处理时并行的子进程数,使用 16 进程以加快 tokenize 等操作。
四、output(输出与日志)
output_dir
训练结果保存路径,此处为saves/qwen-7b/lora/sft。logging_steps
日志(如 loss)打印间隔,训练多少步记录一次,此处每 10 步。save_steps
模型检查点保存间隔,训练多少步保存一次,此处500步。plot_loss
是否实时绘制 loss 曲线;true可生成训练可视化图。overwrite_output_dir
如果输出目录已存在,是否覆盖旧内容;true表示直接覆盖。
五、train(训练超参数)
per_device_train_batch_size
每个 GPU/每个设备上的训练批大小,此处设为 1。gradient_accumulation_steps
累积多少步梯度再做一次反向更新,相当于将有效 batch 大小 ×8。learning_rate
学习率,控制参数更新步长,此处为 1e-4。num_train_epochs
总训练轮数,此处训练 3.0 轮。lr_scheduler_type
学习率调度方式,cosine表示余弦退火。这种策略可以在训练过程中逐渐降低学习率,有助于提高模型的收敛速度和性能。warmup_ratio
学习率预热比例,前 10% 步数线性升至最大学习率。bf16
使用 bfloat16 混合精度训练,可减小显存占用并加速。(ddp_timeout)
分布式训练时进程等待超时时间设定。
六、eval(评估策略)
val_size
验证集占比,0.1表示将 10% 的训练数据用作验证。per_device_eval_batch_size
每个设备的评估批大小,此处为 1。eval_strategy
评估触发方式,steps表示按步数评估。eval_steps
多久进行一次评估,此处每 500 步执行一次。
因此,从上面可得,这次微调使用的数据集为 identity和 hwtcm_deepseek_r1_distill_data ,当然你也可以修改其中的内容、手动上传自己的数据集或从平台上获取他人分享的数据集进行训练
4、微调模型
保存刚才对于 exercise.yaml 文件的更改,回到终端terminal 继续操作,输入如下训练命令:
llamafactory-cli train examples/train_qlora/exercise.yaml
如果出现如下报错,
bash: llamafactory-cli: 未找到命令
bash: ![]: event not found
则先执行下面命令再重复操作依次训练:
pip install -e ".[torch,metrics]"当出现白色进度条时,就是正在进行微调了。当页面不在变化,且出现loading checkpoint字样,则代表微调结束。
5、测试模型
回到examples\inference下提供的任意yaml模板,复制一份,并重命名为exercise_sft.yaml,修改model_name_or_path 参数为之前下载的模型位置(本文为Qwen2.5-7B-Instruct),并保存。
model_name_or_path: /mnt/workspace/Qwen2.5-7B-Instruct
adapter_name_or_path: saves/qwen-7b/lora/sft
template: qwen
infer_backend: huggingface # choices: [huggingface, vllm, sglang]
trust_remote_code: true
回到Terminal,cd 至LLaMA-Factory目录,并执行推理命令:
llamafactory-cli chat examples/inference/exercise_sft.yaml等待加载完毕,会在Terminal中显示"User:",即可在后面输入内容开始聊天了。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











