







读完本文,你将收获如下:
①HDFS读文件的整体流程。
②读取数据过程中的一些细节,例如:如果文件的最后一个block正在写,客户端能否读到?客户端选择哪个DataNode去读?
③ LocatedBlocks对象图解、DFSInputStream关键成员变量的释义等。
下面正式开始本文:
一、前置知识
1.1 LocatedBlocks对象
结构大致如下图所示:
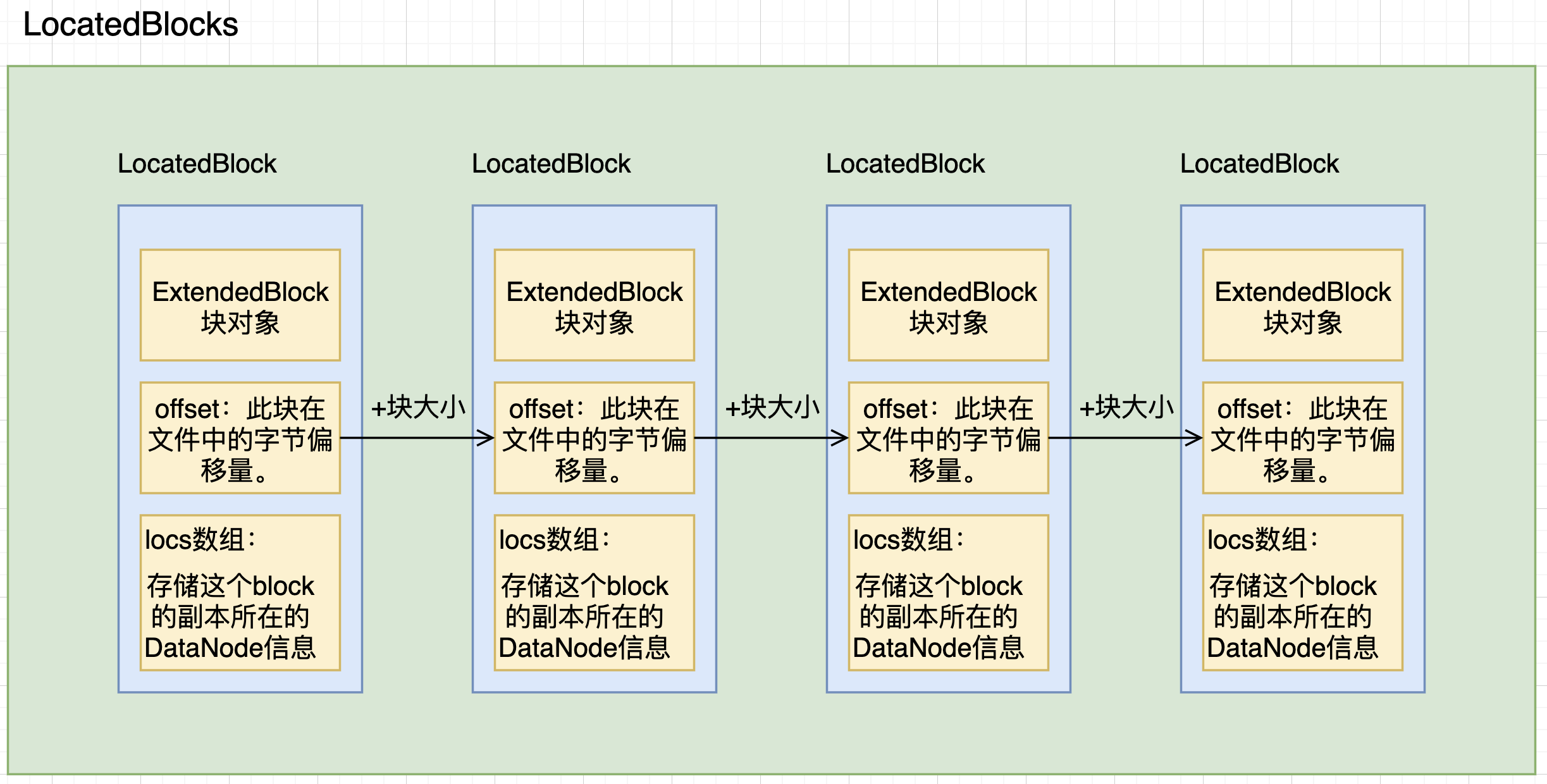
客户端调用getBlockLocations RPC后,NameNode返回给客户端LocatedBlocks对象。包含了文件指定范围内的block所在的DataNode位置locs等信息,其中这个locs数组是经过排序的,排序规则利用了网络的拓扑信息(机架信息),距离Client网络距离最近的DataNode将会排在locs数组的前面。规则如下:
Hadoop采用一个简单的方法:把网络看做一棵树,两个节点间的距离是它们到最近共同祖先的距离总和。该树中的层次是没有预先设定的,但是相对于数据中心、几家和正在运行的节点,通常可以设定等级。具体想法是针对以下每个场景,可用带宽依次递减:
同一个节点上的进程
同一机架上的不同节点
同一数据中心中不同机架上的节点
不同数据中心中的节点例如,假设有数据中心 d1 机架 r1 中的节点 n1.该节点

 订阅专栏 解锁全文
订阅专栏 解锁全文
















 382
382











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











