







 本文介绍了统计建模比赛论文写作中涉及的关键技术和步骤,包括数据处理(数据标签、编码、异常值处理)、样本平衡、特征选择、多种量化评价方法(层次分析、因子分析、DEA等)、预测模型(如线性回归、灰色预测、机器学习模型)以及数据预处理和分类技术(如决策树和BP神经网络)。
本文介绍了统计建模比赛论文写作中涉及的关键技术和步骤,包括数据处理(数据标签、编码、异常值处理)、样本平衡、特征选择、多种量化评价方法(层次分析、因子分析、DEA等)、预测模型(如线性回归、灰色预测、机器学习模型)以及数据预处理和分类技术(如决策树和BP神经网络)。
随着统计建模比赛时间越来越近,论文的编写也要提上日程了,这篇博客汇总了常用的数据分析、数学模型和算法,一起来学习一下吧!

数据处理
数据标签
数据标签相当于对定类变量的文本进行修改。

输入:一项定类变量。
输出:定类变量的文本标签修改。
数据编码
数据编码是将变量数值再次进行编码,可进一步浓缩或整合原始数据。

输入:一项定量或定类变量。
输出:对变量每个值进行重新编码。
异常值处理
无效样本处理
生成变量
生成变量是对单变量或多变量进行计算。其中平均值、求和、乘积(交互项)是多变量计算,即对多个变量的均值、加和、乘积的结果;自然对数、Log10是单变量计算,即对单个变量的数据的值进行计算。

数据标准化
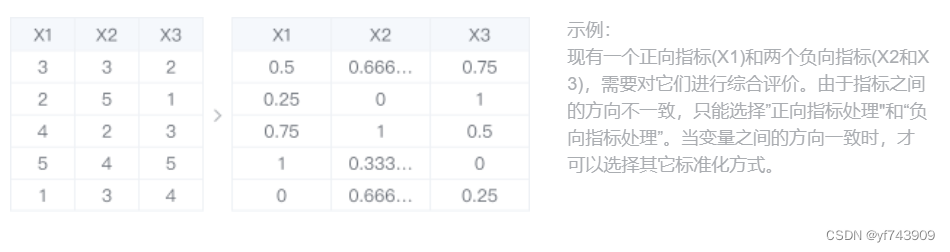
数据标准化包括去量纲化和一致化。去量纲化是指不同指标之间由于量纲不同以致于其不具可比性,故首先需将指标进行无量纲化,消除量纲影响后再进行接下来的分析。例如,某个变量的数值在1-10之间,而另一个变量的数值范围在100-1000之间,此时若进行综合评价,从数值的角度,很有可能数值变化范围大的变量,它的绝对作用就会较大,所占的比重较大。一致性是指将指标作用方向一致化,例如我们在评价多个不同指标的作用时,正向指标是数值越大越好,负向指标是数值越小越好,如果同时评价这两类指标的综合作用,由于他们的作用方向不同,不能将指标作用直接相加,此时我们就需要对逆指标进行一致化处理。
虚拟变量转换
多分类变量是不能直接参与到回归计算中。对于有序定类变量,可以将它进行数据编码,利用数字来表示分类变量的有序等级;但是对于无序定类变量,需要将其转变为虚拟变量来处理。虚拟变量转换包括哑变量和独热编码,其中哑变量化比独热编码少了一列变量,这是因为独热编码容易造成共线性,而哑变量随机以一个选项作为参照项,下图例子以”其它“作为参照项,当学生=0且上班族=0时,很明显,此时就默认归为”其它“,且在对回归系数进行解释时,所有类别哑变量的回归系数,均表示该哑变量与参照项相比
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









