






在开始模型训练之前,数据准备是至关重要的一步。我们需要确保数据的质量,去除噪声、填补缺失值等。
在开始模型训练之前,数据准备是至关重要的一步。我们需要确保数据的质量,去除噪声、填补缺失值等。想象一下,如果我们用一堆杂乱无章的数据来训练模型,结果肯定会让人失望。因此,清洗数据、处理异常值是我们必须要做的功课。记住,好的开始是成功的一半!
特征选择是提高SVM效果的关键步骤,选择与分类结果密切相关的特征。
接下来,我们要谈谈特征选择。SVM的效果在很大程度上依赖于我们选择的特征。我们需要找到与分类结果密切相关的特征。比如,在文本分类中,关键词的选择至关重要;在图像识别中,边缘、颜色等特征可能会影响分类的准确性。通过特征选择,我们可以提高模型的性能,减少计算成本。
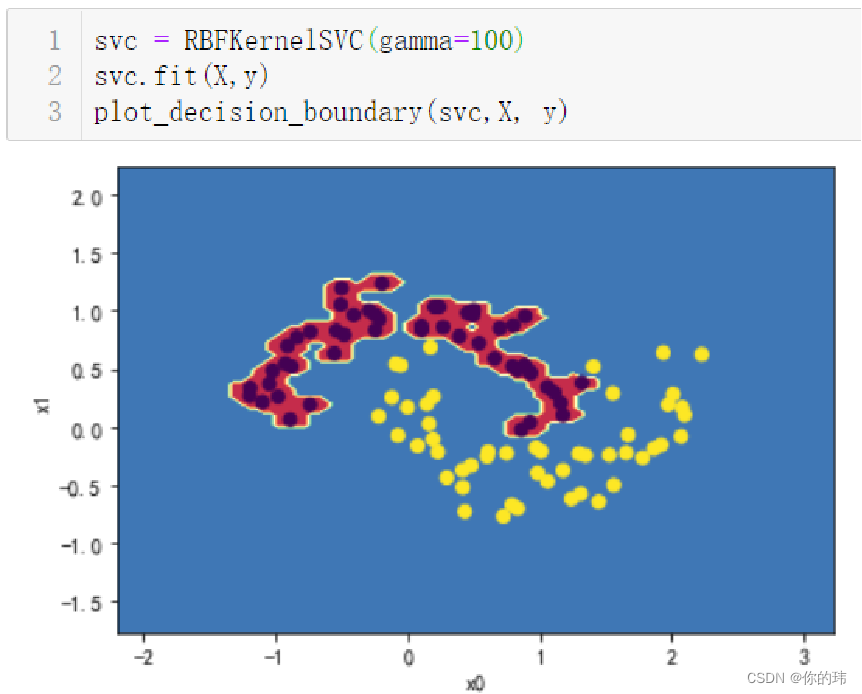
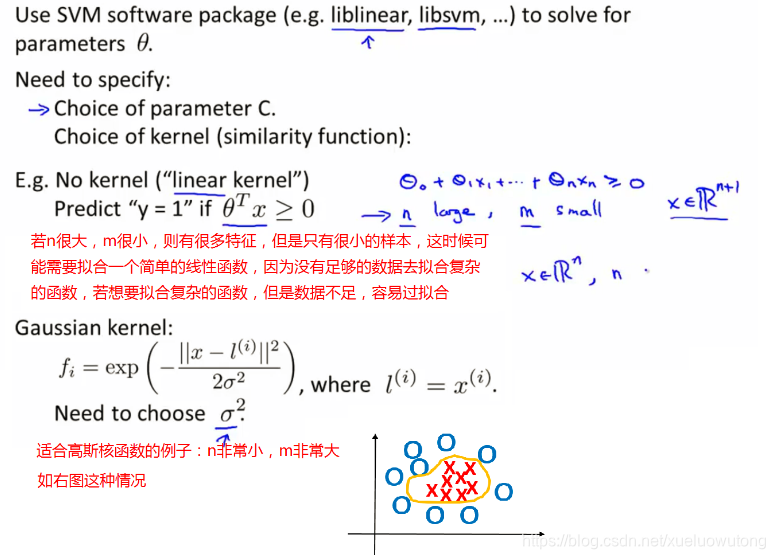
选择适当的核函数是构建SVM模型的关键步骤。
一旦数据准备和特征选择完成,我们就可以开始构建支持向量机模型了。这里的关键在于选择适当的核函数。SVM支持多种核函数,如线性核、径向基函数(RBF)等。选择合适的核函数可以帮助我们更好地适应不同的数据分布。比如,线性核适合线性可分的数据,而RBF核则适合复杂的非线性数据。选择合适的核函数,就像为一辆车选择合适的轮胎,能让它在不同的路况下行驶自如!
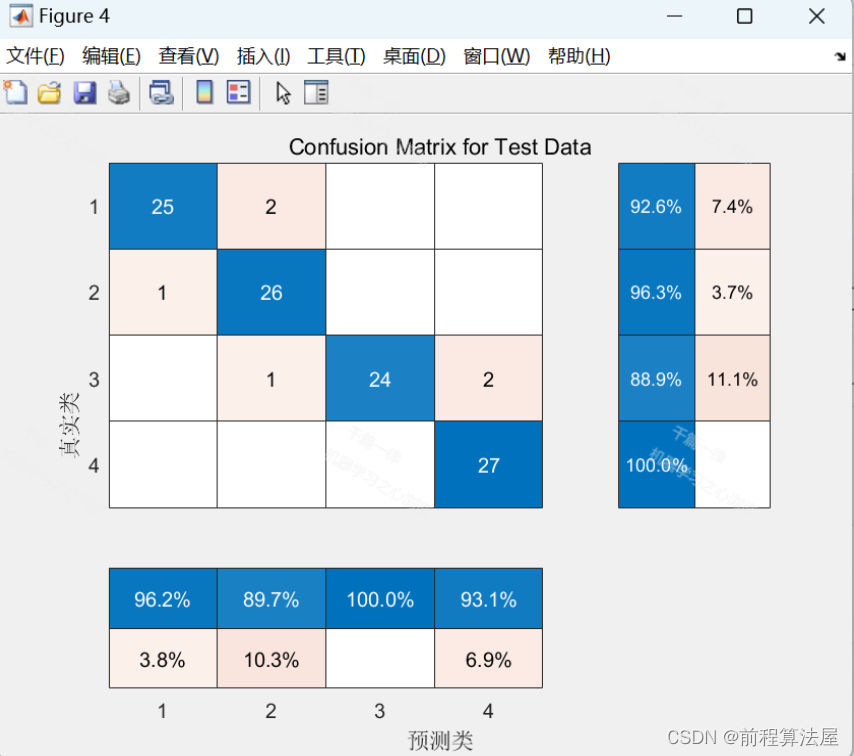
模型评估是确保模型有效性的关键步骤。
模型构建完成后,我们需要对其进行评估。使用测试集来评估模型的性能是非常重要的。我们可以查看分类准确率、混淆矩阵等指标,以确保模型的有效性。通过这些评估,我们可以了解模型的优缺点,进而进行调整和优化。
分析SVM的优缺点,探讨其在不同场景下的表现。
当然,支持向量机也有其优缺点。它的优点包括强大的分类能力和处理高维数据的能力,这使得它在许多领域表现出色。然而,SVM的计算成本较高,对大数据集的处理速度可能会变慢。为了克服这些缺点,近年来出现了一些SVM的变种和优化算法,比如线性SVM和分布式SVM等。这些新方法在处理大规模数据时表现得更加高效。
探讨SVM在实际应用中的广泛性和有效性。
在实际应用中,SVM被广泛应用于文本分类、图像识别、欺诈检测等场景。比如,在文本分类中,SVM可以帮助我们将电子邮件分为垃圾邮件和正常邮件;在图像识别中,它可以识别出不同的物体;在欺诈检测中,SVM可以帮助金融机构识别可疑交易。可以说,SVM在各个领域都展现了其强大的能力。
总结SVM的应用和重要性,鼓励读者继续探索机器学习的奥秘。
通过以上的分析,我们可以看到,支持向量机是一种强大的分类工具,能够帮助我们解决各种分类问题。无论是在数据准备、特征选择、模型构建还是模型评估的过程中,我们都需要认真对待每一个环节。希望这篇文章能为你提供一些实用的技巧和见解,帮助你在机器学习的道路上迈出成功的第一步!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









