







根据各种工具类最终编写出的数据处理脚本文件
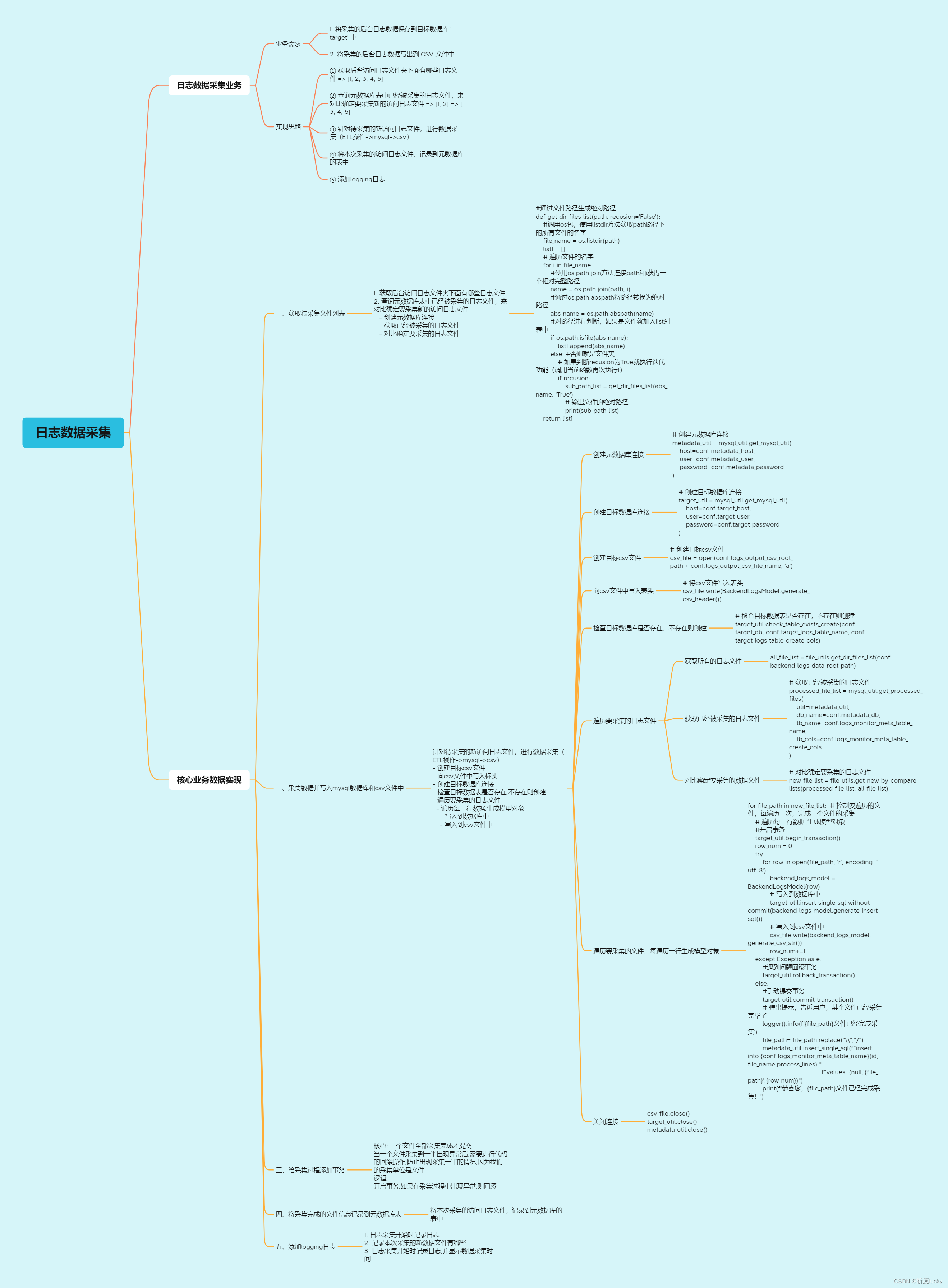
1,日志文件采集backend_logs_service.py
"""
1. 获取后台访问日志文件夹下面有哪些日志文件
2. 查询元数据库表中已经被采集的日志文件,来对比确定要采集新的访问日志文件
- 创建元数据库连接
- 获取已经被采集的日志文件
- 对比确定要采集的日志文件
3. 针对待采集的新访问日志文件,进行数据采集(ETL操作->mysql->csv)
- 创建目标csv文件
- 向csv文件中写入标头
- 创建目标数据库连接
- 检查目标数据库书否存在,不存在则创建
- 遍历要采集的日志文件
- 遍历每一行数据,生成模型对象
- 写入到数据库中
- 写入到csv文件中
4. 将本次采集的访问日志文件,记录到元数据库的表中
"""
# 0. 导包
import time
from util import file_util
from util import mysql_util
from util import logging_util
from config import project_config as conf
from model.backend_logs_model import BackendLogsModel
# 日志1: 创建日志对象
logger = logging_util.init_logger()
# 日志2: 记录日志采集开始
logger.info('日志采集开始....')
# 1. 获取后台访问日志文件夹下面有哪些日志文件(file_util)
all_file_list = file_util.get_dir_files_list(conf.backend_logs_data_root_path)
# 2. 查询元数据库表中已经被采集的日志文件,来对比确定要采集新的访问日志文件
# 2.1 创建元数据库连接(mysql_util)
metadata_util = mysql_util.get_mysql_util(
host=conf.metadata_host,
port=conf.metadata_port,
user=conf.metadata_user,
password=conf.metadata_password
)
# 2.2 获取已经被采集的日志文件(mysql_util)
processed_file_list = mysql_util.get_processed_files(
util=metadata_util,
db_name=conf.metadata_db,
tb_name=conf.logs_monitor_meta_table_name,
tb_cols=conf.logs_monitor_meta_table_create_cols
)
# 2.3 对比确定要采集的日志文件(file_util)
new_file_list = file_util.get_new_by_compare_lists(processed_file_list, all_file_list)
# 日志3: 记录采集的新文件有哪些
if not new_file_list:
logger.info('没有待采集文件,所有文件已经采集完成,退出程序...')
exit('日志采集结束...')
else:
logger.info(f'待采集的文件有{new_file_list}...')
# 3. 针对待采集的新访问日志文件,进行数据采集(ETL操作->mysql->csv)
# 3.1 创建目标csv文件
csv_file = open(conf.logs_output_csv_root_path + conf.logs_output_csv_file_name,
'a',
encoding='utf8')
# 3.2 向csv文件中写入标头
csv_file.write(BackendLogsModel.generate_csv_header())
# 3.3 创建目标数据库连接
target_util = mysql_util.get_mysql_util(
host=conf.metadata_host,
port=conf.metadata_port,
user=conf.metadata_user,
password=conf.metadata_password
)
# 3.4 检查目标数据库书否存在,不存在则创建
target_util.check_table_exists_and_create(
db_name=conf.metadata_db,
tb_name=conf.target_logs_table_name,
tb_cols=conf.target_logs_table_create_cols
)
# 日志4: 记录采集开始时间
start_time = time.time()
# 3.5 遍历要采集的日志文件(从2.3步获取的new_file_list)
for file_path in new_file_list:
# 事务1: 开启事务
target_util.begin_transaction()
row_total = 0
try:
# 3.6 遍历每一行数据,
for row_content in open(file_path, 'r', encoding='utf8'):
# 3.6.1 生成模型对象
backend_log_model = BackendLogsModel(row_content)
# 3.6.2写入到数据库中
target_util.insert_single_sql_without_commit(backend_log_model.generate_insert_sql())
# 3.6.3写入到csv文件中
csv_file.write(backend_log_model.gender_csv_str())
row_total += 1
except Exception as e:
# 事务2: 事务回滚
# log日志一般是按照时间排序的,所以如果出现回滚回滚后会结束 程序
target_util.rollback_transaction()
else:
# 事务3: 一个文件处理完成后提交事务
target_util.commit_transaction()
# 4. 将本次采集的访问日志文件,记录到元数据库的表中
# 4.1 创建sql语句
sql = f'insert into {conf.logs_monitor_meta_table_name}(' \
f'file_name, process_lines) values' \
f'("{file_path}","{row_total}");'
# 4.2 执行sql语句记录到元数据库中
metadata_util.insert_single_sql(sql)
# 日志5: 记录结束时间
end_time = time.time()
# 日志6: 记录日志,说明采集用时
logger.info(f'此次采集共采集了{len(new_file_list)}个文件, 共用时{end_time-start_time}s')
# 3.7 关闭csv文件
csv_file.close()
# 3.8 关闭数据库连接
target_util.close()
metadata_util.close()
2,商品数据采集barcode_service.py
# 3. 针对新增和更新的商品数据,进行数据采集(ETL->mysql->csv)
# - 创建目标数据库连接对象
target_util = mysql_util.get_mysql_util(
# retail作为目标库
host=conf.target_host,
user=conf.target_user,
password=conf.target_password
)
# - 检查目标数据库表是否存在,如果不存在则创建
target_util.check_table_exists_and_create(
conf.target_db,
conf.target_barcode_table_name,
conf.target_barcode_table_create_cols
)
# - 创建目标csv文件
csv_file = open(conf.barcode_output_csv_root_path + conf.barcode_orders_output_csv_file_name, 'a') # 不要设置编码
# - 写入csv的标头
csv_file.write(BarcodeModel.generate_csv_header())
# 开启事务处理、定义一个变量,用于记录目前已经采集的条目数
target_util.begin_transaction()
data_count = 0
# - 根据数据源采集结果创建数据模型
for row in result: # ((), (), ())
data_count += 1
try:
# 写入mysql数据库
model = BarcodeModel(row)
target_util.insert_single_sql_without_commit(model.generate_insert_sql())
# 写入csv文件
csv_file.write(model.generate_csv_str())
except Exception as e:
# 事务回滚
target_util.rollback_transaction()
exit('数据插入异常,请检查!')
else:
# 注意:每1000条记录,手工提交一次事务
if data_count % 1000 == 0:
target_util.commit_transaction()
# 事务提交以后,还需要把上一次的最大采集时间写入到元数据表
sql = f"insert into {conf.metadata_barcode_table_name}(time_record, gather_line_count) values ('{model.updateAt}', 1000)"
metadata_util.insert_single_sql(sql)
# 提交事务以后,事务处理就结束了,但是数据还没有处理完成,必须再次开启事务处理
target_util.begin_transaction()
else:
# 有一个问题:如果我们2001条记录,上面的语句刚才能处理2000条,不足1000的整数倍,则也需要手工提交
target_util.commit_transaction()
sql = f"insert into {conf.metadata_barcode_table_name}(time_record, gather_line_count) values ('{model.updateAt}', {data_count % 1000})"
metadata_util.insert_single_sql(sql)
# 提示用户数据采集已结束
print('恭喜您,信息已经全部采集完毕!')
# - 关闭数据库连接
csv_file.close()
target_util.close()
source_util.close()
metadata_util.close()
3,json订单数据采集order_json_service.py
"""
1. 获取后台访问日志文件夹下面有哪些日志文件
2. 查询元数据库表中已经被采集的日志文件,来对比确定要采集新的访问日志文件
- 创建元数据库连接
- 获取已经被采集的日志文件
- 对比确定要采集的日志文件
3. 针对待采集的新访问日志文件,进行数据采集(ETL操作->mysql->csv)
- 创建目标csv文件
- 向csv文件中写入标头
- 创建目标数据库连接
- 检查目标数据库书否存在,不存在则创建
- 遍历要采集的日志文件
- 遍历每一行数据,生成模型对象
- 写入到数据库中
- 写入到csv文件中
4. 将本次采集的访问日志文件,记录到元数据库的表中
"""
# 0. 导包
import time
from util import file_util
from util import mysql_util
from util import logging_util
from config import project_config as conf
from model.backend_logs_model import BackendLogsModel
# 日志1: 创建日志对象
logger = logging_util.init_logger()
# 日志2: 记录日志采集开始
logger.info('日志采集开始....')
# 1. 获取后台访问日志文件夹下面有哪些日志文件(file_util)
all_file_list = file_util.get_dir_files_list(conf.backend_logs_data_root_path)
# 2. 查询元数据库表中已经被采集的日志文件,来对比确定要采集新的访问日志文件
# 2.1 创建元数据库连接(mysql_util)
metadata_util = mysql_util.get_mysql_util(
host=conf.metadata_host,
port=conf.metadata_port,
user=conf.metadata_user,
password=conf.metadata_password
)
# 2.2 获取已经被采集的日志文件(mysql_util)
processed_file_list = mysql_util.get_processed_files(
util=metadata_util,
db_name=conf.metadata_db,
tb_name=conf.logs_monitor_meta_table_name,
tb_cols=conf.logs_monitor_meta_table_create_cols
)
# 2.3 对比确定要采集的日志文件(file_util)
new_file_list = file_util.get_new_by_compare_lists(processed_file_list, all_file_list)
# 日志3: 记录采集的新文件有哪些
if not new_file_list:
logger.info('没有待采集文件,所有文件已经采集完成,退出程序...')
exit('日志采集结束...')
else:
logger.info(f'待采集的文件有{new_file_list}...')
# 3. 针对待采集的新访问日志文件,进行数据采集(ETL操作->mysql->csv)
# 3.1 创建目标csv文件
csv_file = open(conf.logs_output_csv_root_path + conf.logs_output_csv_file_name,
'a',
encoding='utf8')
# 3.2 向csv文件中写入标头
csv_file.write(BackendLogsModel.generate_csv_header())
# 3.3 创建目标数据库连接
target_util = mysql_util.get_mysql_util(
host=conf.metadata_host,
port=conf.metadata_port,
user=conf.metadata_user,
password=conf.metadata_password
)
# 3.4 检查目标数据库书否存在,不存在则创建
target_util.check_table_exists_and_create(
db_name=conf.metadata_db,
tb_name=conf.target_logs_table_name,
tb_cols=conf.target_logs_table_create_cols
)
# 日志4: 记录采集开始时间
start_time = time.time()
# 3.5 遍历要采集的日志文件(从2.3步获取的new_file_list)
for file_path in new_file_list:
# 事务1: 开启事务
target_util.begin_transaction()
row_total = 0
try:
# 3.6 遍历每一行数据,
for row_content in open(file_path, 'r', encoding='utf8'):
# 3.6.1 生成模型对象
backend_log_model = BackendLogsModel(row_content)
# 3.6.2写入到数据库中
target_util.insert_single_sql_without_commit(backend_log_model.generate_insert_sql())
# 3.6.3写入到csv文件中
csv_file.write(backend_log_model.gender_csv_str())
row_total += 1
except Exception as e:
# 事务2: 事务回滚
# log日志一般是按照时间排序的,所以如果出现回滚回滚后会结束 程序
target_util.rollback_transaction()
else:
# 事务3: 一个文件处理完成后提交事务
target_util.commit_transaction()
# 4. 将本次采集的访问日志文件,记录到元数据库的表中
# 4.1 创建sql语句
sql = f'insert into {conf.logs_monitor_meta_table_name}(' \
f'file_name, process_lines) values' \
f'("{file_path}","{row_total}");'
# 4.2 执行sql语句记录到元数据库中
metadata_util.insert_single_sql(sql)
# 日志5: 记录结束时间
end_time = time.time()
# 日志6: 记录日志,说明采集用时
logger.info(f'此次采集共采集了{len(new_file_list)}个文件, 共用时{end_time-start_time}s')
# 3.7 关闭csv文件
csv_file.close()
# 3.8 关闭数据库连接
target_util.close()
metadata_util.close()
















 378
378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











