






2.1 网页文档结构
1、文档基本结构
一个HTML文件最基本的文档结构,是由文档里的<html>、<head>、<title>、<body>等标签按照特定的顺序构成的。如:
<html>
<head>
<title>网页都应有标题</title>
</head>
<body>
网页的主体内容写在这里,将会在浏览器中显示。
</body>
</html>
2、语法规范
HTML自首次发布至今,经历过几次修改,在这个过程当中产生了两个具有代表性的版本,它们分别是HTML4.01和XHTML1.0。这两个版本的语法规范是不一样的,为了保证浏览器能够使用正确的语法规范解析HTML文档,需要在HTML文档中通过<!DOCTYPE>指明当前文档所采用的版本规范,如下图所示。

以上的写法不需要记忆,可借助开发工具实现,我们只要能明白其不同的写法所表达的含义就行。
综合上述两点,一个完整的HTML结构如下:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" >
<head>
<meta http-equiv="Content-Type" content="text/html;charset=utf-8">
<title>HTML网页基本结构</title>
</head>
<body>
这是包含<!DOCTYPE >定义的完整HTML网页基本结构。
</body>
</html>
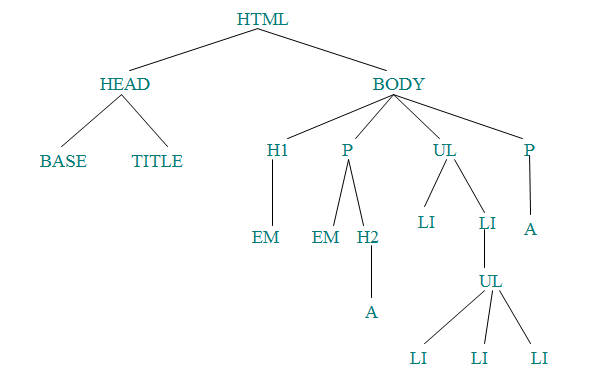
3、DOM模型
DOM模型即文档对象模型(Document Object Model)。它就是将一个HTML文档看成一棵由标签组成的如下图所示的树形结构。图中的每个结点都可以看作一个对象,它们的层次关系表示标签在网页中的嵌套关系,同一层结点的左右次序表示这些标签对象出现的先后顺序。
该模型在我们访问网页当中的标签元素时十分有用。















 3214
3214











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









