







nutch现可分为三个版本:
1.2 资料相对多一些,apache发布的有搜索模块,nutch-1.2.war,主要是早期做的是搜索引擎。
1.6、2.1后两个版本主要放在网络爬虫上面,没有war包,相对以前版本也没有crawl-urlfilter.txt文件,所以搜到以前的资料配置这个文件不要纠结了,新版本只需要配置regex-urlfilter.txt代替原来配置crawl-urlfilter.txt的作用。
nutch用的是linux/unix脚本命令,所以对于我们这些linux菜鸟,在windows上面需要安装Cygwin进行模拟。这个安装从网上搜索教程,不会出现什么问题,容易成功。
在nutch官网上面只有1.6与2.1不同平台上面的版本了,下载windows平台即.zip包,bin和src。与以前版本不同的是:1.5.1及其升级版1.6所依赖采用ivy也就是没有lib的jar包,从src包lib文件夹中就可以看出来。
这里先用cygwin进如到nutch解压之后的路径:cd nutch解压存放的路径 执行bin/nutch命令看看是否正常(在bin目录下面就有nutch的脚本)
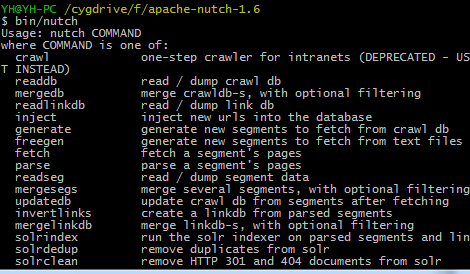
如上情况正常显示。
把nutch1.6解压之后,进入到cof目录下,这个目录下有3个主要的配置文件:nutch-default.xml、nutch-site.xml、regex-urlfilter.xml。
nutch-default.xml是默认配置这个配置文件的阅读是提高对nutch认识和理解的重点,当然也需要结合源代码进行阅读。我们主要现在是需要找到<name>http.agent.name</name>
<value></value>
这里的value值不能为空,可以随便设置。否则后面运行时会报错。而还有一个
<name>plugin.folders</name>
<value>plugins</value>
默认如上所示,这是nutch的插件目录(nutch使用插件),如果你修改了目录结构才需要重新配置,否则默认就可以,你可以看解压的nutch的目录结构它本身就是放在plugins目录下面的。当时配置这个的时候不清楚看许多文章上面说修改这个配置,特此说明一下。
nutch-site.xml默认为空,它里面的配置可以覆盖nutch-default.xml里面的配置,所以我们可以在里面加上:
<property>
<name>http.agent.name</name>
<value>My Nutch Spider</value>
</property>
这样的配置项,覆盖原来nutch-default.xml中的这一配置项,也就是说nutch-default.xml里面不用做任何修改。上面My Nutch Spider可以取任意内容。
regex-urlfilter.xml里面使用正则表达式进行对搜索url的限制过滤,在文件最后面+.修改为+^http://([a-z0-9]*\.)*或者自己定义其他的表达式都行。
接下来进行爬虫,上面我们在执行bin/nutch出现的界面上,出现很多提示,这是需要仔细阅读的地方,它的第一个命令crawl,也就是在bin目录下看到的crawl脚本,它也是抓取的一个主函数java类,启动它需要附加一些参数:我们这时候就直接在里面输入:bin/nutch crawl 会出现提示信息:
Usage: Crawl <urlDir> -solr <solrURL> [-dir d] [-threads n] [-depth i] [-topN N]
如上所说Crawl是一个java类这里省略了包名,第一个参数是要抓取的种子目录,我们可以在nutch解压的目录下面建立一个url目录在里面新建url.txt里面可以输入一个或多个url地址,每个地址一行,如http://www.sina.com.cn/
第二个参数是solr的url这个暂时可以不用,接着需要的是抓取结果存放的目录,之后分别是threads线程数,depth,topN这些具体作用暂时不做了解,只需要知道其值越大,抓取结果越多,当然耗时越长
了解之后:测试输入:bin/nutch crawl urls -dir data -threads 2 -depth 3 -topN 5
其中data是输出目录会自动生成在nutch目录下。这里注意一下你在regex-urlfilter.xml配置的正则表达式会不会过滤掉你在url.txt中输入的地址,如果直接过滤掉了就不会有结果了。这里只是测试,所以参数值给的比较小。
运行终止之后data中会产生三个文件夹,crawldb、linkdb、segments较之之前版本没有索引文件夹。
三个文件夹的具体内容再做分析,这里到此已安装nutch成功。
在myeclipse上面的部署:
1.建立java工程:把src源码包解压后的:apache-nutch-1.6\src\java下的org文件夹拷到java工程src目录下。
2.把bin解压目录下面的conf lib plugins目录也拷到src目录下。
3.把本工程的lib下面的包添加到类路径下,或者直接把依赖jar包从外面文件夹中加进去,这个和其它工程一样。其中的hadoop-core-1.0.3.jar需要替换这里网上搜一个是有的。
4.把conf创建成source folder,右击build path-》use as a source folder
5.在src下面建立urls目录,里面建立url.txt 和安装时一样步骤
6.nutch-default.xml、nutch-site.xml、regex-urlfilter.xml配置和安装时一样配置,注意的地方也一样。
7.打开那个上面提到的类Crawl进行run as -》run configurations Arguments(参数设定)
crawl urls/urls.txt -dir urls/out -depth 10 -topN 10000 参数和上面安装时一样
内存大点:-Xms800m -Xmx800m
然后run开始抓取,当然出现错误就检查那几个配置文件,jar包是否导入(不要报错),产看日志文件,在工程下面有hadoop文件里面有详细运行过程。
其中有许多细节需要探讨。另外后期对抓取数据的查看处理,可以用solr查看。其配置再述。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









