







1.对于中文分词的了解:对于中文缺少词的明确划分,大多的词是双字或者多字,拉丁语系的词就天然的是空格划分,一句话若干个单词,汉语一句话分词就没有明显的界限,需要人为主观判断,而且各不相同。
2.使用IK进行中文分词,操作简单,而且可扩展自己的分词词库。
3.首先加入IKAnalyzer的jar包,可以直接在apache-solr-3.6.2\example\solr下建立lib,放在lib下;
4.配置 schema.xml文件
在schema.xml主要配置了以下内容:fieldType和fields。其中,fieldType是用来配置各种fieldType的类型的,fields则是配置建索引的每个域的名字,是否分词,是否存储的。
首先配置:
<fieldType name="text_zh" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.solr.IKTokenizerFactory" useSmart="false" />
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.solr.IKTokenizerFactory" useSmart="false" />
</analyzer>
</fieldType>
再配置:(这里是以content内容来检索分词的)
<field name="content" type="text_zh" stored="true" indexed="true"/>
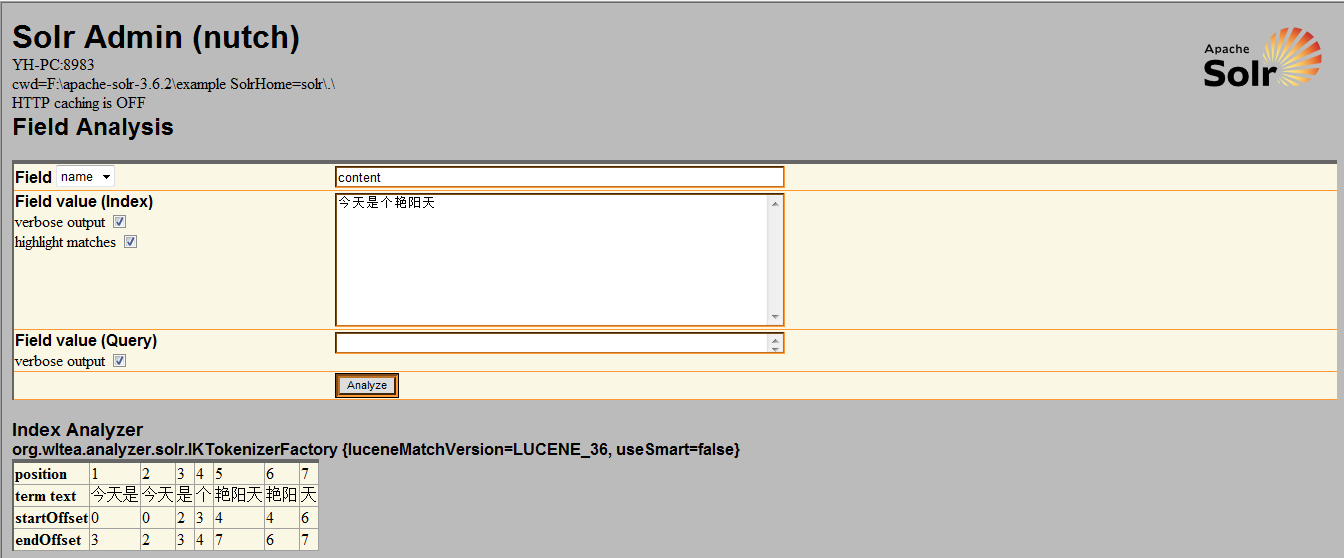
5.启动solr,到http://localhost:8983/solr/admin/analysis.jsp,如果是tomcat为http://localhost:8080/solr/admin/analysis.jsp















 4987
4987











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









