







CONNON 算法mpi实现
工程中面对大型矩阵相乘,单机的内存和运行速度都受到限制时,我们有必要对矩阵进行并行处理,常见的并行方法有矩阵按行分解按列分解以及按块分解,按行列分解虽然简单,但是它的可扩展性差,n乘以n的方阵,通信量为O(N),此时按块分解的办法,通信量只有O(sqrt(N)),加农算法正是基于此
问题:假设矩阵有 AB=C,输入为A和B,求C
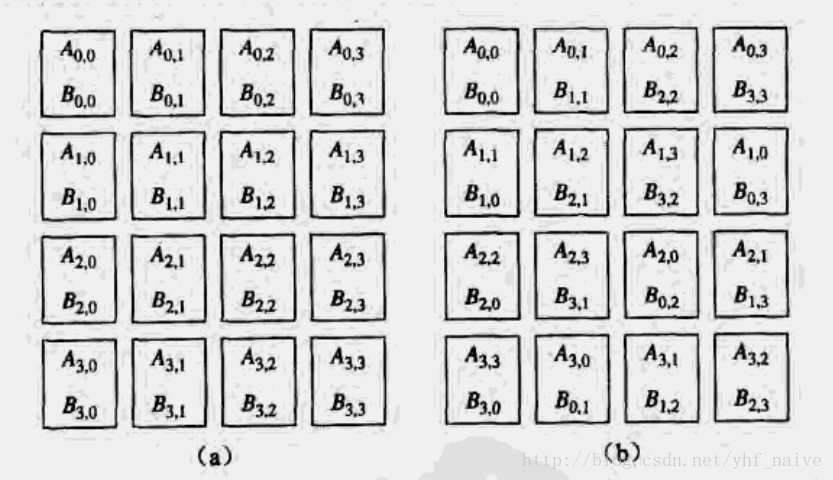
- 加农算法示意图
左图为A和B的分解方式,右图的组合是为了让A小块的后一个下标和B小块的前一个下标相等,有利于相乘。每次计算时,每个单核计算一小块内的矩阵相乘,计算完成后,所有的A小块左移一块,最左边到最右边,所有的B小块上移一块,保证下标仍然有对应关系,在求乘积并于原结果相乘。以此类推求得4次即得到最终的结果,本文还配合的openmp用以加速,经测试4核计算1000*1000的矩阵比朴素计算有3倍左右的加速效果
C++源码:
/**
*矩阵乘以矩阵MMM(MatrixMatrixMultiplying)
*分块运算 目前只能运算方阵乘以方阵
*问题:
*1.额外内存问题
*2.如何高效输出文件
*3.一个section内如何实现多线程?例如section内有for
*
*author:yhf
*2017.6.19于图书馆
**/
#include<stdio.h>
#include<string.h>
#include<iostream>
#include<cmath>
#include<algorithm>
#include "mpi.h"
#include<fstream>
#define size 360//Matrixsize*Matrixsize
//#define SECTION
using namespace std;
class MMM{
public:
double *A,*A1;
double *B,*B1;
double *C;
int row;
int numpro;
int myid;
int numprorow;
MMM(int Row,int numprocs,int myrank){
if(int(sqrt(numprocs))*int(sqrt(numprocs))!=numprocs||\
Row%(int(sqrt(numprocs)))!=0){
cout<<"error numprocs"<<endl;
MPI_Abort(MPI_COMM_WORLD,1);
}
myid=myrank;numpro=numprocs;row=Row;numprorow=int(sqrt(numprocs));
B=new double[row*row/numprocs];
A=new double[row*row/numprocs];
/*extra memmory for store the data without comflict*/
B1=new double[row*row/numprocs];
A1=new double[row*row/numprocs];
C=new double[row*row/numprocs];//output matrix
ifstream finb("A.dat");
ifstream fina("B.dat");
if(!fina||!finb){
cout<<"can not open a file ";
MPI_Abort(MPI_COMM_WORLD,1);
}
int t1=0,t2=0,myrank1;double t4;
/*myrank1 is a map the current rank into the rank in Cannon algorithm */
myrank1=(numpro+myrank-(myrank%numprorow)*numprorow)%numpro;
int t3=(myrank1/numprorow)*(row*row/numprorow)+(myrank1%numprorow)*(row/numprorow);
while(t3--)
fina>>t4;
for(int i=0;i<row/numprorow;i++){
for(int j=0;j<row/numprorow;j++){
fina>>B[t1++];
}
t3=row-row/numprorow;
while(t3--)
fina>>t4;
}
fina.close();
myrank1=numprorow*(myrank/numprorow)+(numprorow+myrank%numprorow-myrank/numprorow)%numprorow;
t3=((myrank1)/numprorow)*(row*row/numprorow)+(myrank1%numprorow)*(row/numprorow);
while(t3--)
finb>>t4;
for(int i=0;i<row/numprorow;i++){
for(int j=0;j<row/numprorow;j++){
C[t2]=0;
finb>>A[t2++];
}
t3=row-row/numprorow;
while(t3--)
finb>>t4;
}
finb.close();
}
/*compute funtion*/
void Compute(double *A,double* B,double *A1,double *B1){
MPI_Status status;
double t1,t2,t3,t4;
t1=MPI_Wtime();
#ifndef SECTION
#pragma omp parallel for num_threads(4)
#endif
for(int i=0;i<row/numprorow;i++){
for(int j=0;j<row/numprorow;j++){
for(int k=0;k<row/numprorow;k++){
C[i*(row/numprorow)+j]+=A[i*(row/numprorow)+k]*B[k*(row/numprorow)+j];
}
}
}
t2=MPI_Wtime();
t3=MPI_Wtime();
MPI_Sendrecv(B,(row*row)/numpro,MPI_DOUBLE,(myid+numpro-numprorow)%numpro,myid*10+1,B1,(row*row)/numpro,MPI_DOUBLE,(myid+numprorow)%numpro,(myid+numprorow)%numpro*10+1,MPI_COMM_WORLD,&status);
int left=myid-1;int right=myid+1;
if((left/numprorow!=myid/numprorow)||left==-1)
left+=numprorow;
if(right/numprorow!=myid/numprorow)
right-=numprorow;
MPI_Sendrecv(A,(row*row)/numpro,MPI_DOUBLE,left,myid*10+0,A1,(row*row)/numpro,MPI_DOUBLE,right,right*10+0,MPI_COMM_WORLD,&status);
t4=MPI_Wtime();
/*
for(int j=0;j<(row*row)/numpro;j++){
A[j]=A1[j];
B[j]=B1[j];
}
*/
if(myid==0){
cout<<"section1:"<<t2-t1<<endl<<"section2:"<<t4-t3<<endl;
}
}
void output(){
if(myid==0){
/*initial the output file */
ofstream fclear("answer.dat");
if(!fclear){
cout<<"can not open a write file";
exit(1);
}
fclear.close();
}
MPI_Barrier(MPI_COMM_WORLD);
for(int i=0;i<numprorow*row;i++){
if(myid==(i%numprorow)+numprorow*(i/(row))){
ofstream fout("answer.dat",ios::app);
if(!fout){
cout<<"error occur when writing a file";
exit(1);
}
for(int j=0;j<row/numprorow;j++){
fout<<C[j+(row/numprorow)*(i%(row)/(numprorow))]<<" ";
}
if((i+1)%numprorow==0)
fout<<endl;
fout.close();
}
MPI_Barrier(MPI_COMM_WORLD);
}
}
};
int main(int argc,char ** argv){
int myid, numprocs;
double START,END;
int namelen;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
MPI_Comm_size(MPI_COMM_WORLD, &numprocs);
MMM obj(size,numprocs,myid);
START=MPI_Wtime();
for(int h=0;h<obj.numprorow;h++){
if(h%2==0)
obj.Compute(obj.A,obj.B,obj.A1,obj.B1);
else
obj.Compute(obj.A1,obj.B1,obj.A,obj.B);
}
END=MPI_Wtime();
#ifdef _DEBUG
for(int i=0;i<obj.numpro;i++){
if(myid==i){
cout<<endl<<"procs:"<<i<<":"<<endl;
for(int j=0;j<obj.row/obj.numprorow;j++){
cout<<endl;
for(int k=0;k<obj.row/obj.numprorow;k++){
cout<<obj.C[obj.row/obj.numprorow+k]<<" ";
}
}
}
MPI_Barrier(MPI_COMM_WORLD);
}
#endif
if(myid==0){
cout<<"time:"<<END-START<<endl;
}
obj.output();
MPI_Finalize();
return 0;
}















 2590
2590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









