









http://www.cnblogs.com/devinzhang/archive/2012/01/13/2321481.html
1. HashMap
1) hashmap的数据结构
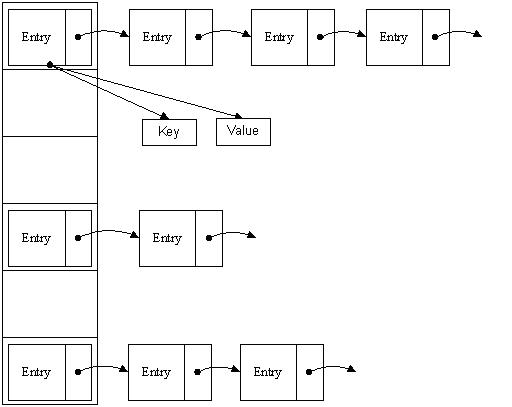
Hashmap是一个数组和链表的结合体(在数据结构称“链表散列“),如下图示:

当我们往hashmap中put元素的时候,先根据key的hash值得到这个元素在数组中的位置(即下标),然后就可以把这个元素放到对应的位置中了。如果这个元素所在的位子上已经存放有其他元素了,那么在同一个位子上的元素将以链表的形式存放,新加入的放在链头,最先加入的放在链尾。
2)使用

Map map = new HashMap(); map.put("Rajib Sarma","100"); map.put("Rajib Sarma","200");//The value "100" is replaced by "200". map.put("Sazid Ahmed","200"); Iterator iter = map.entrySet().iterator(); while (iter.hasNext()) { Map.Entry entry = (Map.Entry) iter.next(); Object key = entry.getKey(); Object val = entry.getValue(); }
2. HashTable和HashMap区别
第一,继承不同。
public class Hashtable extends Dictionary implements Map public class HashMap extends AbstractMap implements Map
第二
Hashtable 中的方法是同步的,而HashMap中的方法在缺省情况下是非同步的。在多线程并发的环境下,可以直接使用Hashtable,但是要使用HashMap的话就要自己增加同步处理了。
第三
Hashtable中,key和value都不允许出现null值。
在HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。当get()方法返回null值时,即可以表示 HashMap中没有该键,也可以表示该键所对应的值为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个键, 而应该用containsKey()方法来判断。
第四,两个遍历方式的内部实现上不同。
Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。
第五
哈希值的使用不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值。
第六
Hashtable和HashMap它们两个内部实现方式的数组的初始大小和扩容的方式。HashTable中hash数组默认大小是11,增加的方式是 old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数。
http://www.cnblogs.com/carbs/archive/2012/07/04/2576995.html
|
|
Hashtable
|
HashMap
|
|
并发操作
|
使用同步机制,
实际应用程序中,仅仅是Hashtable本身的同步并不能保证程序在并发操作下的正确性,需要高层次的并发保护。
下面的代码试图在key所对应的value值等于x的情况下修改value为x+1
{
value = hashTable.get(key);
if(value.intValue()== x){
hashTable.put(key, new Integer(value.intValue()+1));
}
}
如2个线程同时执行以上代码,可能放入不是x+1,而是x+2.
|
没有同步机制,需要使用者自己进行并发访问控制
|
|
数据遍历的方式
|
Iterator 和 Enumeration
|
Iterator
|
|
是否支持fast-fail
|
用Iterator遍历,支持fast-fail
用Enumeration不支持fast-fail.
|
支持fast-fail
|
|
是否接受值为null的Key 或Value?
|
不接受
|
接受
|
|
根据hash值计算数组下标的算法
|
当数组长度较小,并且Key的hash值低位数值分散不均匀时,不同的hash值计算得到相同下标值的几率较高
hash = key.hashCode();
index=(hash&0x7FFFFFFF) % tab.length;
|
优于hashtable,通过对Key的hash做移位运算和位的与运算,使其能更广泛地分散到数组的不同位置
hash = hash (k);
index = indexFor(hash, table.length);
static int hash(Object x) {
int h = x.hashCode();
h += ~(h << 9);
h ^= (h >>> 14);
h += (h << 4);
h ^= (h >>> 10);
return h;
}
static int indexFor(int h, int length) {
return h & (length-1);
}
|
|
Entry数组的长度
|
Ø
缺省初始长度为11,
Ø
初始化时可以指定initial capacity
|
Ø
缺省初始长度为16,
Ø
长度始终保持2的n次方
Ø
初始化时可以指定initial capacity,若不是2的次方,HashMap将选取第一个大于initial capacity 的2n次方值作为其初始长度
|
|
LoadFactor负荷因子
|
0.75
| |
|
负荷超过(loadFactor * 数组长度)时,内部数据的调整方式
|
扩展数组:2*原数组长度+1
|
扩展数组: 原数组长度 * 2
|
|
两者都会重新根据Key的hash值计算其在数组中的新位置,重新放置。算法相似,时间、空间效率相同
| ||















 1277
1277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









