






目录
一.创建文件
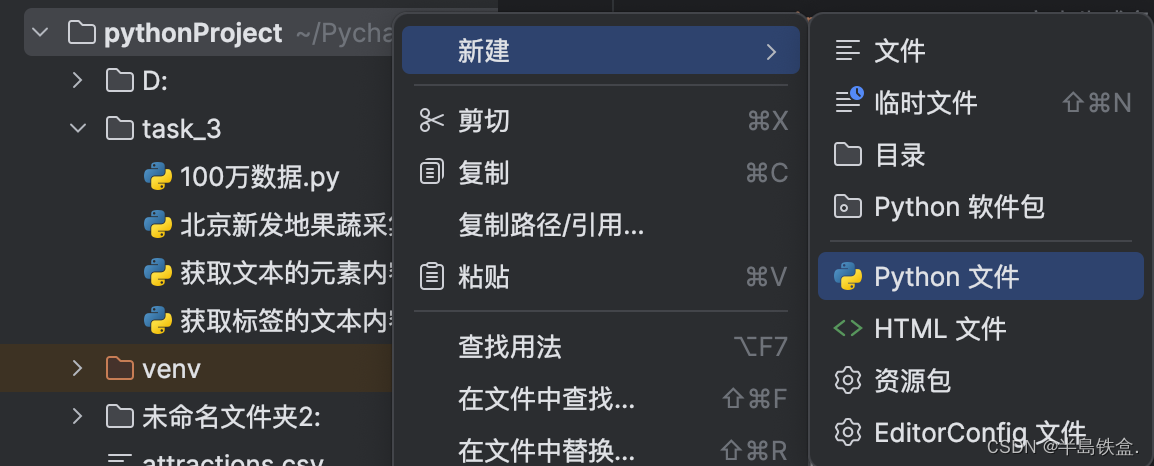
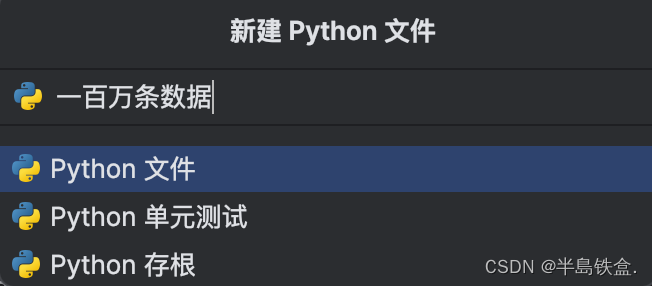
1.打开pyCharm创建python文件
二.编写代码
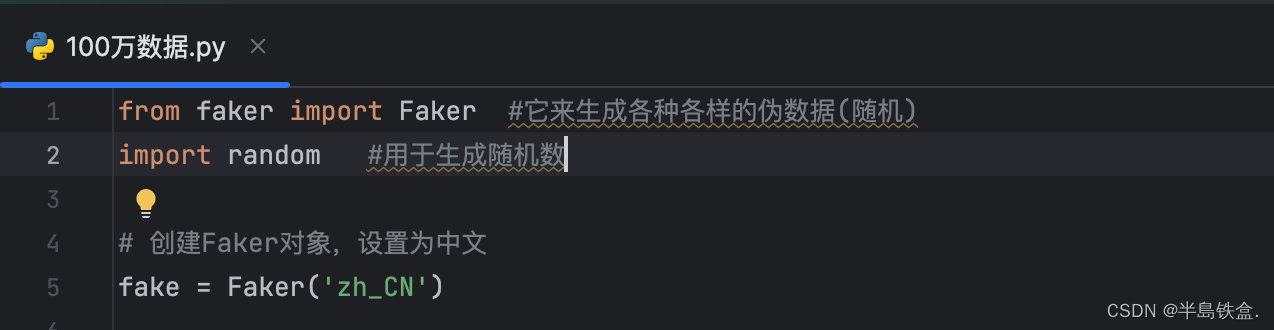
1.创建Faker对象,设置为中文,需要安装faker软件包。
pip install fakerfrom faker import Faker #它来生成各种各样的伪数据(随机)
fake = Faker('zh_CN')
2.生成的数据行数,也就是我们的一百万条数据,一百万行方便用表格表示。
num_rows = 1000000
3.定义我们想要的数据,我这里是学历,前面的英语单词也必须是学历的英语单词,也可以改为其他数据,有中文就要有它的英文。
education = ["小学学历", "初中学历", "高中学历", "专科学历", "本科学历", "硕士学历", "博士学历"]
4.打开文件用于写入数据,使用Python在UTF-8编码的写入模式(“'w'”)中打开一个名为“data.csv”的文件。然后,为包含CSV文件列名的文件写一行标题:“姓名”、“年龄”、“性别”和“学历”。
with open('data.csv', 'w', encoding='utf-8') as file:
# 写入CSV文件头
file.write('姓名,年龄,性别,学历\n')
5.生成并写入数据,
fake.name():使用一些库(可能是faker或类似)来生成一个随机的中文名称。
random.randint(18, 99):产生18至99岁的随机年龄。
random.choice(['男', '女']):随机选择“男”(男性)或“女”(女性)作为性别。
random.choice(education):从education列表中随机选择一个教育级别。假education列表在您的代码中的某个地方定义。
file.write(f'{name},{age},{gender},{education1}\n'):将生成的数据以逗号分隔行写入CSV文件。循环的每个迭代都会为文件添加一行新行。
因此,在运行此循环num_rows次后,您的CSV文件将包含随机生成的数据行,每行数据都带有中文名称、年龄、性别和学历。
注意:在运行此代码之前,请务必导入必要的的库(fake和random)并定义education列表。此外,您提供的代码片段中的缩进似乎不一致,这可能会导致缩进错误。确保实际代码中的正确缩进。
for _ in range(num_rows):
# 随机生成中文姓名、年龄、性别和学历
name = fake.name()
age = random.randint(18, 99) # 假设年龄在18到99之间
gender = random.choice(['男', '女']) # 随机选择性别
education1 = random.choice(education) # 随机选择学历
# 将数据写入CSV文件
file.write(f'{name},{age},{gender},{education1}\n')

6.最后打印出来。
















 6070
6070











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









