







博主介绍:java高级开发,从事互联网行业六年,熟悉各种主流语言,精通java、python、php、爬虫、web开发,已经做了多年的设计程序开发,开发过上千套设计程序,没有什么华丽的语言,只有实实在在的写点程序。
🍅文末点击卡片获取联系🍅
技术:python+sqlite+html+协同过滤
1 研究背景
汽车数据可视化、推荐及预测系统的研究源于对汽车行业发展和用户需求的深入理解,以及对大数据分析和人工智能技术在汽车领域应用的探索。这一研究背景主要包括以下几个方面:
1. 汽车产业发展趋势:随着汽车产业向智能化、互联化方向发展,汽车制造商和服务提供商积累了大量与汽车相关的数据,包括车辆性能数据、用户行为数据、销售数据等。如何充分利用这些数据,为用户提供更好的汽车产品和服务,成为当前汽车行业的重要课题。
2. 用户个性化需求:消费者对汽车的需求日益多样化和个性化,他们希望能够通过数据分析和推荐系统找到最适合自己需求的汽车产品。因此,汽车数据可视化、推荐及预测系统的研究应运而生,旨在通过数据分析和可视化展示,为用户提供更直观、个性化的汽车选择信息。
3. 大数据和人工智能技术发展:大数据分析和人工智能技术的快速发展为汽车数据可视化、推荐及预测系统的研究提供了技术支持。通过机器学习算法对海量汽车数据进行分析和挖掘,可以实现汽车的个性化推荐和预测,为汽车制造商和用户提供更精准的决策依据。
4. 市场竞争与用户体验:在激烈的市场竞争中,汽车制造商需要更加深入地了解用户的需求和偏好,以提高产品的市场竞争力。同时,用户体验已经成为汽车行业竞争的关键因素,汽车数据可视化、推荐及预测系统的研究将有助于提升用户体验,增强市场竞争力。
2 研究意义
汽车数据可视化、推荐及预测系统的研究具有重要的理论和实践意义,对于汽车行业的发展和用户体验的提升具有深远影响,这一研究方向有助于深入挖掘汽车大数据的潜在价值。随着智能汽车和互联汽车技术的普及,汽车制造商和服务提供商积累了大量与汽车相关的数据,包括车辆性能数据、用户行为数据、交通环境数据等。通过数据可视化、推荐及预测系统的研究,可以更好地分析和利用这些数据,挖掘出对汽车设计、生产和服务改进具有指导意义的信息,为汽车行业的发展提供新的思路和方法,研究汽车数据可视化、推荐及预测系统有助于提升用户体验和满足用户个性化需求。通过对用户行为数据和偏好的分析,结合推荐算法和预测模型,可以为用户提供个性化的汽车产品推荐和购车建议,提高用户选车的准确性和满意度。同时,基于对汽车数据的可视化展示,用户可以更直观地了解汽车的性能、特点和优缺点,从而更好地进行购车决策,提升购车体验,研究汽车数据可视化、推荐及预测系统对汽车行业的经营决策和市场营销策略具有重要的指导意义。通过对市场趋势和用户行为的分析,汽车制造商和经销商可以制定更精准的产品定位、定价和促销策略,提高市场竞争力和盈利能力。同时,汽车数据可视化也可以为消费者提供更加透明和真实的汽车信息,增强汽车行业的信誉和可持续发展。
3 相关技术
3.1 python
Python是一种高级编程语言,以简洁、清晰的语法而闻名。它被广泛应用于Web开发、数据分析、人工智能、科学计算、自动化脚本等领域。Python具有易学易用的特点,适合初学者和专业开发者使用,Python拥有丰富的标准库和第三方库,提供了丰富的工具和模块,可以满足各种开发需求。其开放源代码的特性意味着用户可以在全球范围内分享代码、学习资源和解决方案,Python语言的设计理念强调代码的可读性和简洁性,这使得它成为了一种非常适合快速开发和维护的语言。另外,Python还支持面向对象、函数式和过程式等多种编程范式,使得开发者可以根据自己的喜好和项目需求进行灵活选择,由于其强大的功能和易用性,Python已经成为了众多领域的首选开发语言,尤其在人工智能、数据科学和Web开发等领域备受青睐。总之,Python作为一种通用编程语言,具有广泛的应用前景和社区支持,为开发者提供了丰富的可能性和机会。
3.2 echarts
ECharts是一个由百度开发并维护的基于JavaScript的数据可视化库,专注于大数据可视化的展示。它提供了丰富的图表类型和交互功能,包括折线图、柱状图、散点图、饼图、地图等,以及缩放、拖拽、数据筛选等操作,能够满足各种数据展示需求,ECharts具有良好的兼容性和性能优势,可以在各种现代浏览器上运行,并支持移动端设备,能够快速响应用户操作并展现大规模数据。同时,它提供了丰富的API和扩展机制,开发者可以根据需求进行定制化开发,满足复杂的数据可视化需求,作为一款开源的数据可视化库,ECharts秉承着开放、灵活的设计理念,提供了丰富的文档和示例,为开发者提供了学习和使用的便利。与此同时,ECharts还提供了强大的社区支持和持续的更新和维护,使得它成为了众多开发者首选的数据可视化解决方案之一。
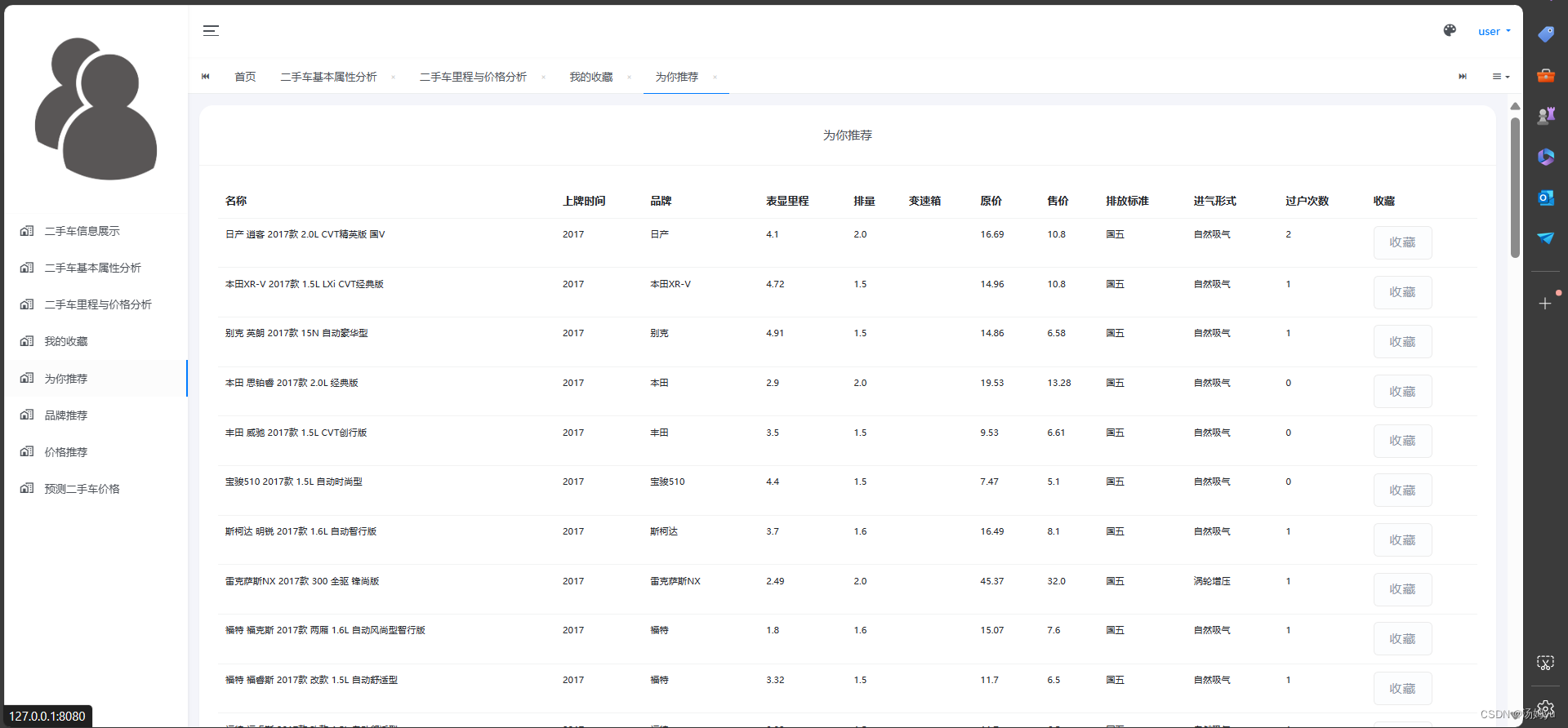
3.3 协同过滤
协同过滤是一种常用的推荐系统算法,通过分析用户行为和偏好来向用户推荐他们可能感兴趣的物品或内容。这种算法的核心思想是利用用户与物品之间的历史行为数据,发现用户的兴趣模式,从而进行个性化的推荐,协同过滤主要分为两种类型:基于用户的协同过滤和基于物品的协同过滤。基于用户的协同过滤是指根据用户对物品的评价或行为历史,找到与目标用户相似偏好的其他用户,然后向目标用户推荐这些相似用户喜欢的物品。而基于物品的协同过滤则是根据物品之间的相似度,向用户推荐与其已经喜欢的物品相似的其他物品,协同过滤算法的优势在于可以实现个性化推荐,不需要事先对物品或用户有过多的了解,只需依靠用户行为数据就可以生成推荐结果。然而,协同过滤也面临着数据稀疏性、冷启动问题和算法可扩展性等挑战,需要结合其他技术手段来解决这些问题。
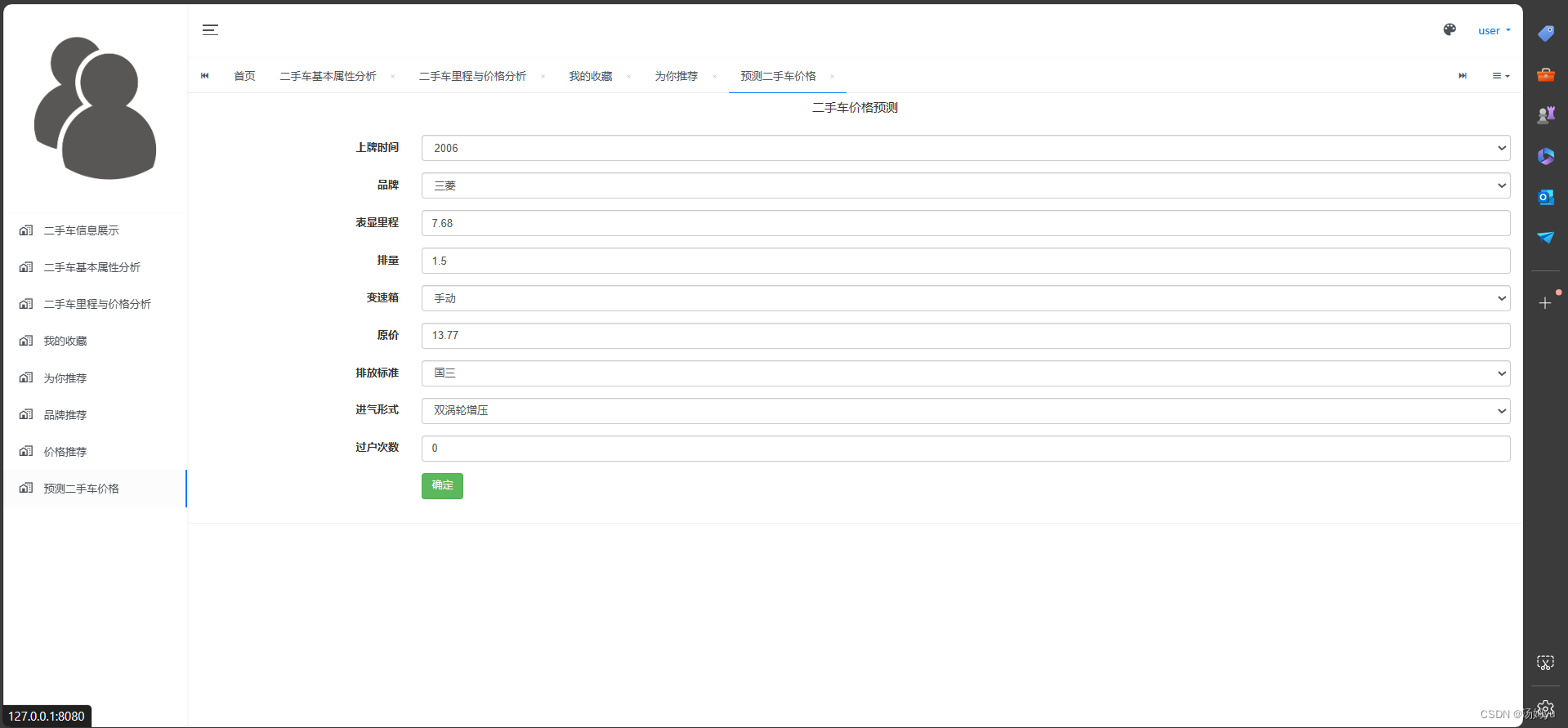
3.4随机森林回归预测
随机森林回归是一种基于决策树集成的机器学习方法,用于解决回归问题。它通过构建多个决策树,并将它们的预测结果进行平均或投票来进行预测,以提高模型的准确性和泛化能力,在随机森林回归中,首先从训练数据中随机选择一部分样本和特征,然后构建多个决策树。这些决策树相互独立,每棵树都对目标变量进行预测。最终的预测结果是所有树的预测结果的平均值,这种集成的方式能够减小单棵树的过拟合风险,提高整体模型的稳定性和准确性。随机森林回归具有许多优点,包括对高维数据和大规模数据的良好适应性、对异常值和缺失值的鲁棒性、以及不需要过多的参数调整等特点。此外,它还可以输出各个特征的重要性,帮助用户理解数据和特征之间的关系。
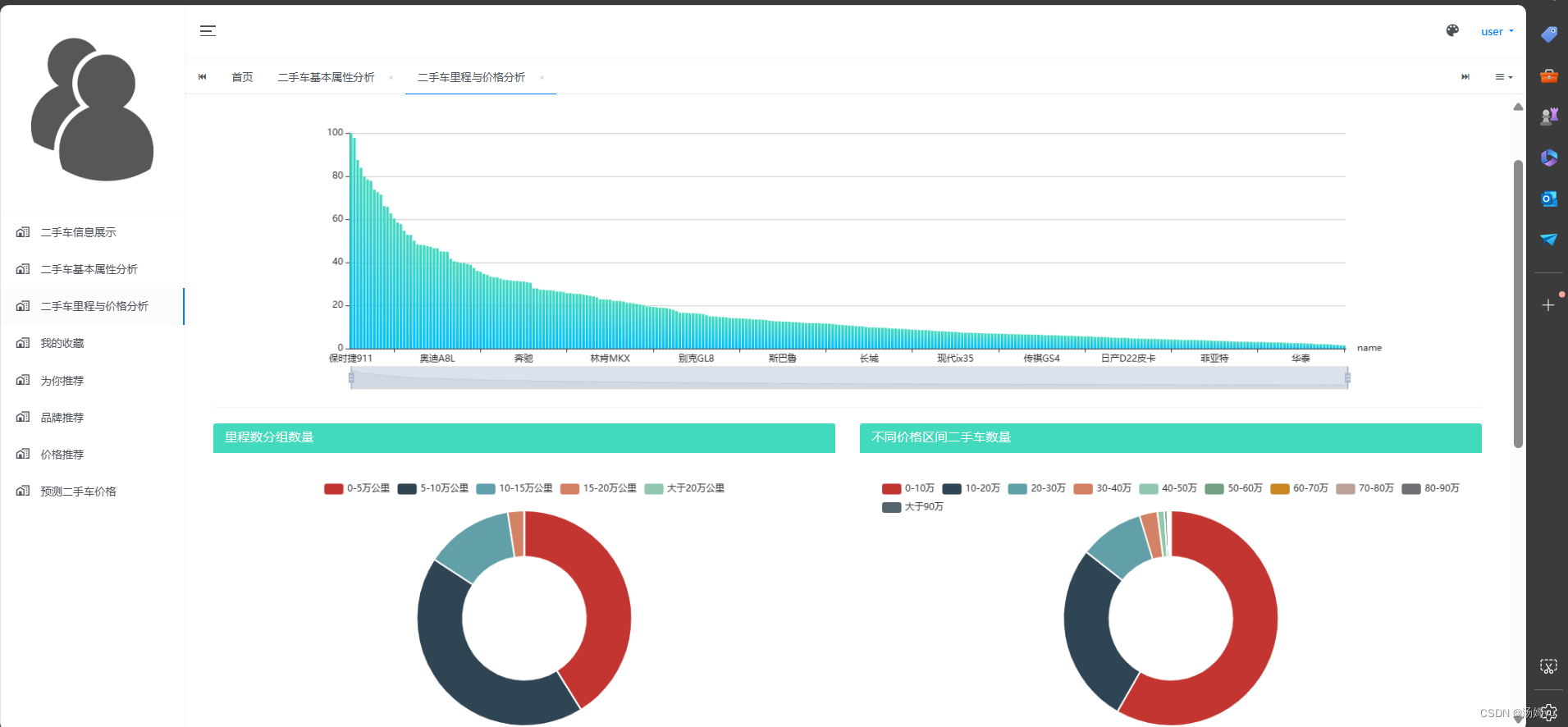
4. 功能结构图
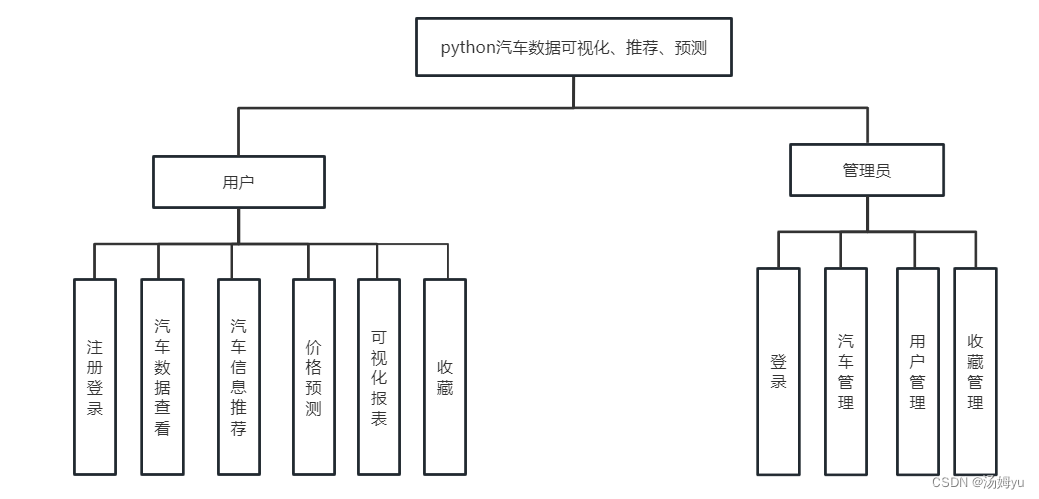
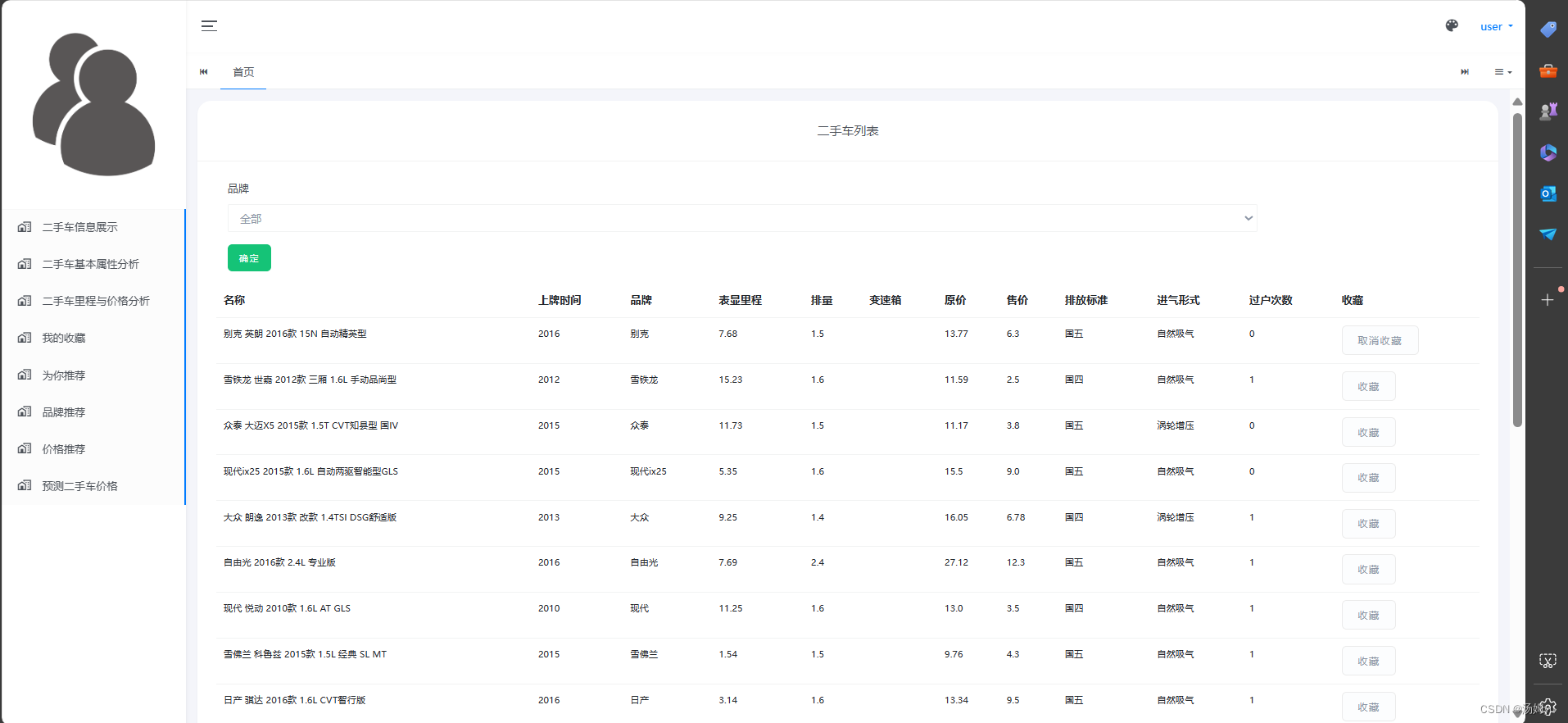
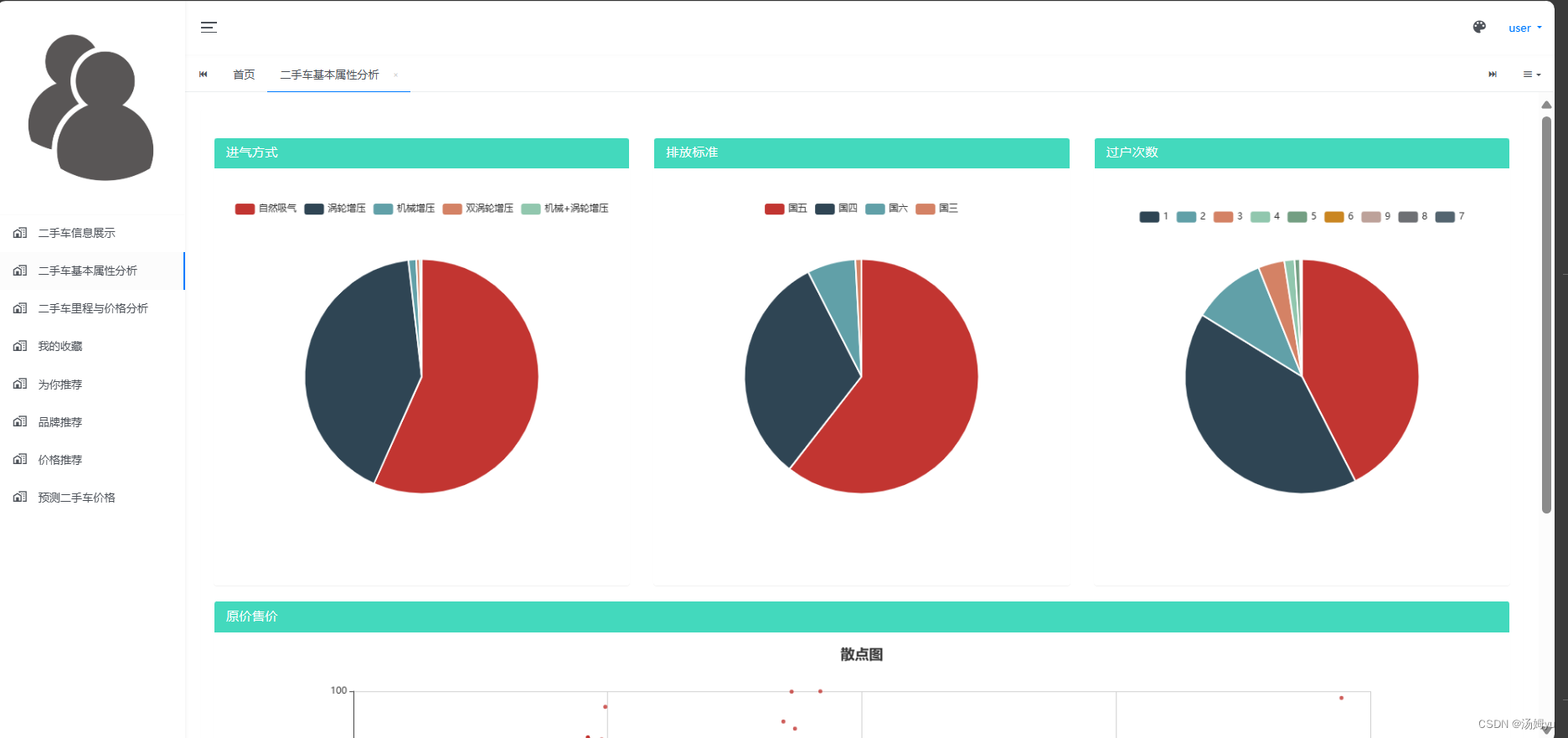
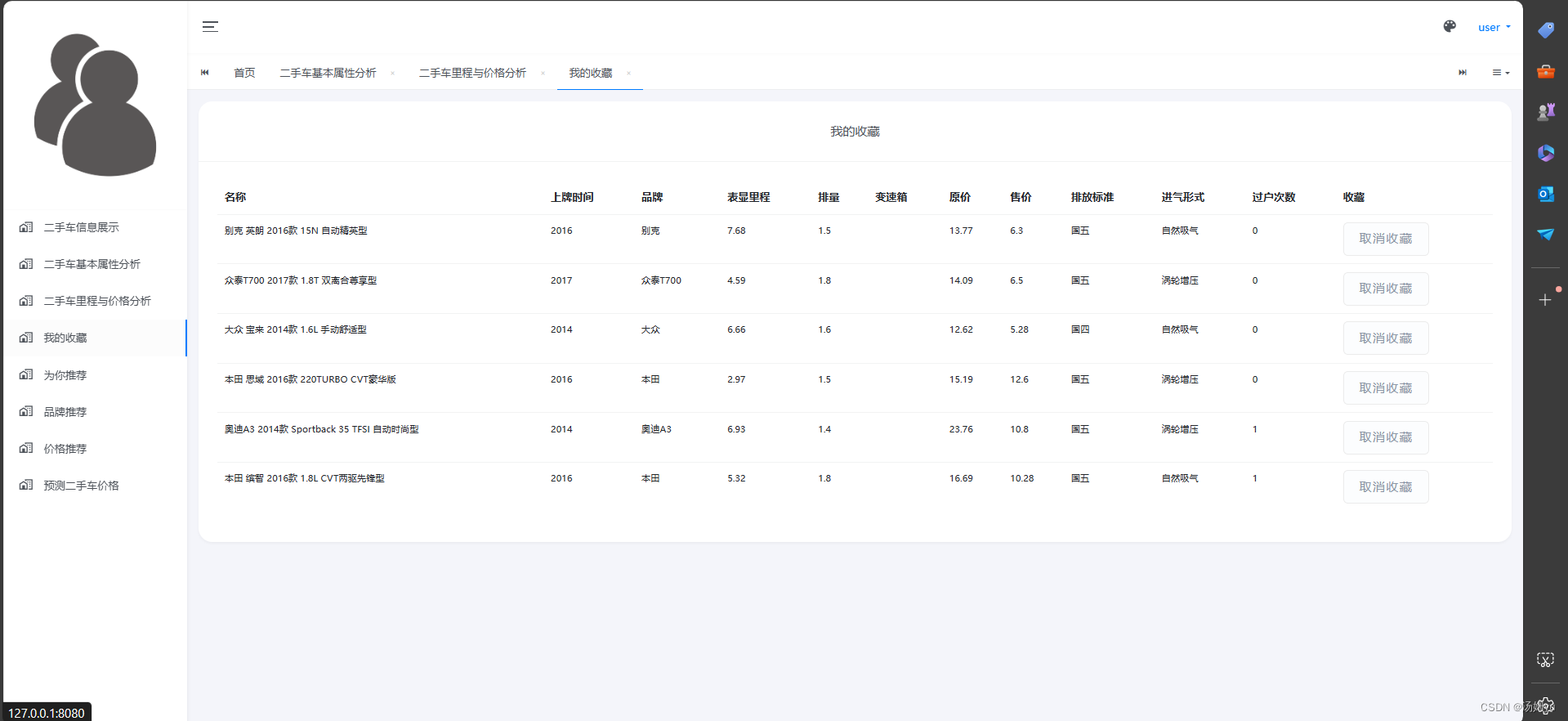
5 系统实现



















 5423
5423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











