







 本文介绍了深度监督跨模态检索(DSCMR)方法,旨在建立一个通用的表示空间,允许不同模态的数据直接比较。通过最小化鉴别损失和模态不变性损失,DSCMR在保持语义区分的同时学习模态不变特征。使用VGG-19和Word2Vec/CNN提取图像和文本特征,并通过权重共享减少跨模态差异。实验表明,DSCMR在多模态检索任务中表现出色。
本文介绍了深度监督跨模态检索(DSCMR)方法,旨在建立一个通用的表示空间,允许不同模态的数据直接比较。通过最小化鉴别损失和模态不变性损失,DSCMR在保持语义区分的同时学习模态不变特征。使用VGG-19和Word2Vec/CNN提取图像和文本特征,并通过权重共享减少跨模态差异。实验表明,DSCMR在多模态检索任务中表现出色。
一点补充
什么叫模态:每一种信息来源都可以认为是一种模态,视觉信息、听觉信息都是不同的模态。深度学习多模态融合指机器从文本、图像、语音、视频等多个领域获取信息,每一个领域就是一种模态,实现信息转换和融合,从而提升模型性能的技术,是一个典型的多学科交叉领域。
关于多模态之间的架构可以参考下这篇文章:面向深度学习的多模态融合技术研究综述,这里不过多赘述
一、论文部分
跨模式检索旨在实现跨不同模式的灵活检索。跨模式检索的核心是如何衡量不同类型数据之间的内容相似性。在本文中提出了一种新颖的跨模式检索方法,称为深度监督跨模式检索(Deep Supervised Cross-modal Retrieval, DSCMR)。它旨在找到一个通用的表示空间,在其中可以直接比较来自不同模态的样本。具体来说,DSCMR最小化了标签空间和公共表示空间中的鉴别损失( discrimination loss),以及监督模型学习的判别特征。此外,它同时最小化模态不变性损失( modality invariance loss),并使用权重共享策略消除公共表示空间中多媒体数据的跨模态差异,以学习模态不变特征。在四个广泛使用的基准数据集上的综合实验结果表明,该方法在交叉模式学习中有效,并且明显优于最新的交叉模式检索方法。
解决问题:
在不同模态下,样本可以生成可以直接比较的公共表示空间。不仅保证了公共空间各模态数据与标签的相似性,而且保证了语义区分和公共空间模态的不变性,可以有效地学习异构数据的公共表示。
主要思想:
VGG-19提取图像特征,Word2Vec,CNN提取文本特征,创建线性分类器对样本生成标签,在标签空间和公共表示空间下最小化区别损失,同时,最小化两种模态在公共表示空间中所有样本的识别损失来学习多模态不变特征,为了消除跨模态数据差异,将所有图像到文本对之间的表示距离最小化。
创新点:
- 提出了一个监督的跨模态学习结构作为不同模态的桥梁,以弥补不同模式间的异质性。它可以通过通过端到端的方式,同时保留语义的区分性和模态的不变性,可以有效地学习异构数据的公共表示。。
- 在最后一层开发了两个具有权重共享约束的子网,以学习图像和文本模态之间的交叉模态相关性。 此外,将模态不变性损失直接计算到目标函数中,消除了模态间的差异。
- 应用线性分类器对公共表示空间中的样本进行分类。 这样,DSCM-R 最大限度地减少了标签空间和公共表示空间中的辨别损失,从而使学习到的公共表示具有显着性。
模型:
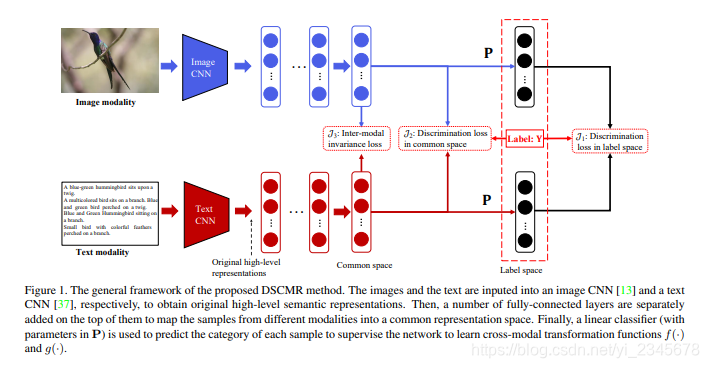
- 包括两个子网络——一个是图像模态,另一个是文本模态,端到端训练
- 对于图像:利用预训练在 ImageNet 的网络提取出图像的 4096 维的特征作为原始的图像高级语义表达。然后后续是几个全连接层,来得到图像在公共空间中的表达。
- 对于文本:利用预训练在 Google News 上的 Word2Vec 模型,来得到 k 维的特征向量。一个句子可以表示为一个矩阵,然后使用一个 Text CNN 来得到原始的句子高级语义表达。之后也是同样的形式,后面是几个全连接层来得到句子在公共空间中的表达。
- 第二层以后的全连接是参数共享的。
- 为了确保两个子网络能够为图像和文本学到公共的表达,我们使这两个子网络的最后几层共享权重。直觉上这样可以使得同一类的图片和文本生成尽可能相似的表达
- 最后面是一层全连接层来进行分类
- 这样以后,跨模态的联系可以很好的学到,并且有区分性的特征也可以同时学到
损失函数:
1.分类loss ,其中 Y 是label 的 one-hot 表示,计算一下分类结果与 Y 的差别。Frobenius norm 是对应元素的平方和再开方(可以理解成矩阵的 L2 范数)。




损失函数思想的总结:
- 提取出特征以后,经过全连接层进行分类,有一个分类的损失
- 第二部分的损失函数是一个分类的函数,它的过程是首先计算两个向量的余弦相似度,然后经过 sigmoid ,把它变成一个概率值,然后使得同一类的两个向量表达得到的概率值尽可能大
- 第三部分的损失是使得两种模态尽可能相似
- 起决定性作用的损失函数是1,4 第二个损失函数作用略小
空间表示
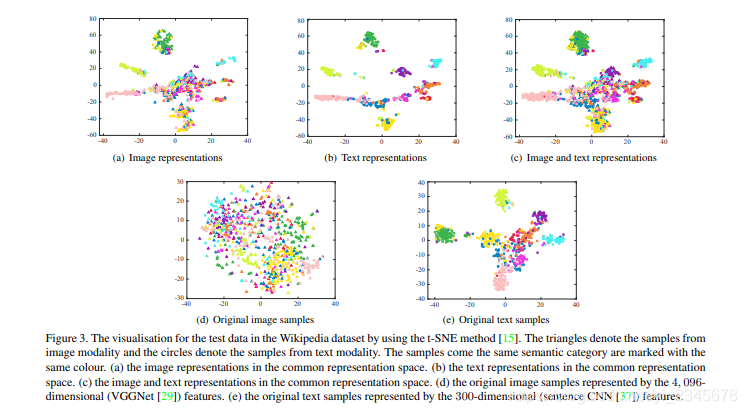
d和e是原始图像和文本在二维空间中的表示,a,b,c是经过特征提取之后以及混合后的在公共空间中的二维表示。
二、代码
这里使用的是将已经预训练好的图像和文本特征向量直接放到全连接层
class ImgNN(nn.Module):
def __init__(self,input_dim = 4096 ,output_dim = 1024):
super(ImgNN,self).__init__()
self.denseL1 = nn.Linear(input_dim,output_dim)
def forward(self,x):
out = F.relu(self.denseL1(x))
return out
class TextNN(nn.Module):
def __init__(self,input_dim = 1024 ,output_dim = 1024):
super(TextNN,self).__init__()
self.denseL1 = nn.Linear(input_dim,output_dim)
def forward(self,x):
out = F.relu(self.denseL1(x))
return out
第二层以后的全连接是参数共享的。
为了确保两个子网络能够为图像和文本学到公共的表达,我们使这两个子网络的最后几层共享权重。直觉上这样可以使得同一类的图片和文本生成尽可能相似的表达
class IDCM_NN(nn.Module):
def __init__(self,img_input_dim = 4096, img_output_dim = 2048,text_input_dim = 1024 ,text_output_dim = 2048,minus_one_dim = 1024,output_dim = 10):
super(IDCM_NN,self).__init__()
self.img_net = ImgNN(img_input_dim,img_output_dim)
self.text_net = TextNN(text_input_dim,text_output_dim)
self.linearLayer = nn.Linear(img_output_dim,minus_one_dim)
self.linearLayer2 = nn.Linear(minus_one_dim,output_dim)
def forward(self,img,text):
view1_feature = self.img_net(img)
view2_feature = self.text_net(text)
view1_feature = self.linearLayer(view1_feature)
#共享参数
view2_feature = self.linearLayer 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









