







1、Hive的查询与SQL类似,基本语法如下:
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[HAVING having_condition]
[CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list]]
[LIMIT number];查询emp表中,salary>45000的员工信息:
SELECT * FROM employee WHERE salary>45000;执行结果如下:
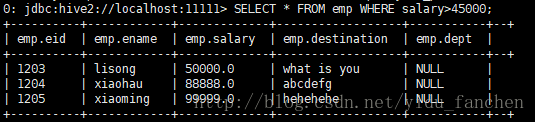
2、通过python访问hive,进行数据查询,代码如下:
# coding:utf-8
from pyhive import hive
from TCLIService.ttypes import TOperationState
# 打开hive连接
hiveConn = hive.connect(host='192.168.83.135',port=11111,username='hadoop',database='userdbbypy')
cursor = hiveConn.cursor()
sql = ''' SELECT * FROM emp WHERE salary>45000 '''
cursor.execute(sql, async=True)
# 得到执行语句的状态
status = cursor.poll().operationState
print "status:",status
for eid,ename,salary,destination,dept, in cursor.fetchall():
print eid,ename,salary,destination,dept
# 关闭hive连接
cursor.close()
hiveConn.close()执行代码,结果如下:
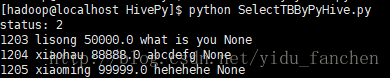
3、Order By查询
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[HAVING having_condition]
[ORDER BY col_list]]
[LIMIT number];查询emp表,并将salary按照由高到低排序:
SELECT * FROM emp ORDER BY salary;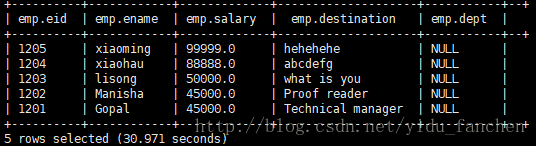
中间出了很多执行过程,不明所以。。
4、Group By查询
统计emp中工资一样的数量:
SELECT count(*),salary from emp GROUP BY salary;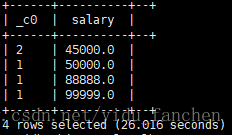














 1345
1345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









