







兼看设备端大模型系统回顾
文章转自公众号老刘说NLP
今天我们继续回顾,一个是Reliable LLM大模型幻觉的再认识-定义、原因及估计,一个是关于设备端大模型的一个总结,这两个工作都很有趣,仔细读读,都会有收获。
供大家一起参考并思考。
一、Reliable LLM大模型幻觉的再认识-定义、原因及估计
我们再来看看大模型幻觉的问题。
Reliable LLM《Reliable LLM: A Framework of Mitigating Hallucination regarding Knowledge and Uncertainty》,https://github.com/AmourWaltz/Reliable-LLM,https://amourwaltz.github.io/Reliable-LLM
该项目旨在展示有关大型语言模型(LLM)不确定性和置信度的研究,并收集了各种方法和研究方向,以
我们可以重点看看其中的几个点:
1、Hallucination(幻觉)
首先是定义,幻觉的定义各不相同,取决于特定任务。该项目专注于知识密集型任务(闭卷问答、对话、RAG、常识推理、翻译等)中的幻觉问题,其中幻觉指的是生成内容与世界知识不一致的非事实、不正确的知识。在知识密集型任务中,幻觉指的是生成内容与世界知识不一致的非事实、不正确的知识。
其次是原因,幻觉的原因包括数据中未经筛选的错误陈述、模型架构的输入长度限制、最大似然训练策略和多样化的解码策略。
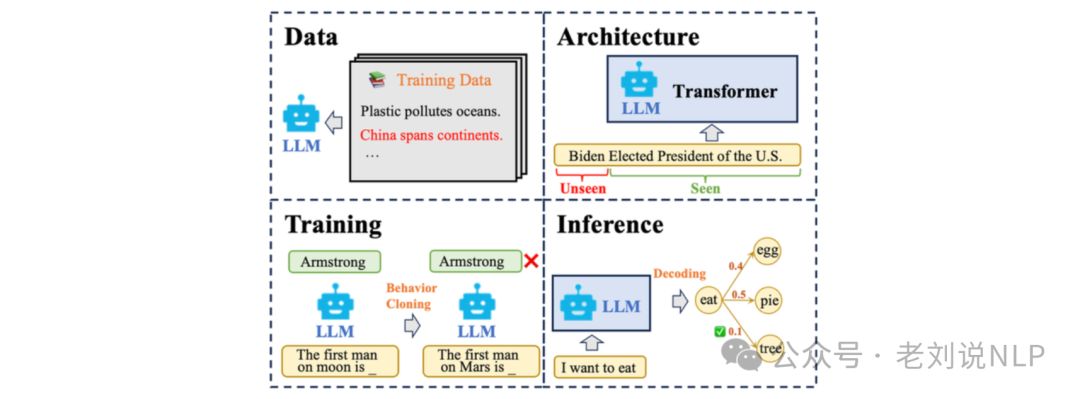
最后是解决,与开放生成任务相比,知识密集型任务有特定的真实参考——世界知识。因此,可以估计LLM的知识边界图来明确它知道什么。确保LLM对某个事实知识的确定性或诚实度对于检测幻觉至关重要(从灰色区域到绿色区域)。
2、Knowledge(知识)
可以通过绘制图表来粗略且简单地代表知识边界。然而,在现实中,像人类一样,对于许多知识,我们处于一种不确定的状态,而不仅仅是知道或不知道的状态。

此外,最大似然预测使得LLM倾向于生成过度自信的回答。即使LLM知道一个事实,如何让LLM准确地表达它们所知道的也很重要。
这增加了确定知识边界的复杂性,这导致两个具有挑战性的问题:
1)如何准确感知(感知)知识边界?
例如,给定一个问题,如“法国的首都是哪里?”,模型需要为此问题提供其置信度水平。
2)如何在边界有些模糊的情况下准确表达(表达)知识?
例如,如果对上述问题回答“巴黎”的置信度水平为40%,模型应该拒绝回答还是在此情况下提供回应?
3、Uncertainty(不确定性)
不确定性方面,分成2个部分,一个是传统模型校准,一个是生成式模型估计。
1)传统模型校准
模型在预测中的过度自信问题,以及如何通过置信度或不确定性估计来提高AI应用的可靠性。
https://amourwaltz.github.io/Reliable-LLM/figs/calibration.png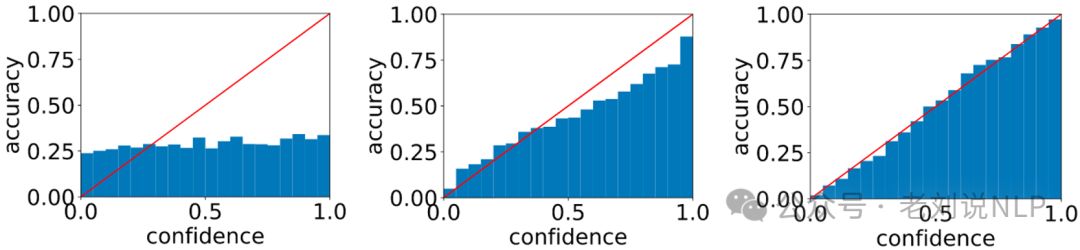
使用最大化似然(MLE)训练的模型在预测中容易过度自信,识别可靠的AI应用的置信度评分或不确定性估计至关重要。
如果模型的预测置信度(SoftMax概率)与答案正确的实际概率很好地对齐,则认为模型校准良好。
使用预期校准误差(ECE)和可靠性图来衡量校准性能。
2)生成模型的不确定性估计
如何量化生成句子的置信度和不确定性。为了校准生成性LLM,应该量化生成句子的置信度和不确定性。
不确定性分为偶然性(数据)和认识论(模型)不确定性。通常通过预测的熵来衡量,以指示模型预测的分散程度。
置信度则通常与输入和预测都相关。不确定性和置信度这两个术语经常互换使用。
尽管知识边界对于知识密集型任务很重要,但先前的研究中并没有具体的定义或概念。
当前估计知识边界的方法参考了置信度/不确定性估计方法,入下图所示:

① Likelihood-based method(基于似然的方法)
- 输入:What's the capital of France?(法国的首都是什么?)
- 输出:It is Paris(它是巴黎)
- 置信度:0.75
- 这种方法通过计算输出序列的概率来估计模型的置信度。
- 缺点包括需要归一化处理以应对可变长度的序列;要求访问词级概率信息,不适用于黑盒LLMs;无法捕获词级概率上的语义意义。
② Prompting-based method(提示法)
- 输入:What's the capital of France?(法国的首都是什么?)
- 输出:It is Paris(它是巴黎)
- 置信度:0.9
- 这种方法依赖于提示策略来诱导置信度估计,不同方法可能有不同的提示方式(如True的概率、数值置信度以及单词表达等)。
- 缺点包括不能提高LLM本身的置信度估计能力;容易导致过度自信。
③ Sampling-based method(采样法)
- 输入:What's the capital of France?(法国的首都是什么?)
- 输出:It is Paris(它是巴黎)
- 置信度:0.66
- 这种方法通过对LLM进行多次采样并聚合结果来估计置信度。
- 缺点包括需要额外的推理时间成本;不同的聚合方法可能会有所不同;不能改善LLM内在的置信度估计能力。
④ Training-based method(训练法)
- 输入:What's the capital of France?(法国的首都是什么?)
- 输出:It is Paris(它是巴黎)
- 置信度:0.72
- 这种方法使用一个额外的评估器对LLM的输出进行评估,并根据评估结果确定置信度。
- 缺点包括需要训练额外的评估器;在未见过的领域上很难学习到LLM的内在置信度估计能力。
二、设备端大模型的一个回顾
设备端大模型大全《On-Device Language Models: A Comprehensive Review》: https://github.com/NexaAI/Awesome-LLMs-on-device,https://arxiv.org/abs/2409.00088,主要探讨了在资源受限的移动设备上部署大型语言模型(LLMs)的挑战和解决方案。

我们可以重点看其中的几个点。
1、工作的整体架构模块
Figure 2是展示这篇综述文章的结构或框架
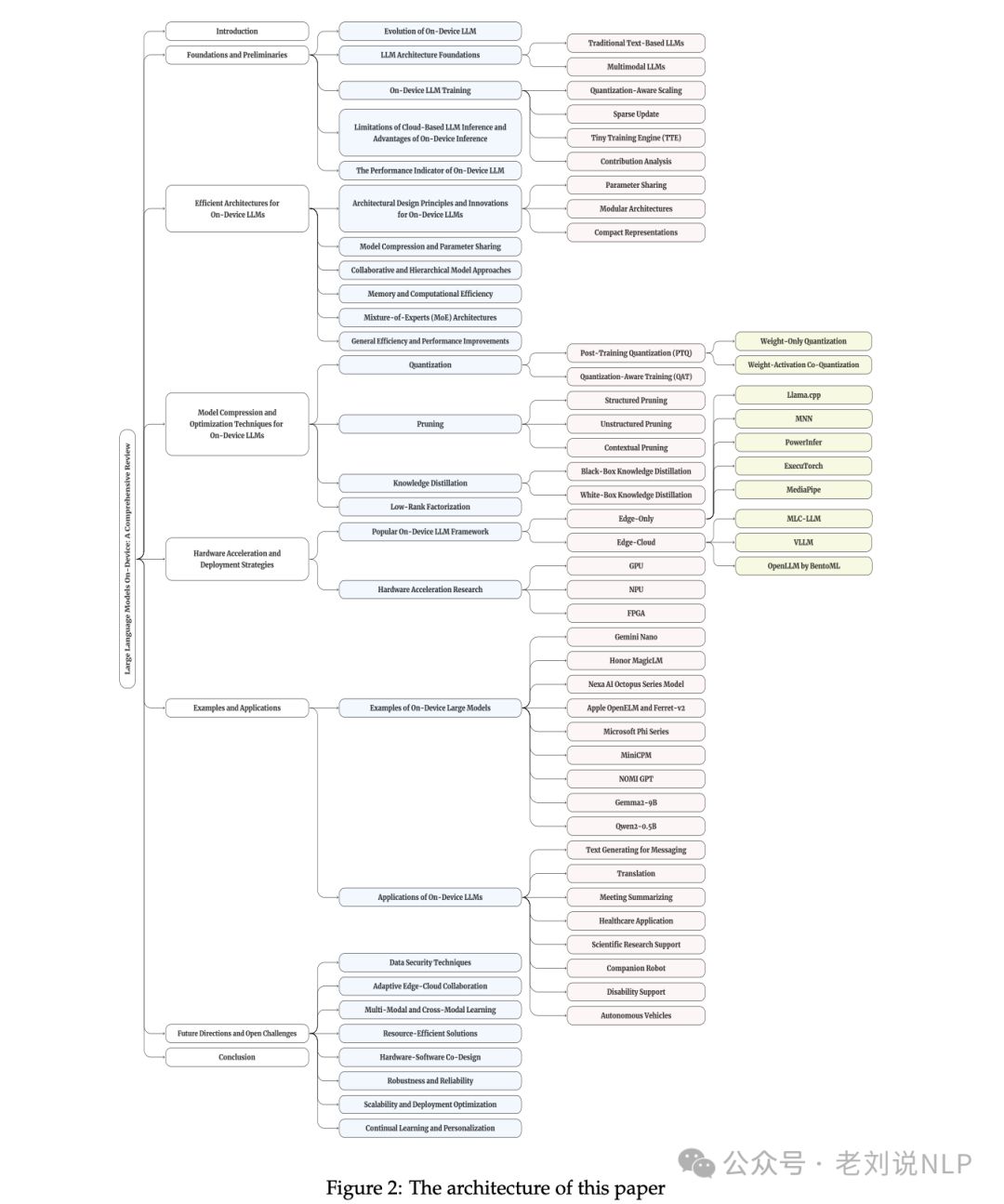
1)引言(Introduction):介绍on-device语言模型的背景、重要性以及研究动机。
2)基础知识和预备知识(Foundations and Preliminaries):概述on-device LLMs的发展历程、基础架构和训练技术。
3)高效的架构(Efficient Architectures for On-Device LLMs):探讨专为边缘设备设计的LLM架构,包括参数共享、模块化设计和内存效率。
4)模型压缩和优化技术(Model Compression and Optimization Techniques):详细说明量化、剪枝、知识蒸馏等模型压缩技术,以及它们如何帮助在资源受限的设备上部署LLMs。
5)硬件加速和部署策略(Hardware Acceleration and Deployment Strategies):分析不同的硬件加速方法和部署策略,以及它们如何影响on-device LLMs的性能。
6)流行on-device LLM框架(Popular On-Device LLM Framework):介绍和比较不同的软件框架和库,这些框架和库支持在移动和边缘设备上开发和部署LLMs。
7)实例和应用(Examples and Applications):通过案例研究展示on-device LLMs在现实世界中的应用,以及它们带来的潜在好处。
8)未来方向和开放性挑战(Future Directions and Open Challenges):讨论当前on-device LLMs领域的未解决的问题和未来的研究方向。
9)结论(Conclusion):总结on-device LLMs的关键点,并强调其在智能计算领域的潜力和重要性。
2、当前端侧大模型的市场
图表1展示了从2022年到2032年,全球on-device边缘AI市场规模的预测,按最终用户划分,单位为亿美元。
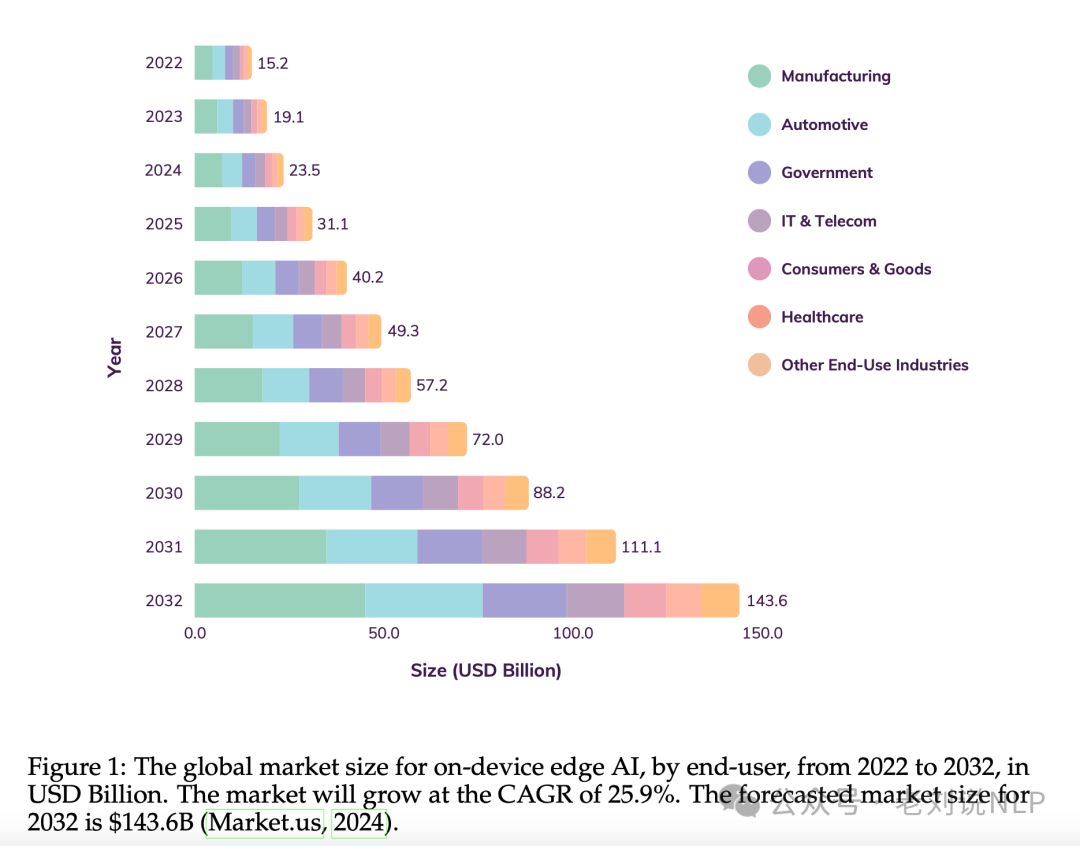
1) 市场增长预测:预计on-device边缘AI市场将以25.9%的复合年增长率(CAGR)增长。这意味着市场规模几乎每年都会以这个比例增长。
2) 市场规模预测:到2032年,预计市场规模将达到1436亿美元。这表明了未来十年内,边缘AI市场的显著扩张和对此类技术需求的增加。
3) 按行业划分的市场规模:不同行业(如制造业、汽车行业、政府部门、IT和电信、消费品和医疗保健等)的市场规模预测。
3、不同on-device语言模型(LLMs)的比较分析

总结
本文主要讲了两个事儿,今天我们继续回顾,一个是Reliable LLM大模型幻觉的再认识-定义、原因及估计,一个是关于设备端大模型的一个总结
常总结,常看,常思考,总会有很多进步。
清醒前进,踏实进步。
参考文献
1、https://arxiv.org/abs/2409.00088
2、https://github.com/AmourWaltz/Reliable-LLM
3、https://mp.weixin.qq.com/s/mBcqN7YGXbIzz3Gt7m3bMw


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









