







一个辩证研究及9个COT开源数据集
文章转自公众号老刘说NLP
openai o1出来之后,cot这类思维链数据受到大家广泛关注,最近也出现了一些论证的工作,因此,我们先来看看一个辩证研究:大模型COT在什么任务上有用,是否真的有用,会有一些发现。
另一个是关于数据的问题,我们可以看看目前都有哪些可用的开源CoT数据集。
一、关于COT的一个辩证研究:在什么任务上有用
关于cot的一个研究,《To CoT or not to CoT? Chain-of-thought helps mainly on math and symbolic reasoning》,https://arxiv.org/abs/2409.12183,通过定量的元分析和对20个数据集、14个模型的实验评估,研究了链式思考(Chain-of-Thought, CoT)提示技术在提升大型语言模型(LLMs)解题能力方面的有效性。

如图1所示,其包含了两部分数据,用以说明链式思考(CoT)在不同类型的任务中相对于直接回答(Direct Answer, DA)的性能提升:
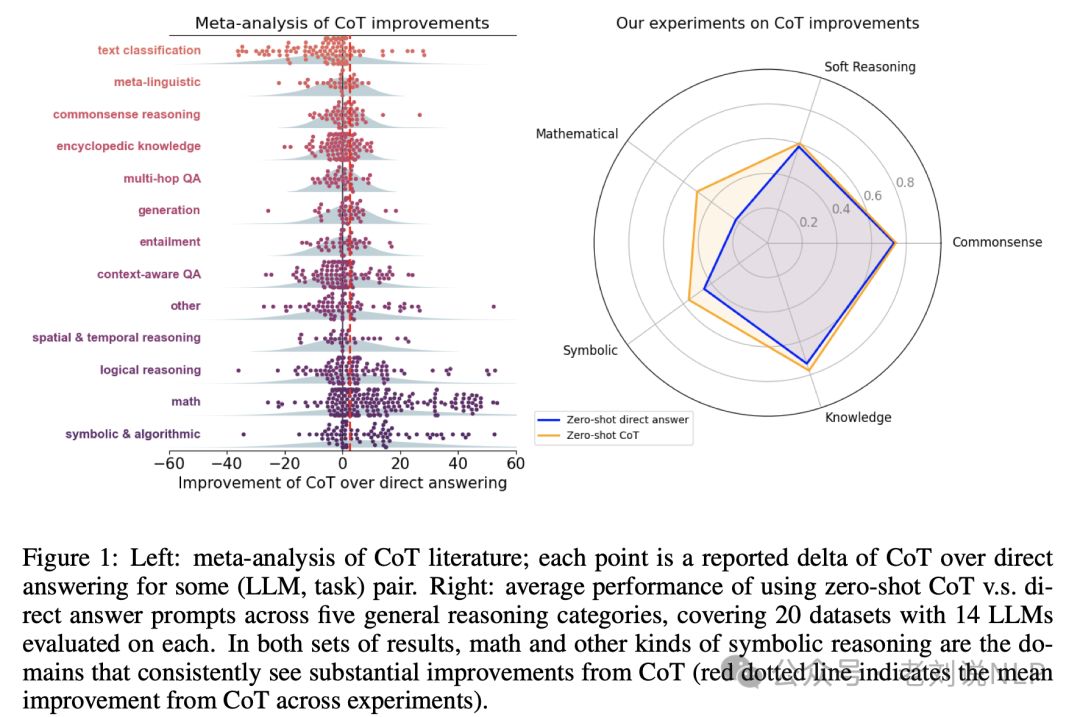
左侧(Left):CoT文献的元分析,每个点代表在某个(大模型,任务)组合上,使用CoT相较于直接回答所报告的性能差异(Delta)。 这个分析覆盖了超过100篇使用CoT的研究论文。点的位置表示在特定任务和模型组合下,CoT相比于直接回答方法带来的准确率提升或下降。
右侧(Right):零样本(Zero-shot)CoT与直接回答提示在五种通用推理类别上的平均性能比较;涵盖了20个数据集,并且每个数据集在14个不同的大型语言模型上进行了评估。这五种通用推理类别可能包括数学、逻辑、常识推理、知识推理等。图表展示了在这些类别的任务中,使用CoT的平均性能与直接回答的平均性能之间的比较。在数学和符号推理这类任务中,CoT一致地显示出显著的性能提升(红色点状线表示在实验中CoT的平均性能提升)。
值得注意的是,图1强调了CoT在处理数学和符号推理任务时的有效性,而在其他类型的推理任务中,CoT带来的性能提升则不那么显著。红色点状线提供了一个直观的比较,展示了在所有实验中CoT相对于直接回答的平均性能提升。
基于这个实验结果,可以到如下发现:
1、发现1-基于提示的CoT在何处以及为什么有帮助
Finding 1: CoT only helps substantially on problems requiring mathematical, logical, or algorithmic reasoning
CoT只在需要数学、逻辑或算法推理的问题上提供显著的帮助。
在其他类型的任务中,CoT带来巨大收益的案例很少,这些异常值中有许多包含了一些符号推理的成分。例如,在MMLU和MMLU Pro上,分析了CoT的改进,并发现CoT只在数据集的数学部分带来好处。MMLU上CoT带来的总性能提升中,高达95%归因于问题或生成的输出中包含“=”的问题。对于非数学问题,发现没有特征表明CoT何时会有帮助。
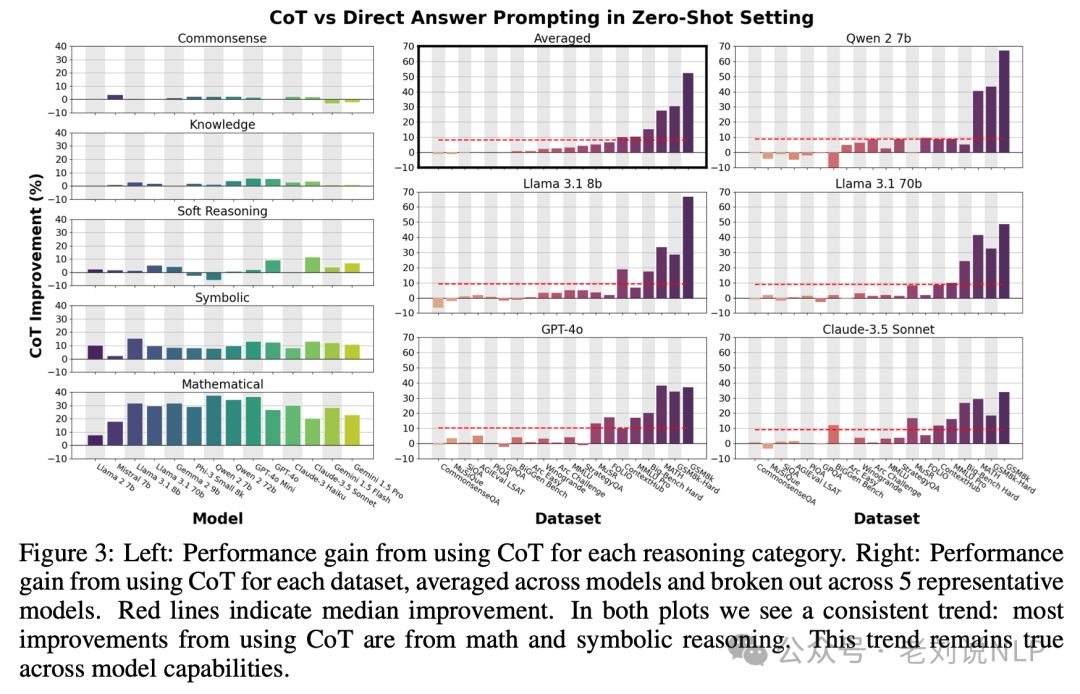
2、发现2-为什么CoT在这些问题上有所改进,而只在这些问题上有所改进
Finding 2: CoT primarily helps with the execution step that performs computation and symbolic manipulation, but falls short of what LLMs with tool augmentation can do.
数学和形式逻辑推理数据集可以被分解为两个处理阶段:规划步骤(例如,将问题解析为方程)和执行步骤(构建中间输出并朝着解决方案努力)。
因此,发现CoT主要有助于执行步骤,执行步骤执行计算和符号操作,但与使用符号求解器相比,它的性能较差。
使用CoT提示的LMs可以生成可执行的形式解决方案计划,并比直接回答更好地执行这些计划。
但是使用LMs生成解决方案计划,然后使用外部符号求解器来解决问题,对于这些任务的两个阶段都比使用CoT更好。
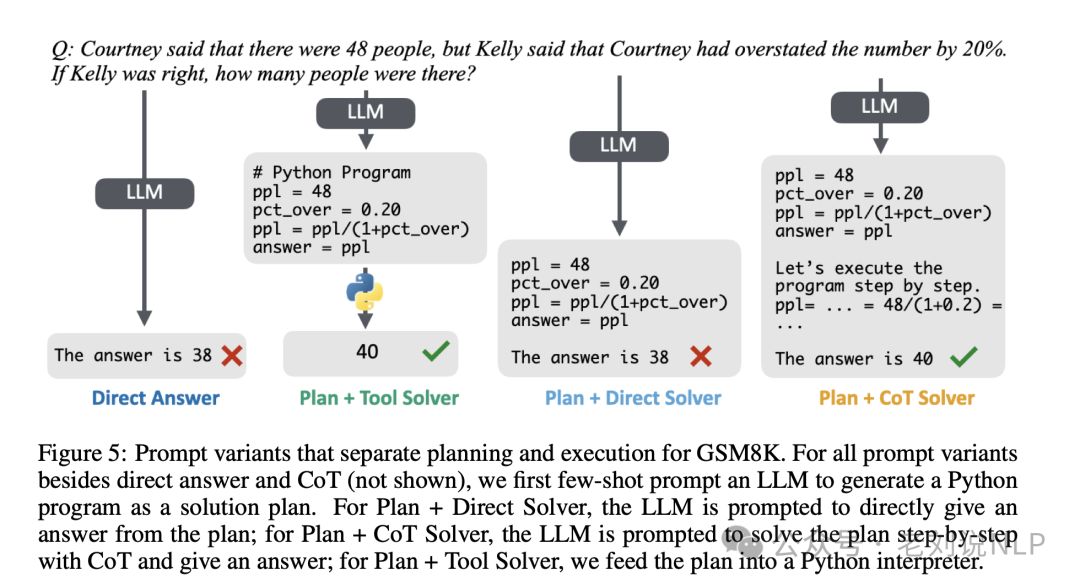
这些结果说明,CoT的实用性通常受到工具增强的限制:在CoT有帮助的问题上,已经拥有比CoT更强大的工具可以采用,而在没有工具的“软推理”问题上,如常识,CoT的益处有限。这一描述有两个主要含义。
首先,对于许多广泛使用CoT的问题,CoT是不必要的:存在更有效的提示策略,这些策略在推理成本更低的情况下可以获得类似的性能。
其次,迫切需要超越基于提示的CoT,转向基于搜索、交互代理或更重针对CoT进行微调的模型的更复杂方法。
因此,未来的工作可以探索如何更好地利用中间计算来解决数学和符号推理领域之外的挑战性问题。
二、一些可用的开源COT项目
当然,现在很多人都在寻找COT数据集,但很遗憾,开源现成的并不多,通过查找github,我们找到了如下9个数据集,实际上都是Fkan发布的,中文则更少,做的是翻译。
1、alpaca-CoT数据集项目
1)alpaca-CoT英文数据集
地址https://github.com/PhoebusSi/alpaca-CoT/tree/main/data,CoT数据集是通过对FLAN发布的9个CoT数据集进行格式化组合得到的。它包含9个CoT任务,涉及74771个样本。
每个数据集的分布,如下:
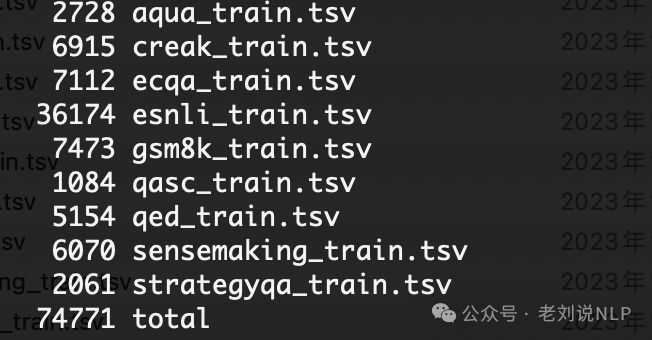
不过,全是英文,可以看看一个具体示例:

2)CoT_zh中文数据集
CoT_zh数据集是通过使用谷歌翻译将CoT数据集转成中文得到。
地址:https://github.com/SpringDuB/fine_tune_ChatGLM/tree/main/datas/CoT_zh
可以使用modelscope加载数据:
from modelscope.msdatasets import MsDatasetfrom modelscope.utils.constant import DownloadMode
# Load the CoT chinese dataset
ds_train = MsDataset.load( 'YorickHe/CoT_zh', split= 'train', download_mode=DownloadMode.FORCE_REDOWNLOAD)
print(next(iter(ds_train)))
可以看看一个具体的例子:
参考文献
1、https://github.com/PhoebusSi/alpaca-CoT/tree/main/data
2、https://github.com/SpringDuB/fine_tune_ChatGLM/tree/main/datas/CoT_zh
3、https://arxiv.org/abs/2409.12183

















 429
429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









