







最近有个项目需要用无线模块下载文件,由于手头已经有一个HTTP GET的实现,那么就用HTTP来做了。做完之后我就在想,为什么一定要用HTTP呢,为何不能用FTP?当然,手头没有现成的实现,想想应该会复杂一些。
简单百度一下:FTP是专门用于文件传输的协议。HTTP只是超文本传输协议(他的传输功能最原始的目的仅仅只是为了将超文本的信息(包括图象视频等)传到你的机子上就行了)
网上还提到了FTP更加好管理。我只是下载一个100K的文件,而且项目环境之前也用了HTTP,就暂时用HTTP把。回过头有时间好好了解一下两者的区别。
GET 报文格式
/* 如果文件不大,直接下载整个文件 */
sprintf(szRequest,
"GET %s HTTP/1.1\r\n"
"Host: %s:%s\r\n"
"Connection: keep-alive\r\n"
"Keep-Alive:timeout=3600,max=1000\r\n\r\n",
url, ip, port);
/* 如果文件较大,一部分一部分下载整个文件 */
sprintf(range, "Range:bytes=%d-%d\r\n");
sprintf(szRequest,
"GET %s HTTP/1.1\r\n"
"Host: %s:%s\r\n"
"Connection: keep-alive\r\n"
"%s"
"Keep-Alive:timeout=3600,max=1000\r\n\r\n",
url, ip, port, range);
格式分析
"GET %s HTTP/1.1\r\n"
"Host: %s:%s\r\n"
第一行就说明了这个请求的请求方式,即为GET方式,要请求的子路径为%s,即一个文件的url,例如我们的服务器地址为www.myhost.com,要请求的文件为/test/upgrade.txt,然后我们的这个请求的完整路径就是http://www.myhost.com/test/upgrade.txt,最后说明了HTTP协议的版本号为1.1。
下面看第二行,Host,顾名思义,是主机地址,这里假如不带端口,即www.myhost.com,那么就意味着访问的web服务器在默认的80端口。
这个时候我们往回看第一行,实际上url可以直接写/test/upgrade.txt,这是个从web服务器根目录开始的绝对地址,不需要http://www.myhost.com。
我刚好在这里遇到了问题,多此一举得带了http://www.myhost.com:8896,我当时web服务器在8896端口,而且Host写了http://www.myhost.com,这就出问题了,因为这样写的意思即端口是80,然后第一行又是8896,不一致,服务器直接给了我一个400,bad request,刚开始不明白,调试了好一会儿。
解决方法,自然是在host把端口8896也写上。另外求简单点,就是把第一行前面的host头去掉,清清楚楚,host就按Host中决定,url这里写绝对路径就好了。希望能帮助到大家,当时还疑惑了一下。查的时候还抓了个火狐浏览器get文件的包:
GET /profile/upload/upgrade/20200508131016/updateA.bin HTTP/1.1
Host: 115.238.50.126:8896
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:75.0) Gecko/20100101 Firefox/75.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Connection: keep-alive
Cookie:(省略)
可以看到他就是用一个绝对路径就好了。
"Connection: keep-alive\r\n"
我们知道HTTP协议采用“请求-应答”模式,当使用普通模式,即非KeepAlive模式时,每个请求/应答客户和服务器都要新建一个连接,完成之后立即断开连接(HTTP协议为无连接的协议);当使用Keep-Alive模式(又称持久连接、连接重用)时,Keep-Alive功能使客户端到服务器端的连接持续有效,当出现对服务器的后续请求时,Keep-Alive功能避免了建立或者重新建立连接。
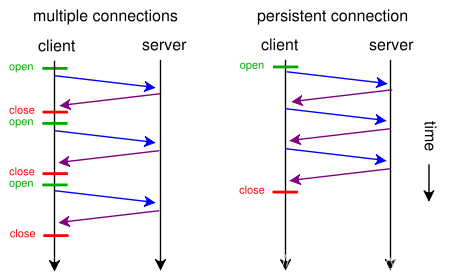
如上图中,左边的是关闭Keep-Alive的情况,每次请求都需要建立连接,然后关闭连接;右边的则是Keep-Alive,在第一次建立请求之后保持连接,然后后续的就不需要每次都建立、关闭连接了,启用Keep-Alive模式肯定更高效,性能更高,因为避免了建立/释放连接的开销。
http 1.0中默认是关闭的,需要在http头加入"Connection: Keep-Alive",才能启用Keep-Alive;http 1.1中默认启用Keep-Alive,如果加入"Connection: close ",才关闭。目前大部分浏览器都是用http1.1协议,也就是说默认都会发起Keep-Alive的连接请求了,所以是否能完成一个完整的Keep- Alive连接就看服务器设置情况。
"Range:bytes=%d-%d\r\n"
这一行是你想下载的字节,比如文件比较大你一次只想要GET 512个字节,那么就可以指定开始和结束的范围,比如0-511,512-1023…类似指针,就这样把一个大文件一个包一个包得GET下来。
部分内容摘自:http post文件上传机制














 4813
4813











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









