







在我们的程序中,数据结构还有变量等等都需要占有内存,在很多系统中,它都要求内存分配的时候要对齐,这样做的好处就是可以提高访问内存的速度。
首先由一个程序引入话题:
2 //程序1
3 #include <iostream>
4
5 using namespace std;
6
7 struct st1
8 {
9 char a ;
10 int b ;
11 short c ;
12 };
13
14 struct st2
15 {
16 short c ;
17 char a ;
18 int b ;
19 };
20
21 int main()
22 {
23 cout<<"sizeof(st1) is "<<sizeof(st1)<<endl;
24 cout<<"sizeof(st2) is "<<sizeof(st2)<<endl;
25 return 0 ;
26 }
27
程序的输出结果为:
sizeof(st1) is 12
sizeof(st2) is 8
问题出来了,这两个一样的结构体,为什么sizeof的时候大小不一样呢?
本文的主要目的就是解释明白这一问题。
内存对齐,正是因为内存对齐的影响,导致结果不同。
对于大多数的程序员来说,内存对齐基本上是透明的,这是编译器该干的活,编译器为程序中的每个数据单元安排在合适的位置上,从而导致了相同的变量,不同声明顺序的结构体大小的不同。
那么编译器为什么要进行内存对齐呢?程序1中结构体按常理来理解sizeof(st1)和sizeof(st2)结果都应该是7,4(int) + 2(short) + 1(char) = 7 。经过内存对齐后,结构体的空间反而增大了。
在解释内存对齐的作用前,先来看下内存对齐的规则:
1、 对于结构的各个成员,第一个成员位于偏移为0的位置,以后每个数据成员的偏移量必须是min(#pragma pack()指定的数,这个数据成员的自身长度) 的倍数。
2、 在数据成员完成各自对齐之后,结构(或联合)本身也要进行对齐,对齐将按照#pragma pack指定的数值和结构(或联合)最大数据成员长度中,比较小的那个进行。
#pragma pack(n) 表示设置为n字节对齐。 VC6默认8字节对齐
以程序1为例解释对齐的规则 :
St1 :char占一个字节,起始偏移为0 ,int 占4个字节,min(#pragma pack()指定的数,这个数据成员的自身长度) = 4(VC6默认8字节对齐),所以int按4字节对齐,起始偏移必须为4的倍数,所以起始偏移为4,在char后编译器会添加3个字节的额外字节,不存放任意数据。short占2个字节,按2字节对齐,起始偏移为8,正好是2的倍数,无须添加额外字节。到此规则1的数据成员对齐结束,此时的内存状态为:
oxxx|oooo|oo
0123 4567 89 (地址)
(x表示额外添加的字节)
共占10个字节。还要继续进行结构本身的对齐,对齐将按照#pragma pack指定的数值和结构(或联合)最大数据成员长度中,比较小的那个进行,st1结构中最大数据成员长度为int,占4字节,而默认的#pragma pack 指定的值为8,所以结果本身按照4字节对齐,结构总大小必须为4的倍数,需添加2个额外字节使结构的总大小为12 。此时的内存状态为:
oxxx|oooo|ooxx
0123 4567 89ab (地址)
到此内存对齐结束。St1占用了12个字节而非7个字节。
St2 的对齐方法和st1相同,读者可自己完成。
内存对齐的主要作用是:
1、 平台原因(移植原因):不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
2、 性能原因:经过内存对齐后,CPU的内存访问速度大大提升。具体原因稍后解释。
图一:

这是普通程序员心目中的内存印象,由一个个的字节组成,而CPU并不是这么看待的。
图二:

CPU把内存当成是一块一块的,块的大小可以是2,4,8,16字节大小,因此CPU在读取内存时是一块一块进行读取的。块大小成为memory access granularity(粒度) 本人把它翻译为“内存读取粒度” 。
假设CPU要读取一个int型4字节大小的数据到寄存器中,分两种情况讨论:
1、数据从0字节开始
2、数据从1字节开始
再次假设内存读取粒度为4。
图三:

当该数据是从0字节开始时,很CPU只需读取内存一次即可把这4字节的数据完全读取到寄存器中。
当该数据是从1字节开始时,问题变的有些复杂,此时该int型数据不是位于内存读取边界上,这就是一类内存未对齐的数据。
图四:

此时CPU先访问一次内存,读取0—3字节的数据进寄存器,并再次读取4—5字节的数据进寄存器,接着把0字节和6,7,8字节的数据剔除,最后合并1,2,3,4字节的数据进寄存器。对一个内存未对齐的数据进行了这么多额外的操作,大大降低了CPU性能。
这还属于乐观情况了,上文提到内存对齐的作用之一为平台的移植原因,因为以上操作只有有部分CPU肯干,其他一部分CPU遇到未对齐边界就直接罢工了。
图片来自:Data alignment: Straighten up and fly right
如大家对内存对齐对性能的具体影响情况,可以参考上文。
====================================================================================================================
画图解析 更清晰
我们还是先来看一段简单的程序:
程序一
2 using namespace std;
3
4 struct X1
5 {
6 int i; // 4个字节
7 char c1; // 1个字节
8 char c2; // 1个字节
9 };
10
11 struct X2
12 {
13 char c1; // 1个字节
14 int i; // 4个字节
15 char c2; // 1个字节
16 };
17
18 struct X3
19 {
20 char c1; // 1个字节
21 char c2; // 1个字节
22 int i; // 4个字节
23 };
24 int main()
25 {
26 cout << " long " << sizeof ( long ) << " \n " ;
27 cout << " float " << sizeof ( float ) << " \n " ;
28 cout << " int " << sizeof ( int ) << " \n " ;
29 cout << " char " << sizeof ( char ) << " \n " ;
30
31 X1 x1;
32 X2 x2;
33 X3 x3;
34 cout << " x1 的大小 " << sizeof (x1) << " \n " ;
35 cout << " x2 的大小 " << sizeof (x2) << " \n " ;
36 cout << " x3 的大小 " << sizeof (x3) << " \n " ;
37 return 0 ;
38 }
这段程序的功能很简单,就是定义了三个结构X1,X2,X3,这三个结构的主要区别就是内存数据摆放的顺序,其他都是一样的,另外程序输入了几种基本类型所占用的字节数,以及我们这里的三个结构所占用的字节数。
这段程序的运行结果为:
2 float 4
3 int 4
4 char 1
5 x1 的大小 8
6 x2 的大小 12
7 x3 的大小 8
结果的前面四行没有什么问题,但是我们在最后三行就可以看到三个结构占用的空间大小不一样,造成这个原因就是内部数据的摆放顺序,怎么会这样呢?
下面就是我们需要讲的内存对齐了。
内存是一个连续的块,我们可以用下面的图来表示, 它是以4个字节对一个对齐单位的:
图一

让我们看看三个结构在内存中的布局:
首先是 X1,如下图所示
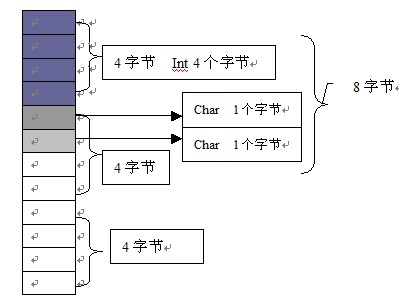
X1 中第一个是 Int类型,它占有4字节,所以前面4格就是满了,然后第二个是char类型,这中类型只占一个字节,所以它占有了第二个4字节组块中的第一格,第三个也是char类型,所以它也占用一个字节,它就排在了第二个组块的第二格,因为它们加在一起大小也不超过一个块,所以他们三个变量在内存中的结构就是这样的,因为有内存分块对齐,所以最后出来的结果是8,而不是6,因为后面两个格子其实也算是被用了。
再次看看X2,如图所示
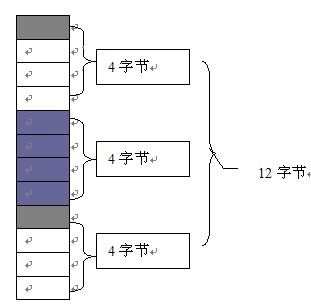
X2中第一个类型是Char类型,它占用一个字节,所以它首先排在第一组块的第一个格子里面,第二个是Int类型,它占用4个字节,第一组块已经用掉一格,还剩3格,肯定是无法放下第二Int类型的,因为要考虑到对齐,所以不得不把它放到第二个组块,第三个类型是Char类型,跟第一个类似。所因为有内存分块对齐,我们的内存就不是8个格子了,而是12个了。
再看看X3,如下图所示:
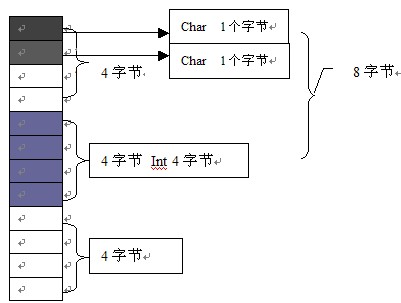
关于X3的说明其实跟X1是类似的,只不过它把两个1个字节的放到了前面,相信看了前面两种情况的说明这里也是很容易理解的。















 286
286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









