









内存对齐问题
内存对齐
参考文章:
https://blog.shengbin.me/posts/gcc-attribute-aligned-and-packed
现代计算机中内存空间都是按照 byte 划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始。
但是CPU读取内存实际上并不是按字节读取,而是按块读取,块的大小可以为2,4,8,16字节大小,块大小称为内存读取粒度(memory access granularity)。
物理层面上:
一方面,我们的计算机的CPU在访问存储器的时候只能在某些地址处获取某些特定类型的数据。
另一方面,因为CPU读取数据的时候不是一个一个字节读的,而是一块一块读的。
- 如果一个内存地址是N的倍数,我们就说它是N字节对齐的(N-byte aligned)。
基本数据类型的对齐:
参考:
https://docs.microsoft.com/zh-cn/cpp/cpp/alignment-cpp-declarations?view=vs-2019
对于C/C++中的基本数据类型,假设它的长度为n字节,那么该类型的变量会被编译器默认分配到n字节对齐的内存上,这种默认情况下的变量对齐方式又称作自然对齐(naturally aligned)。
例如,
- bool和char的长度是1字节(8bits),此类型变量的地址将是1字节对齐的(地址类型:任意值);
- short的长度是2字节(16bits),此类型变量的地址将是2字节对齐的(地址类型:0x…0;0x…2;0x…4;0x…6;0x…8;0x…A;0x…C;0x…0E);
- int和long和float的长度是4字节(32bits),此类型变量的地址将是4字节对齐的(地址类型:0x…0;0x…4;0x…8;0x…C;);
- long ong和double和long double的长度是8字节(64bits),此类型变量的地址将是8字节对齐的(地址类型:0x…0;0x…8;)。

非基本数据类型对齐
数组 :按照每个数据类型对齐,第一个对齐了后面的自然也就对齐了。
联合 :按其包含的长度最大的数据类型对齐。
结构体: 结构体中每个数据类型都要对齐,并且整体也要调整。
类:跟结构体差不多
结构体数据对齐
- 基本数据类型自身的对齐值:
对于char型数据,其自身对齐值为1,对于short型,对齐值为2,对于int,float,long类型,其自身对齐值为4,单位字节。 - 结构体或者类的自身对齐值:其成员中自身对齐值最大的那个值。
- 指定对齐值:#pragma pack (value)时的指定对齐值value。
- 数据成员、结构体和类的有效对齐值:自身对齐值和指定对齐值中小的那个值。
有效对齐值N是最终决定数据存放地址的值。有效对齐N,就是表示“对齐在N上”,也就是说该数据的"存放起始地址%N=0"。
数据结构中的数据变量都是按定义的先后顺序来排放的。第一个数据变量的起始地址就是数据结构的起始地址。
结构体的内部成员变量要对齐,结构体本身也要根据自身的有效对齐值圆整(就是结构体占用总长度要是结构体自身的有效对齐值的整数倍)
结构体对齐规则
(1) 结构体第一个成员的偏移量(offset)为0,以后每个数据成员的偏移量必须是min(#pragma pack()指定的数,这个数据成员的自身对齐值) 的倍数,如有需要编译器会在成员之间加上填充字节。
(2) 在数据成员完成各自对齐之后,结构本身也要进行对齐,对齐将按照min(#pragma pack()指定的数,结构体数据成员中自身对齐值最大的那个值)。如有需要编译器会在最末一个成员之后加上填充字节。
编译器提供手动指定对齐值的关键字, #pragma pack(N)表示设置为n字节对齐,比如#pragma pack(1),#pragma pack(4)等。
未手动提供,则默认一个对齐值,现在,大部分编译器应该都默认8字节对齐
举个实例:
我用的mingw64编译器,默认对齐值为8
#include <stdio.h>
#include <iostream>
using namespace std;
struct Test
{//设结构体中第一个成员的offset = 0x0000000000000000
char c; //offset = 0x0000000000000000. 区间:[0x0000000000000000,0x0000000000000000]
int i; //offset = min{8,4}的整数倍为0x0000000000000004. 区间:[0x0000000000000004,0x0000000000000007]
short s; //offset = min{8,2}的整数倍,0x0000000000000008. 区间:[0x0000000000000008,0x00000000000000009]
double d; //offset = min{8,8}的整数倍,0x0000000000000010. 区间:[0x0000000000000010,0x0000000000000017]
//整体占24字节,并且24 为 min{8,8}的整数倍,故对齐,无需在尾部填充占位。
};
int main()
{
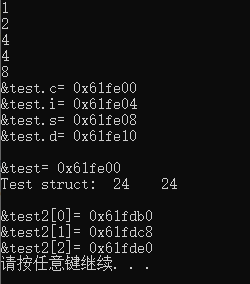
cout << sizeof(char) << endl; // 1
cout << sizeof(short) << endl; // 2
cout << sizeof(int) << endl; // 4
cout << sizeof(double) << endl; // 8
Test test;
/*
cout<<"&test.c= "<<&test.c<<endl;//这里会出错
int型变量可以直接使用“&”获取地址,而char型变量取不行。
原因:&a是一个char*变量,应该指向一个字符串,并且字符串需要以终止符(“\0”)结尾,但&a却没有终止符,所以会输出后面的乱码
解决办法:1. 可以用printf代替cout输出
2. 将&a强制转换成(void *)&a
*/
cout<<"&test.c= "<<(void *)&test.c<<endl;
cout<<"&test.i= "<<&test.i<<endl;
cout<<"&test.s= "<<&test.s<<endl;
cout<<"&test.d= "<<&test.d<<endl;
cout<<endl<<"&test= "<<&test<<endl;
cout << "Test struct: " << sizeof(Test) << " " << sizeof(test) << endl;
Test test2[3];//按照每个数据类型对齐,第一个对齐了后面的自然也就对齐了。
cout<<endl<<"&test2[0]= "<<&test2[0]<<endl;
cout<<"&test2[1]= "<<&test2[1]<<endl;
cout<<"&test2[2]= "<<&test2[2]<<endl;
system("pause");
return 0;
}
结果
- 手动设置#pragma pack(4),结果如何变化呢?
#include <stdio.h>
#include <iostream>
using namespace std;
#pragma pack(4)
struct Test
{//设结构体中第一个成员的offset = 0x0000000000000000
char c; //offset = 0x0000000000000000. 区间:[0x0000000000000000,0x0000000000000000]
int i; //offset = min{4,4}的整数倍为0x0000000000000004. 区间:[0x0000000000000004,0x0000000000000007]
short s; //offset = min{4,2}的整数倍,0x0000000000000008. 区间:[0x0000000000000008,0x0000000000000009]
double d; //offset = min{4,8}的整数倍,0x00000000000000C. 区间:[0x000000000000000C,0x0000000000000013]
//整体占20字节,并且20 为 min{4,8}的整数倍,故对齐,无需在尾部填充占位。
};
int main()
{
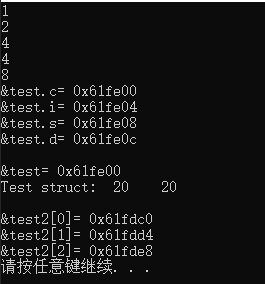
cout << sizeof(char) << endl; // 1
cout << sizeof(short) << endl; // 2
cout << sizeof(int) << endl; // 4
cout << sizeof(long) << endl; // 8
cout << sizeof(double) << endl; // 8
Test test;
/*
cout<<"&test.c= "<<&test.c<<endl;//这里会出错
int型变量可以直接使用“&”获取地址,而char型变量取不行。
原因:&a是一个char*变量,应该指向一个字符串,并且字符串需要以终止符(“\0”)结尾,但&a却没有终止符,所以会输出后面的乱码
解决办法:1. 可以用printf代替cout输出
2. 将&a强制转换成(void *)&a
*/
cout<<"&test.c= "<<(void *)&test.c<<endl;
cout<<"&test.i= "<<&test.i<<endl;
cout<<"&test.s= "<<&test.s<<endl;
cout<<"&test.d= "<<&test.d<<endl;
cout<<endl<<"&test= "<<&test<<endl;
cout << "Test struct: " << sizeof(Test) << " " << sizeof(test) << endl;
Test test2[3];//按照每个数据类型对齐,第一个对齐了后面的自然也就对齐了。
cout<<endl<<"&test2[0]= "<<&test2[0]<<endl;
cout<<"&test2[1]= "<<&test2[1]<<endl;
cout<<"&test2[2]= "<<&test2[2]<<endl;
system("pause");
return 0;
}
栈内存对齐
在VC/C++中,栈的对齐方式不受结构体成员对齐选项的影响。
以x86_64处理器为例 ,栈的字节对齐,实际是指栈顶指针必须须是16字节的整数倍。
参考https://www.cnblogs.com/tcctw/p/11333743.html
栈上的基本数据类型总是按自然对齐。
自然对齐: 对于C/C++中的基本数据类型,假设它的长度为n字节,那么该类型的变量会被编译器默认分配到n字节对齐的内存上
更改对齐方式(pragma pack(N))只能影响结构体本身及其内部成员变量的对齐。
实例:
#include<iostream>
using namespace std;
#pragma pack(push,1) //1可以改为2,4,8...
//这里设置结构体按一字节对齐
struct Test{
char t1; //1
short t2;//2
double t3;//8
};
#pragma pack(pop)
//恢复原来的对齐方式
int main(){
//临时变量都在栈上存储
char a;
short b;
double c;
char d;
double e;
struct Test t;
/*
cout<<"a address: "<<&a<<endl;//这里会出错
int型变量可以直接使用“&”获取地址,而char型变量取不行。
原因:&a是一个char*变量,应该指向一个字符串,并且字符串需要以终止符(“\0”)结尾,但&a却没有终止符,所以会输出后面的乱码
解决办法:1. 可以用printf代替cout输出
2. 将&a强制转换成(void *)&a
*/
cout<<"char a address: \t"<<(void*)&a<<endl;
cout<<"short b address: \t"<<&b<<endl;
cout<<"double c address: \t"<<&c<<endl;
cout<<"char d address: \t"<<(void*)&d<<endl;
cout<<"double e address: \t"<<&e<<endl;
cout<<endl<<"sizeof(Test)="<<sizeof(t)<<endl;
cout<<"t address: \t"<<&t<<endl;
cout<<"t.t1 address: \t"<<(void*)&t.t1<<endl;
cout<<"t.t2 address: \t"<<&t.t2<<endl;
cout<<"t.t3 address: \t"<<&t.t3<<endl;
system("pause");
return 0;
}

栈是从高地址向低地址生长的,所以数据的地址是在减小。
为什么要进行内存对齐呢?
https://blog.csdn.net/lgouc/article/details/8235471
1.平台原因(移植原因):不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
2、 性能原因:经过内存对齐后,CPU的内存访问速度大大提升,存取未对齐的数据会花费更多的时钟周期;
http://light3moon.com/2015/01/19/%5B转%5D%20内存对齐/
内存对齐可以提升CPU效率
参考一下https://developer.ibm.com/articles/pa-dalign/
主要意思就是当内存对齐之后,CPU一次读取多个字节数据,效率高很多。
内存对齐引发的问题
参考文章: 小心内存对齐
代码中关于内存对齐的隐患,很多都是隐式的。最容易出现在强制类型转换时;
int main(){
unsigned int i=0x12345678;
unsigned char *p=(unsigned char*)&i1;
*p=0x00;
unsigned short *p1=(unsigned short*)(p+1);//p+1是奇数地址,
*p1=0x0000;
return 0;
}
最后通过p1访问时,从奇数地址访问unsigned short型变量,不符合地址对齐的规定。
处理器之间通信的数据对齐
参考https://zhuanlan.zhihu.com/p/44625744
处理器间通过消息(对于C/C++而言就是结构体)进行通信时,需要注意字节对齐以及字节序的问题
大多数编译器提供内存对齐的选项供用户使用。这样用户可以根据处理器的情况选择不同的字节对齐方式。例如C/C++编译器提供#pragma pack(n),n=1,2,4,8,…,让编译器在生成目标文件时,使内存数据按照指定的方式排序在1,2,4,8等字节整除的内存地址处。
然而在不同的编译平台或处理器上,字节对齐会造成消息结构长度的变化。编译器为了使字节对齐可能会对消息结构体进行填充,不同编译平台可能填充为不同的形式,大大增加处理器间数据通信的风险。
32位处理器为例
注意:前提是32位处理器
对于本地使用的数据结构:
为提高内存访问效率,采用四字节对齐方式;同时为了减少内存的开销,合理安排结构体成员的位置,减少四字节对齐导致的成员之间的空隙,降低内存开销。
对于处理器之间的数据结构:
需要保证消息长度不会因编译平台或处理器而导致消息结构体长度发生变化时,使用一字节对齐方式对消息结构进行压缩;
需要保证处理器之间的消息结构的内存访问效率时,采用字节填充的方式自己对消息中的成员进行四字节对齐。
数据结构的成员位置要兼顾成员之间的关系、数据访问效率和空间利用率。
顺序安排原则是:四字节的放在最前面,两字节的紧接最后一个四字节成员,一字节的紧接最后一个两字节成员,填充字节放在最后。
举例如下:
typedef struct tag_t_MSG{
long ParaA;
long ParaB;
short ParaC;
char ParaD;
char Pad;//填充字节
}T_MSG;
排查对齐问题
如果出现对齐或赋值问题可查看:
- 编译器的字节序大小端设置
- 处理器架构本身是否支持非对齐访问;
- 如果支持,则看设置对齐与否,没有对齐的话看访问时需要加某些特殊的修饰来标志其特殊访问操作
更改对齐方式
伪指令:
#pragma pack(n) :C编译器将按照n个字节对齐。
#pragma pack() :取消自定义字节对齐方式。
#pragma pack(push,1) :是指把原来对齐方式设置压栈,并设新的对齐方式设置为一个字节对齐
#pragma pack(pop) :恢复对齐状态
因此可见,加入push和pop可以使对齐恢复到原来状态,而不是编译器默认,可以说后者更优,但是很多时候两者差别不大
另外,还有如下几种方式(GCC特有语法)
- __attribute((aligned (n))),让所作用的结构成员对齐在n字节自然边界上。如果结构中有成员的长度大于n,则按照最大成员的长度来对齐。
- __attribute__ ((packed)),取消结构在编译过程中的优化对齐,按照实际占用字节数进行对齐
比如我们想让刚才的结构按一字节对齐,我们可以这样定义结构体
struct stu{
char sex;
int length;
char name[10];
}__attribute__ ((aligned (1)));
struct stu my_stu;
则sizeof(my_stu)可以得到大小为15。















 2239
2239











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









