







目录
Query DSL
术语
倒排索引
对内容进行分词,切分成不同的term
term和对应的文档列表通过id建立关系
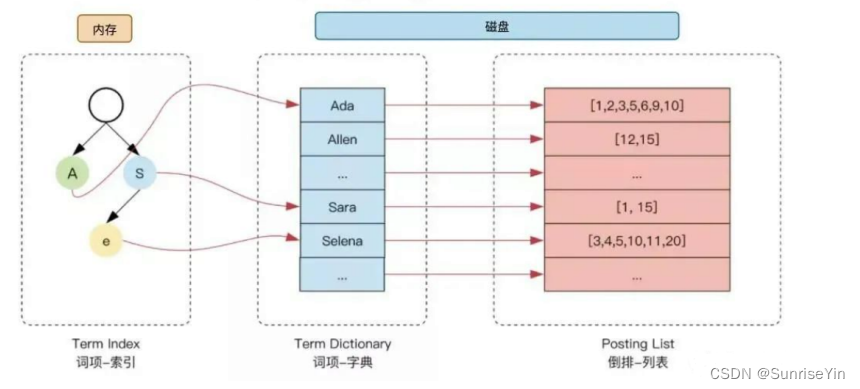
倒排索引项(Posting):
- 文档ID
- 词频TF–该单词在文档中出现的次数,用于相关性评分
- 位置(Position)-单词在文档中分词的位置。用于短语搜索(match phrase query)
- 偏移(Offset)-记录单词的开始结束位置,实现高亮显示
默认JSON文档内一个字段都会设置倒排索引,如果不用查询的字段可以指定不索引
索引映射 mapping
动态映射
动态的根据字段内容推断映射成json类型
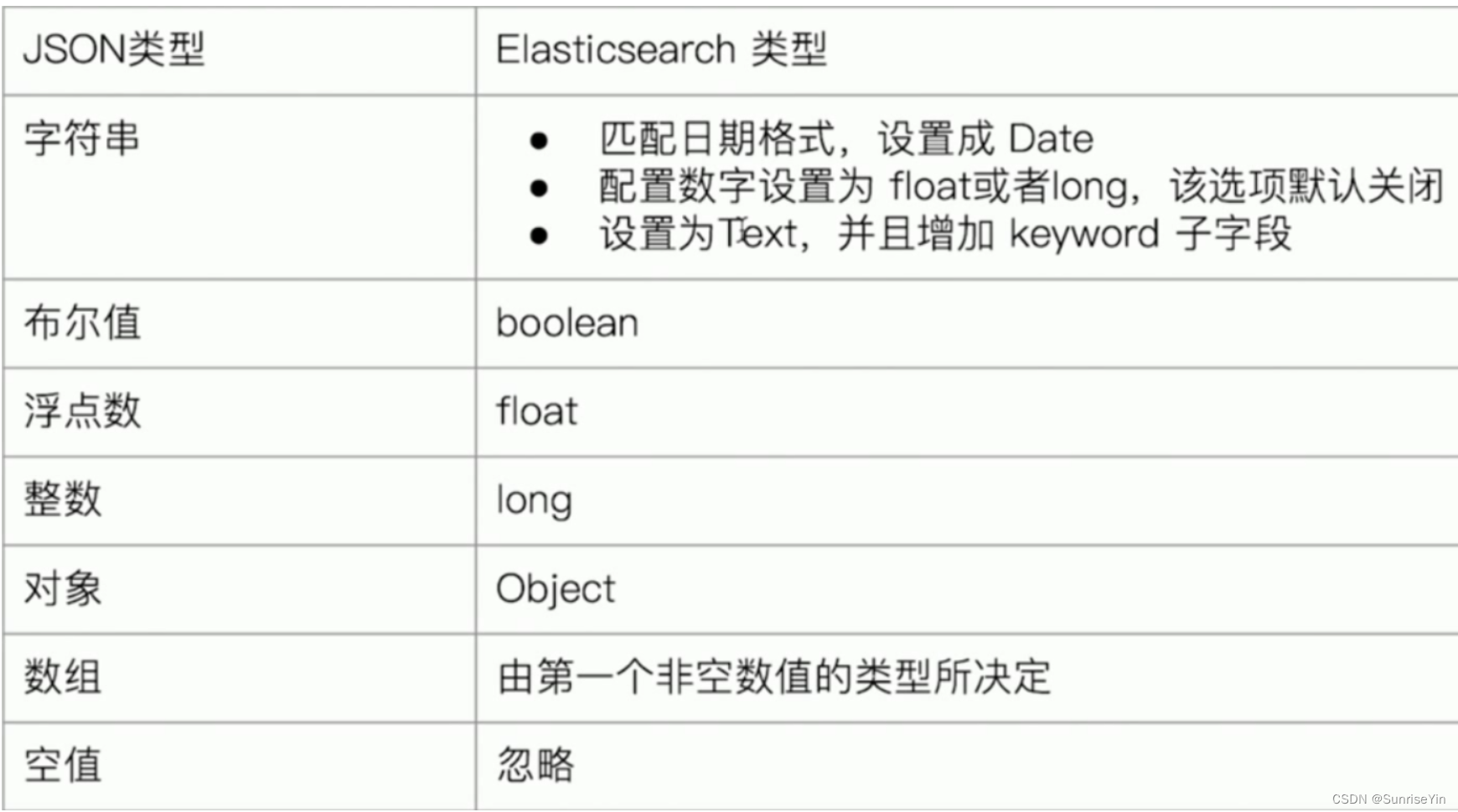
静态映射
手动指定字段类型
新增字段
根据配置有不同场景
dynamic:true 自动映射、自动索引
dynamic:false 不会自动映射、不会创建索引、会存储到内容中
dynamic: strict 写入失败,只会限制当前层级,不会限制子层级
修改映射
不支持修改映射类型
只能重建索引
- 设置一个新的索引
- 执行重建索引
POST _reindex
{
"source":{
"index":"原索引"
},
"dest":{
"index":"新索引"
}
}
- 删除原索引
- 新索引设置别名 指向原索引
禁止索引
{
"mappings":{
"properties":{
"field1":{
"index":false
}
}
}
}
查询禁止索引字段会直接返回异常信息
查询null值
正常情况下null值是不能查到的所以需要指定需要查询
PUT /user
{
"mappings" : {
"properties" : {
"address" : {
"type" : "keyword",
"null_value": "NULL"
},
"age" : {
"type" : "long"
},
"name" : {
"type" : "text"
}
}
}
}
## 查询
GET /user/_search
{
"query": {
"match": {
"address": "NULL"
}
}
}
索引模板 Index Template
Dynamic Template
Dynamic Tempate定义在某个索引的Mapping中。
PUT my_index/_doc/1
{
"firstName":"Ruan",
"isVIP":"true"
}
动态映射会把isVIP映射为text格式
如果想把这类 is开头内容为 "true"的映射为boolean类型
则可以使用Dynamic Template
PUT my_index
{
"mappings": {
"dynamic_templates": [
{
"strings_as_boolean": {
"match_mapping_type": "string",
"match":"is*",
"mapping": {
"type": "boolean"
}
}
},
{
"strings_as_keywords": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
]
}
}
Query DSL
批量查询
#等同于
GET /es_db/_search
{
"query":{
"match_all":{}
},
"size": 100
}
默认不能超过10000条,否则报错
分页查询
GET /es_db/_search
{
"query": {
"match_all": {}
},
"size": 5,
"from": 0
}
这种分页是在内存中分页,大数据量有性能问题
所以一般使用游标分页
#查询命令中新增scroll=1m,说明采用游标查询,保持游标查询窗口一分钟。
#这里由于测试数据量不够,所以size值设置为2。
#实际使用中为了减少游标查询的次数,可以将值适当增大,比如设置为1000。
GET /es_db/_search?scroll=1m
{
"query": { "match_all": {}},
"size": 100
}
这个查询会返回一个游标和100条数据
下次查询带上游标即可
#scroll_id 的值就是上一个请求中返回的 _scroll_id 的值
GET /_search/scroll
{
"scroll": "1m",
"scroll_id" : "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFmNwcVdjblRxUzVhZXlicG9HeU02bWcAAAAAAABmzRY2YlV3Z0o5VVNTdWJobkE5Z3MtXzJB"
}
排序
GET /es_db/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": "desc"
}
]
}
只返回指定字段
#_source 关键字: 是一个数组,在数组中用来指定展示那些字段
GET /es_db/_search
{
"query": {
"match_all": {}
},
"_source": ["name","address"]
}
分词后匹配 match
match 先对查询数据分词然后按分词结果查找
match支持以下参数
- query : 指定匹配的值
- operator : 匹配条件类型
and : 条件分词后都要匹配
or : 条件分词后有一个匹配即可(默认) - minmum_should_match : 最低匹配度,即条件在倒排索引中最低的匹配度
#分词后 and的效果
GET /es_db/_search
{
"query": {
"match": {
"address": {
"query": "广州白云山公园",
"operator": "AND"
}
}
}
}
#最少匹配广州,公园两个词
GET /es_db/_search
{
"query": {
"match": {
"address": {
"query": "广州公园",
"minimum_should_match": 2
}
}
}
}
短语查询match_phrase
match_phrase 会将搜索内容分词。
查询结果必须在被检索字段的分词中都包含,而且顺序必须相同,而且默认必须都是连续的
GET /es_db/_search
{
"query": {
"match_phrase": {
"address": "广州白云山"
}
}
}
#分词为 广州 白云山
#只能查出来 广州白云山
#不能出来 广州白云
#如果需求确定固定间隔、则可以配置
#广州云山分词后相隔为2,可以匹配到结果
GET /es_db/_search
{
"query": {
"match_phrase": {
"address": {
"query": "广州云山",
"slop": 2
}
}
}
}
多字段查询multi_match
#如果字段类型分词则分词后查询
#如果字段类型不分词则整体查询
GET /es_db/_search
{
"query": {
"multi_match": {
"query": "测试字典",
"fields": [
"title",
"content"
]
}
}
}
query_string
可以指定多个关键字查询
并且可以指定关键词之间的关系(AND | OR | NOT)
并且默认在所有字段中查询
GET /es_db/_search
{
"query": {
"query_string": {
"query": "张三 OR 橘子洲"
}
}
}
#指定单个字段查询
GET /es_db/_search
{
"query": {
"query_string": {
"default_field": "address",
"query": "白云山 OR 橘子洲"
}
}
}
#指定多个字段查询
GET /es_db/_search
{
"query": {
"query_string": {
"fields": ["name","address"],
"query": "张三 OR (广州 AND 王五)"
}
}
}
关键词查询Term
Term查询不分词是精确查找、只是对查询字段不分词
在ES的Mapping Type 中 keyword , date ,integer, long , double , boolean or ip 这些类型不分词,只有text类型分词。
#采用term精确查询, 查询字段映射类型为keyword
GET /es_db/_search
{
"query":{
"term": {
"address.keyword": {
"value": "广州白云山公园"
}
}
}
}
#如果对一个英文单词分词后会转化为小写,那么有些时候就不能查询出来
#可以手动设置忽略大小写
# 对于英文,可以考虑建立索引时忽略大小写
PUT /product
{
"settings": {
"analysis": {
"normalizer": {
"es_normalizer": {
"filter": [
"lowercase",
"asciifolding"
],
"type": "custom"
}
}
}
},
"mappings": {
"properties": {
"productId": {
"type": "text"
},
"productName": {
"type": "keyword",
"normalizer": "es_normalizer",
"index": "true"
}
}
}
}
#既然精确查找了就不需要算分了可以提交性能
GET /es_db/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"address.keyword": "广州白云山公园"
}
}
}
}
}
#term处理多值字段,term查询是包含,不是等于
POST /employee/_bulk
{"index":{"_id":1}}
{"name":"小明","interest":["跑步","篮球"]}
{"index":{"_id":2}}
{"name":"小红","interest":["跳舞","画画"]}
{"index":{"_id":3}}
{"name":"小丽","interest":["跳舞","唱歌","跑步"]}
POST /employee/_search
{
"query": {
"term": {
"interest.keyword": {
"value": "跑步"
}
}
}
}
精确搜索
应用场景:对bool,日期,数字,结构化的文本可以利用term做精确匹配
GET /es_db/_search
{
"query": {
"term": {
"age": {
"value": 28
}
}
}
}
前缀所有
#和数据库查询不同 es前缀查询并没有优化多少性能
GET /es_db/_search
{
"query": {
"prefix": {
"address": {
"value": "广州"
}
}
}
}
通配符查询wildcard
#模糊查询
GET /es_db/_search
{
"query": {
"wildcard": {
"address": {
"value": "*白*"
}
}
}
}
日期range
GET /product/_search
{
"query": {
"range": {
"date": {
"gte": "now-2y"
}
}
}
}
模糊查询fuzzy
#可以输错一个字
#最大只允许输错2个字在搜索词长度大于5的时候
GET /es_db/_search
{
"query": {
"match": {
"address": {
"query": "广洲",
"fuzziness": 1
}
}
}
}
高亮
GET /products/_search
{
"query": {
"term": {
"name": {
"value": "牛仔"
}
}
},
"highlight": {
"fields": {
"*":{}
}
}
}
#自定义高亮html标签
#可以在highlight中使用pre_tags和post_tags
GET /products/_search
{
"query": {
"term": {
"name": {
"value": "牛仔"
}
}
},
"highlight": {
"post_tags": ["</span>"],
"pre_tags": ["<span style='color:red'>"],
"fields": {
"*":{}
}
}
}
#多字段高亮
GET /products/_search
{
"query": {
"term": {
"name": {
"value": "牛仔"
}
}
},
"highlight": {
"pre_tags": ["<font color='red'>"],
"post_tags": ["<font/>"],
"require_field_match": "false",
"fields": {
"name": {},
"desc": {}
}
}
}















 968
968











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









