







虎扑里有个大神叫科比ni很帅,他的虎扑相册里有很多科比的精美gif,其质量之高,内容之广,虎扑中无出其右。无奈图片数量太大,如果一张一张右键保存工作量相当可观。之前我也写过抓取虎扑帖子上图片的程序。奈何虎扑相册需要登录才能查看,于是我利用周末的时间学习了一下python的模拟登录,写了个小程序。由于初学,程序可能比较渣,有大神路过希望能给与指导,如果也有初学者路过,欢迎一同探讨。
首先要登录肯定要Post一些信息给服务器,登录虎扑还比较简单,每次登录都会把你带到登录页面:http://passport.hupu.com/login。然后我们就用Firebug这个插件在Firefox上看看我们到底发送了什么数据。
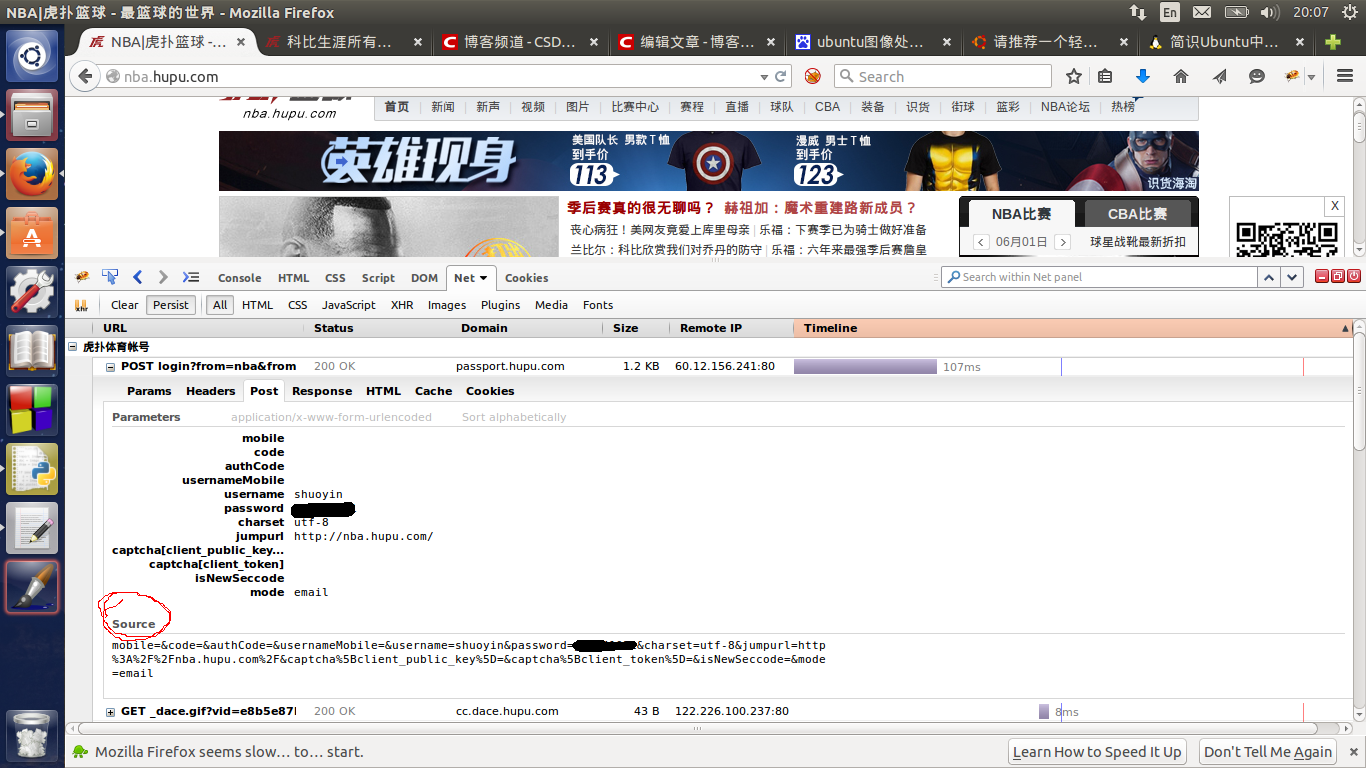
被我涂抹掉的部分是我的密码。我们要发送的数据已经就是用红圈圈起来的Source下边的内容。其实如果不利用cookielib,直接向虎扑发送这些数据就能实现登录,但是这样的话,我们只能获得登录成功界面,这是没什么用的。我们要带着登录信息在网页上浏览才能看到人家的相册。
我们建立一个CookieJar的对象,用于收集cookie,然后建立一个能够处理cookie的opener,这样就完成了主要部分,剩下的就是解析获得的HTML文件,用HTMLParser还是正则表达式就随意了,我一般是网页中稀少的东西用正则表达式提取,如果网页中比较多就用HTMLParser。下边把代码贴上来吧。
import urllib2
import cookielib
import re
import os
from HTMLParser import HTMLParser
class Photo(HTMLParser):
header={\
'User-Agent' : 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:36.0) Gecko/20100101 Firefox/36.0'\
}
def __init__(self):
HTMLParser.__init__(self)
self.opener=None
self.getOpener()
self.start=False
self.image_list=[]
def handle_starttag(self,tag,attrs):
if(tag=='div'):
if([('class','albumlist_list')] == attrs):
self.start=True
elif(self.start and tag=='a'):
if(len(attrs)==1 and 'href' in attrs[0]):
self.image_list.append(attrs[0][1])
else:
pass
def handle_endtag(self,tag):
if(self.start and tag=='div'):
self.start=False
def getOpener(self):
data='mobile=&code=&authCode=&usernameMobile=&username=shuoyin&password=*****&charset=utf-8&jumpurl=http%3A%2F%2Fnba.hupu.com%2F&captcha%5Bclient_public_key%5D=&captcha%5Bclient_token%5D=&isNewSeccode=&mode=email'
request=urllib2.Request('http://passport.hupu.com/login',data,Photo.header)#'*' represents for my password
cookie=cookielib.CookieJar()
handle=urllib2.HTTPCookieProcessor(cookie)
self.opener=urllib2.build_opener((handle))
self.opener.open(request)
def getimagelinks(self,url):
pattern='<a href="(\\S*?)" class="next">'
pattern=re.compile(pattern)
while url:
request=urllib2.Request(url,headers=Photo.header)
html=self.opener.open(request).read()
self.feed(html)
x=pattern.search(html)
url=(x!=None and 'http://my.hupu.com'+x.groups()[0] or None)
def download(self,url,save_path):
try:
os.makedirs(save_path)
except:
pass
self.image_list=[]
self.getimagelinks(url)
print self.image_list
alt=open(os.path.join(save_path,'alt.txt'),'w')
pattern=re.compile('<img id="bigpic" alt="(.*?)" src="(\\S*?)"')
for num,link in enumerate(self.image_list):
fullurl='http://my.hupu.com'+link
request=urllib2.Request(fullurl,headers=Photo.header)
html=self.opener.open(request).read()
x=pattern.findall(html)
alt.write('%d: '%num)
alt.write(x[0][0])
alt.write('\n')
try:
img=urllib2.urlopen(x[0][1]).read()
except urllib2.URLError,e:
print '%d Failed, reason: '%num,e
continue
imgname='%d.'%num+x[0][1][-3:]
saveimg=open(os.path.join(save_path,imgname),'w+b')
saveimg.write(img)
saveimg.close()
if __name__=="__main__":
m=Photo()
url=raw_input('Please enter the url of the album:\n')
path=raw_input('please enter the path you want to keep them:\n')
m.download(url,path)样例输入:
http://my.hupu.com/4636142/photo/a143789.html
/home/yinshuo/kobe/clutch
由于程序写的不是很健壮,所以只能接受完整的URL和完整的路径。并且受制于我的可怜的网络知识,只能是相册第一页(也就是一个相册的根目录)
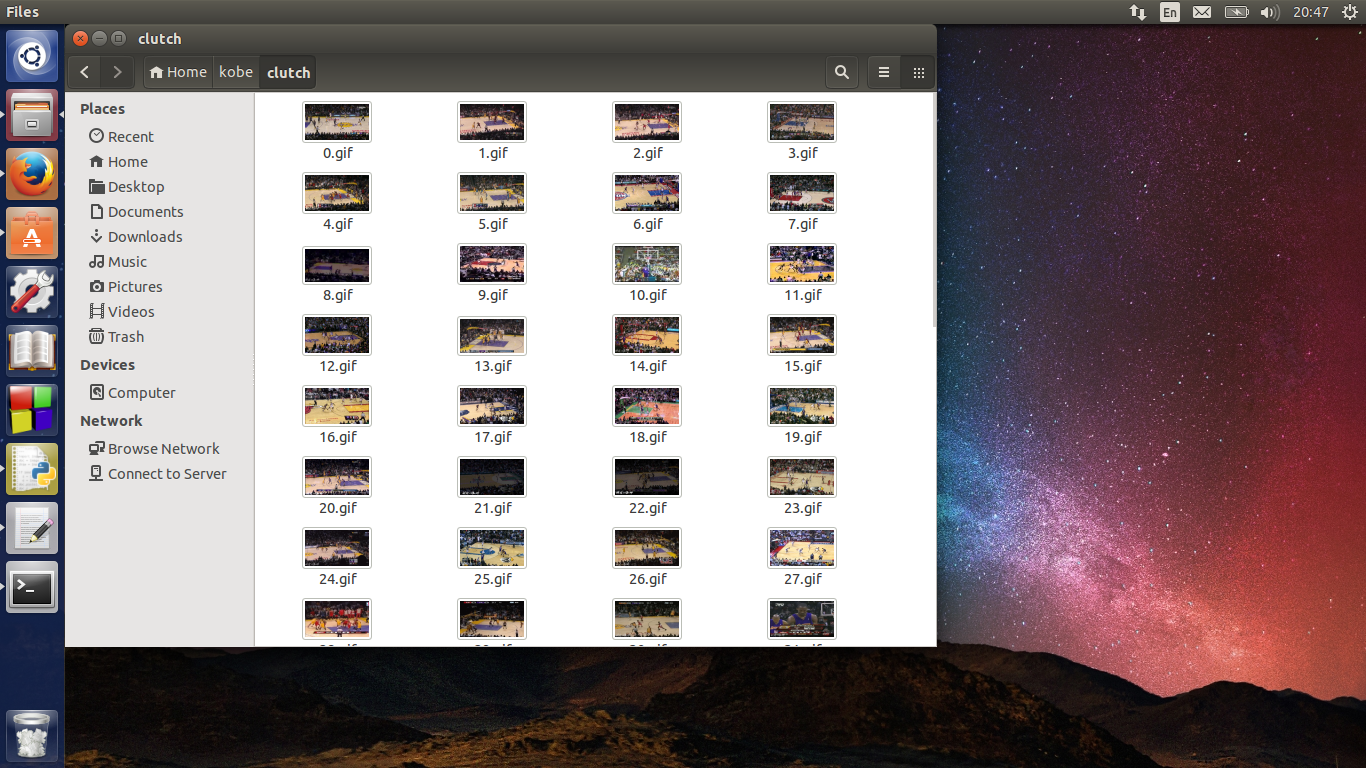
另外,每个相册打开之后都会有一个图片处于选中状态,造成这个图片无法被我的程序识别出来,我不想为了这一个图片而加入一个特例,又没有想出一个好的方法。所以现在这个程序有个bug,谁有好的方法希望能教教我。下边是下载完成之后的效果。















 335
335

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









