







4. MongoDB部署
4.1 可复制集
可复制集是跨多个 MongDB 服务器(节点)分布和维护数据的方法。mongoDB 可以把数据 从一个节点复制到其他节点并在修改时进行同步,集群中的节点配置为自动同步数据;旧方 法叫做主从复制,mongoDB 3.0 以后推荐使用可复制集;
为什么要用可复制集?它有什么重要性?
-
避免数据丢失,保障数据安全,提高系统安全性; (最少 3 节点,最大 50 节点)
-
自动化灾备机制,主节点宕机后通过选举产生新主机;提高系统健壮性;(7 个选举节点上限)
-
读写分离,负载均衡,提高系统性能;
-
生产环境推荐的部署模式;
4.4.1. 可复制集架构以及原理
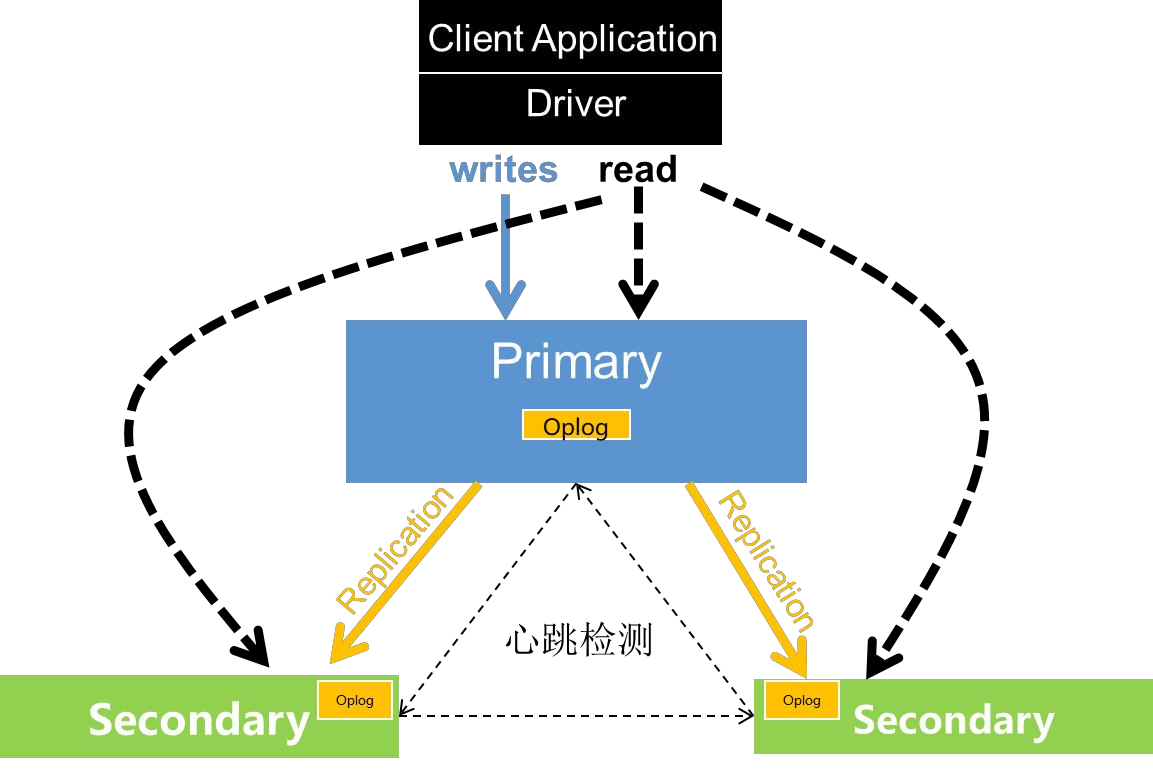
-
oplog(操作日志):保存操作记录、时间戳
-
数据同步:从节点与主节点保持长轮询;1.从节点查询本机 oplog 最新时间戳;2.查询主节点 oplog 晚于此时间戳的所有文档;3.加载这些文档,并根据 log 执行写操作;
-
阻塞复制:与 writeconcern 相关,不需要同步到从节点的策略(如: acknowledged Unacknowledged 、w1),数据同步都是步的,其他情况都是同步;
-
心跳机制:成员之间会每 2s 进行一次心跳检测(ping 操作),发现故障后进行选举和故障转移;
-
选举制度:主节点故障后,其余节点根据优先级和 bully 算法选举出新的主节点,在选出主节点之前,集群服务是只读的
oplog 是盖子集合,大小是可以调整的,默认是所在硬盘 5%;
https://docs.mongodb.com/manual/reference/configuration-options/
4.4.2. 可复制集的搭建过程
安装好 3 个以上节点的 mongoDB;
# 创建三个db目录
mkdir ./data/{db1,db2,db3}
# 创建三个log目录
mkdir ./log/{log1,log2,log3}
# 创建三个配置目录
mkdir -r ./conf/{node1,node2,node3}
# 同时复制配置到三个目录中
echo ./conf/node1 ./conf/node2 ./conf/node3 | xargs -n 1 cp -v ./conf/mgdb.conf
# 修改端口, db,log路径配置
vim ./conf/node1/mgdb.conf
下面是老版本的配置方式
#数据文件存放目录
dbpath=/root/mongo/mongo/data/db1
#日志文件存放目录
logpath=/root/mongo/mongo/log/log1/mongodb.log
#端口,默认 27017,可以自定义, 避免和本地的27017端口冲突导致连接不上远程的mongo服务
port=27018
#开启日志追加添加日志
logappend=true
#以守护程序的方式启用,即在后台运行
fork=true
#本地监听 IP,0.0.0.0 表示本地所有 IP
bind_ip=0.0.0.0
#是否需要验证权限登录(用户名和密码)
auth=false
下面是新版本的配置
storage:
dbPath: "/root/mongo/mongo/data/db1"
systemLog:
destination: file
path: "/root/mongo/mongo/log/log1/mongodb.log"
net:
bindIp: 0.0.0.0
port: 27017
processManagement:
fork: true
setParameter:
enableLocalhostAuthBypass: false
按照新版本配置复制集
配置 mgdb.conf,增加跟复制相关的配置如下:
replication:
replSetName: configRS //集群名称
oplogSizeMB: 50 //oplog集合大小
启动命令
mongod --config ./mongo/conf/node1/mgdb.conf &
mongod --config ./mongo/conf/node2/mgdb.conf &
mongod --config ./mongo/conf/node3/mgdb.conf &
在主节点配置
在 primary 节点切换到 admin 库上运行可复制集的初始化命令,初始化可复制集,命令如下: mongo --port 27018
注意: mongo -p 27018 是一个错误命令, 如果你本地启动了一个27017的mongo进程, 那么, 这个命令可以进入, 但是她进入的不是复制集, 是使用27017端口的那个进程
rs: replica set
rs.initiate({ _id: "configRS", version: 1, members: [{ _id: 0, host : "192.168.125.132:27018" }]}); rs.add("192.168.125.132:27019"); //有几个节点就执行几次方法
rs.add("192.168.125.132:27020"); //有几个节点就执行几次方法
-
在每个节点运行 rs.status()或 rs.isMaster()命令查看复制集状态;
-
测试数据复制集效果;
-
测试故障失效转移效果;
只能在主节点查询数据,但如果想在副节点查询到数据需运行 rs.slaveOk();
不执行rs.slaveOk()将会报错 not master and slaveOk=false
configRS:SECONDARY> show dbs
2022-08-24T07:48:42.162-0700 E QUERY [js] Error: listDatabases failed:{
"operationTime" : Timestamp(1661352516, 1),
"ok" : 0,
"errmsg" : "not master and slaveOk=false",
"code" : 13435,
"codeName" : "NotMasterNoSlaveOk",
"$clusterTime" : {
"clusterTime" : Timestamp(1661352516, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
} :
4.4.3. JAVA 代码连接
4.4.3.1. java 原生驱动开发
List<ServerAddress> asList = Arrays.asList(
new ServerAddress("192.168.125.132", 27018),
new ServerAddress("192.168.125.132", 27020),
new ServerAddress("192.168.125.132", 27019));
MongoClient client = new MongoClient(asList);
**注意:**MongoDB 复制集里 Primary 节点是不固定的,不固定的,不固定的!所以生产环境千万不要直连 Primary,千万不要直连 Primary,千万不要直连 Primary!
//连接客户端(内置连接池)
private MongoClient client;
@Before
public void init() {
/*client = new MongoClient("localhost", 27017);*/
List<ServerAddress> asList =
Arrays.asList(new ServerAddress("localhost", 27018), new ServerAddress("localhost", 27017),
new ServerAddress("localhost", 27019));
client = new MongoClient(asList);
/* client = new MongoClient("localhost", 27031);*/
db = client.getDatabase("lison");
doc = db.getCollection("users");
}
4.4.3.2. Spring 配置开发
<mongo:mongo-client replica-set="192.168.125.132:27018,192.168.125.132:27019,192.168.125.132:27020"/>
配置 Tips:
- 关注 Write Concern 参数的设置,默认值 1 可以满足大多数场景的需求。W 值大于 1 可以 提高数据的可靠持久化,但会降低写性能。
- 在 options 里添加 readPreference=secondaryPreferred 即可实现读写分离,读请求优先到 Secondary 节点,从而实现读写分离的功能
@Bean(name="mongo")
public MongoClient mongoClient() {
WriteConcern wc = WriteConcern.W1.withJournal(true);
MongoClientOptions mco = MongoClientOptions.builder()
.writeConcern(wc)
.connectionsPerHost(100)
.readPreference(ReadPreference.secondary()) // 读写分离配置
.threadsAllowedToBlockForConnectionMultiplier(5)
.maxWaitTime(120000).connectTimeout(10000).build();
List<ServerAddress> asList = Arrays.asList(
new ServerAddress("localhost", 27017));
MongoClient client = new MongoClient(asList, mco);
return client;
}
4.5. 分片集群
分片是把大型数据集进行分区成更小的可管理的片,这些数据片分散到不同的mongoDB节点, 这些节点组成了分片集群。
例如: 一个完整的数据库集由三个分片组成, 这三个分片可以位于三个不同的主机上, 所以同样空间的机器, 通过三个机器, 可以把系统的可存放量扩大三倍, 如果我们的一个分片有两个可复制集, 那么就需要9个数据节点, 可以提高数据安全性和读取速度
所以通过分片我们可以计算没有复制集时候的系统最多可存储数据量: 系统磁盘可用空间*分片数
如果有两个复制集就除以3
为什么要用分片集群?
-
数据海量增长,需要更大的读写吞吐量 → 存储分布式
-
单台服务器内存、cpu 等资源是有瓶颈的 → 负载分布式
Tips:分片集群是个双刃剑,在提高系统可扩展性和性能的同时,增大了系统的复杂性,所以在实施之前请确定是必须的。
4.5.1. 分片到底是分的什么鬼?
数据库?集合?文档?mongoDB 分片集群推荐的模式是:分片集合,它是一种基于分片键的 逻辑对文档进行分组,分片键的选择对分片非常重要,分片键一旦确定,mongoDB 对数据的分 片对应用是透明的;
以 Order 为例,使用 useCode 作为分片键
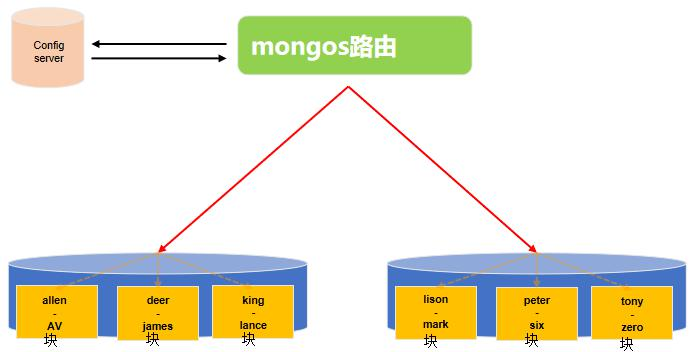
Tips:
随着数据量的的增大,分片会分割和迁移,以满足数据的均匀分布。
-
请求分流:通过路由节点将请求分发到对应的分片和块中;
-
数据分流:内部提供平衡器保证数据的均匀分布,数据平均分布式请求平均分布的前提;
-
块的拆分:3.4 版本块的最大容量为 64M 或者 10w 的数据,当到达这个阈值,触发块的拆分,一分为二;
-
块的迁移:为保证数据在分片节点服务器分片节点服务器均匀分布,块会在节点之间迁移。一般相差 8 个分块的时候触发;
4.5.2. 分片集群架构图与组件
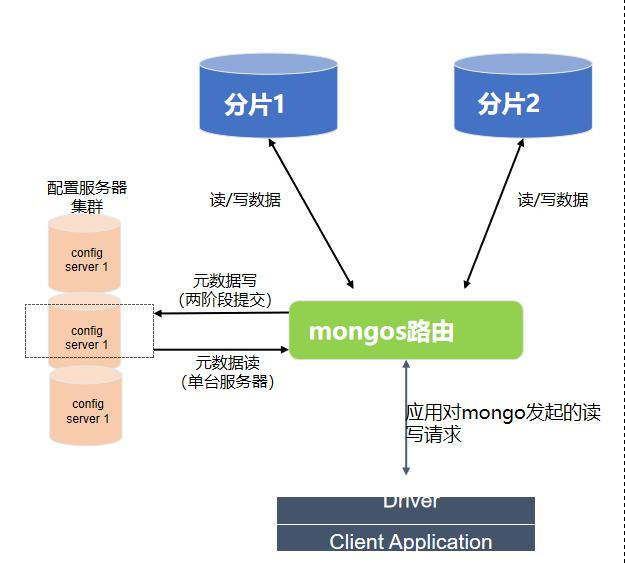
- 分片
在集群中唯一存储数据的位置,可以是单个 mongo 服务器,也可以是可复制集,每个分区上存 储部分数据;生产环境推荐使用可复制集
- mongos 路由
由于分片之存储部分数据,需要 mongos 路由将读写操作路由到对应的分区上; mongos 提供了单点连接集群的方式,轻量级、非持久化所以通常 mongos 和应用部署在同一 台服务器上;
- 配置服务器
存储集群的元数据,元数据包括:数据库、集合、分片的范围位置以及跨片数据分割和迁移的 日志信息;mongos 启动时会从配置服务器读取元数据信息在内存中;配置服务器最低 3 台;
4.5.3. 分片搭建过程
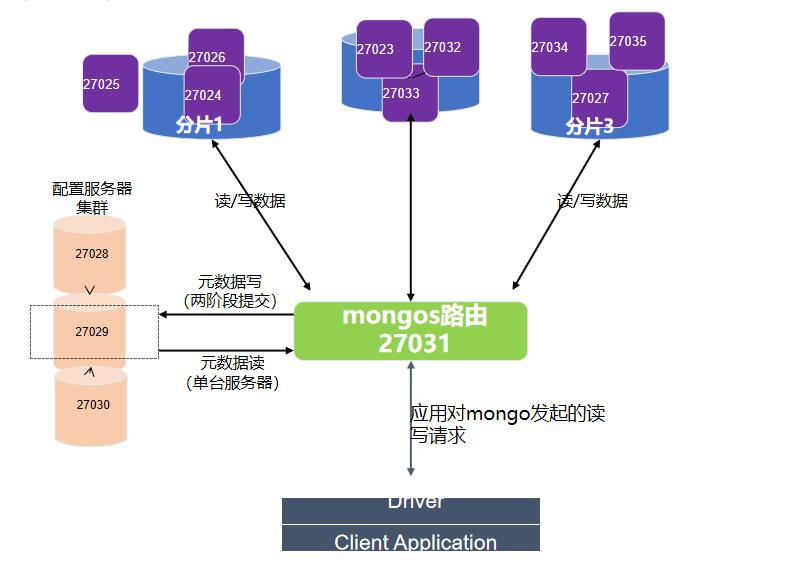
4.5.3.1. 分片服务器配置
分片 1(27024,27025,27026) 一个master两个复制集
配置文件
其中的一个节点
storage:
dbPath: "/soft/mongosplit/node27024/db"
systemLog:
destination: file
path: "/soft/mongosplit/node27024/logs/mongodb.log"
net:
port: 27024
bindIp: 127.0.0.1,192.168.244.123
processManagement:
fork: true
setParameter:
enableLocalhostAuthBypass: false
# 复制集配置
replication: replSetName: configRS
oplogSizeMB: 50
# 分片配置
sharding:
clusterRole: shardsvr
启动
mongod --config ./node27024/mgdb.conf
mongod --config ./node27025/mgdb.conf
mongod --config ./node27026/mgdb.conf
配置复制集
mongo --port 27024
切换 admin 数据库
use admin
运行如下命令
rs.initiate({ _id: "configRS", version: 1, members: [{ _id: 0, host : "192.168.244.123:27024" }]});
rs.add("192.168.244.123:27025");//有几个节点就执行几次方法
rs.add("192.168.244.123:27026");//有几个节点就执行几次方法
分片 2 (27023,27032,27033)
略
分片 3 (27027,27034,27035)
略
4.5.3.2. Config 服务器
服务器 1 (27028)
vi ./node27028/mgdb.conf
storage:
dbPath: "/soft/mongosplit/node27028/db"
systemLog:
destination: file
path: "/soft/mongosplit/node27028/logs/mongodb.log"
net:
port: 27028
bindIp: 127.0.0.1,192.168.244.123
processManagement:
fork: true
setParameter:
enableLocalhostAuthBypass: false
replication:
replSetName: editRS
oplogSizeMB: 50
sharding: clusterRole: configsvr
启动
mongod --config ./node27028/mgdb.conf
服务器 2 (27029)
略
服务器 3 (27030)
略
配置 Config 复制集
mongo --port 27028
use admin
rs.initiate({
_id: "editRS",
version: 1,
members: [{
_id: 0,
host: "192.168.244.123:27028"
}]
});
rs.add("192.168.244.123:27029"); //有几个节点就执行几次方法
rs.add("192.168.244.123:27030");
4.5.3.3. mongos 路由(20731)
注意: 路由启动的服务是mongos进程, 不是mongod进程
配置文件
vi ./node27031/mgdb.conf
systemLog:
destination: file
path: "/soft/mongosplit/node27031/logs/mongodb.log"
net:
port: 27031
bindIp: 127.0.0.1,192.168.244.123
processManagement:
fork: true
setParameter:
enableLocalhostAuthBypass: false
sharding:
configDB: editRS/192.168.244.123:27028,192.168.244.123:27029,192.168.244.123:27030
启动
mongos --config ./node27031/mgdb.conf &
配置 sharding
mongo --port 27031
增加分区
use admin;
sh.addShard("configRS2/192.168.244.123:27023,192.168.244.123:27032,192.168.244.123:27033 ");
sh.addShard("configRS3/192.168.244.123:27027,192.168.244.123:27034,192.168.244.123:27035 "); //configRS 这个是复制集的名称
sh.addShard("configRS/192.168.244.123:27024,192.168.244.123:27025,192.168.244.123:27026");
-
对 lison 数据库启用分片:sh.enableSharding(“lison”)
-
对 ordersTest 集合进行分片,分片键为 sh.shardCollection(“lison.orders”,{“useCode”:“hashed”});
删除分片
db.runCommand( { removeShard: "xxx" } )
分片状态
sh.status()
4.5.4. 分片注意点与建议
分片注意点:
-
热点 :某些分片键会导致所有的读或者写请求都操作在单个数据块或者分片上,导致单 个分片服务器严重不堪重负**。自增长的分片键容易导致写热点问题;**
-
不可分割数据块:过于粗粒度的分片键可能导致许多文档使用相同的分片键,这意味着这些文档不能被分割为多个数据块,限制了 mongoDB 均匀分布数据的能力;
-
查询障碍:分片键与查询没有关联,造成糟糕的查询性能。
建议:
-
不要使用自增长的字段作为分片键,避免热点问题;
-
不能使用粗粒度的分片键,避免数据块无法分割;
-
不能使用完全随机的分片键值,造成查询性能低下;
-
使用与常用查询相关的字段作为分片键,而且包含唯一字段(如业务主键,id 等);
-
索引对于分区同样重要,每个分片集合上要有同样的索引,分片键默认成为索引;分片集合只允许在 id 和分片键上创建唯一索引;
关于事务
https://docs.mongodb.com/v4.0/core/transactions/index.html
4.6.最佳实践
-
尽量选取稳定新版本 64 位的 mongodb;
-
数据模式设计;提倡单文档设计,将关联关系作为内嵌文档或者内嵌数组;当关联数据 量较大时,考虑通过表关联实现,dbref 或者自定义实现关联;
-
避免使用 skip 跳过大量数据;(1)通过查询条件尽量缩小数据范围;(2)利用上一次的结果作为条件来查询下一页的结果;
-
避免单独使用不适用索引的查询符( n e 、 ne、 ne、nin、$where 等)
-
根据业务场景,选择合适的写入策略,在数据安全和性能之间找到平衡点;
-
索引建议很重要;
-
生产环境中建议打开 profile,便于优化系统性能;
-
生产环境中建议打开 auth 模式,保障系统安全;
-
不要将 mongoDB 和其他服务部署在同一台机器上(mongodb 占用的最大内存是可以配置的);
-
单机一定要开启 journal 日志,数据量不太大的业务场景中,推荐多机器使用副本集,并开启读写分离;
-
分片键的注意事项
















 1175
1175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











