







Flume
目录
Flume是由Cloudera软件公司提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,后与2009年被捐赠了apache软件基金会,为hadoop相关组件之一。尤其近几年随着flume的不断被完善以及升级版本的逐一推出,特别是flume-ng;同时flume内部的各种组件不断丰富,用户在开发的过程中使用的便利性得到很大的改善,现已成为apache top项目之一。
apache Flume 是一个从可以收集例如日志,事件等数据资源,并将这些数量庞大的数据从各项数据资源中集中起来存储的工具/服务。flume具有高可用,分布式,配置工具,其设计的原理也是基于将数据流,如日志数据从各种网站服务器上汇集起来存储到HDFS,HBase等集中存储器中。
1 Flume概述
Flume是由Cloudera软件公司提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,后与2009年被捐赠了apache软件基金会,为hadoop相关组件之一。尤其近几年随着flume的不断被完善以及升级版本的逐一推出,特别是flume-ng;同时flume内部的各种组件不断丰富,用户在开发的过程中使用的便利性得到很大的改善,现已成为apache top项目之一。
apache Flume 是一个从可以收集例如日志,事件等数据资源,并将这些数量庞大的数据从各项数据资源中集中起来存储的工具/服务。flume具有高可用,分布式,配置工具,其设计的原理也是基于将数据流,如日志数据从各种网站服务器上汇集起来存储到HDFS,HBase等集中存储器中。
1)flume的可靠性
Flume提供了三种级别的可靠性保障,从强到弱依次分别为:end-to-end(收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送。),Store on failure(这也是scribe采用的策略,当数据接收方crash时,将数据写到本地,待恢复后,继续发送),Besteffort(数据发送到接收方后,不会进行确认)。
2)flume的可恢复性
flume可通过Channel对事件数据进行恢复,推荐使用FileChannel,事件持久化在本地文件系统里(性能较差)。
2 Flume的核心结构
Flume 运行的核心是 Agent。Flume以agent为最小的独立运行单位。一个agent就是一个JVM。它是一个完整的数据收集工具,含有三个核心组件,分别是source、channel、 sink。通过这些组件,Event 可以从一个地方流向另一个地方,如图2-1所示。

图2-1 Agent结构
2.1 Source
Source是数据的收集端,负责将数据捕获后进行特殊的格式化,将数据封装到事件(event) 里,然后将事件推入Channel中。 Flume提供了很多内置的Source, 支持 Avro, log4j, syslog 和 http post(body为json格式)。可以让应用程序同已有的Source直接打交道,如AvroSource、SyslogTcpSource。 如果内置的Source无法满足需要, Flume还支持自定义Source。如图2-2所示:

图2-2 Source类型
2.2 Channel
Channel是连接Source和Sink的组件,可以将它看做一个数据的缓冲区(数据队列),它可以将事件暂存到内存中也可以持久化到本地磁盘上, 直到Sink处理完该事件。介绍两个较为常用的Channel,MemoryChannel和FileChannel。Channel类型如图2-3所示:

图2-3 Channel类型
2.3 Sink
Sink从Channel中取出事件,然后将数据发到别处,可以向文件系统、数据库、 hadoop存数据,也可以是其他agent的Source。在数据较少时,可以将数据存储在文件系统中,并且设定一定的时间间隔保存数据。Sink类型如图2-4所示:

3 Flume拦截器、数据流
3.1 Flume拦截器
当我们需要对数据进行过滤时,除了我们在Source、 Channel和Sink进行代码修改之外, Flume为我们提供了拦截器,拦截器也是chain形式的。拦截器的位置在Source和Channel之间,当我们为Source指定拦截器后,我们在拦截器中会得到event,根据需求我们可以对event进行保留还是抛弃,抛弃的数据不会进入Channel中。如图2-5所示
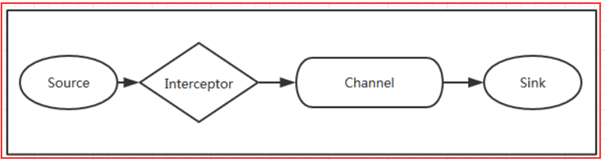
3.2 Flume数据流
Flume 的核心是把数据从数据源收集过来,再送到目的地。为了保证输送一定成功,在送到目的地之前,会先缓存数据,待数据真正到达目的地后,删除自己缓存的数据。Flume 传输的数据的基本单位是 Event,如果是文本文件,通常是一行记录,这也是事务的基本单位。 Event 从 Source,流向 Channel,再到 Sink,本身为一个 byte 数组,并可携带 headers 信息。 Event 代表着一个数据流的最小完整单元,从外部数据源来,向外部的目的地去。
Flume提供了大量内置的Source、Channel和Sink类型。不同类型的Source,Channel和Sink可以自由组合。组合方式基于用户设置的配置文件,非常灵活。比如:Channel可以把事件暂存在内存里,也可以持久化到本地硬盘上。Sink可以把日志写入HDFS, HBase,甚至是另外一个Source等等。Flume支持用户建立多级流,也就是说,多个agent可以协同工作,并且支持Fan-in、Fan-out、Contextual Routing、Backup Routes,这也正是Flume强大之处。如图2-6所示:

4 Flume实例
4.1 单个Flume
单个Flume以netcat作为输入源,以log作为sink,具体实现步骤如下:
1上传Flume安装包到/home/tools,解压,解压后移动到/home下。重命名,并修改flume-env.sh,如下图所示:
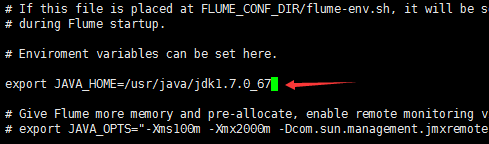
2 在/etc/profile文件目录配置Flume的环境变量,如图2-8所示:

3 在/home下创建tests_flume, 并创建flume配置文件flume1,如图2-9所示:

4 命令” flume-ng agent --conf /home/test_flume --conf-file /home/test_flume/flume1 --name a1 -Dflume.root.logger=INFO,console”测试Flume是否安装成功,如图2-10所示:

5 安装telnet,并在telnet控制台输入“hi flume”,如图2-11所示:
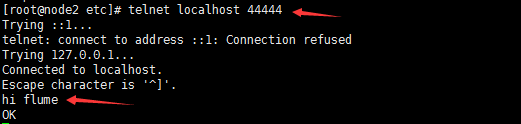
6 切换flume控制台查看结果,如图2-12所示:

4.2 Flume集群
我们以两台服务器(node1、node2)形成Flume集群,其中node1的Sink作为node2的sink,具体架构如下图所示:
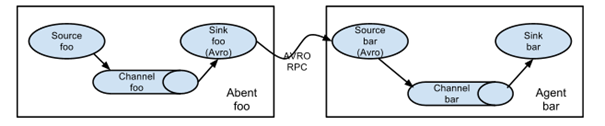
该实例的具体步骤如下:
1 node1,node2,上传压缩包到/home/tools下,解压。
2修改conf下的flume-env.sh中的java环境变量。
3在/etc/profile下配置Flume的环境变量。
4 node1,node2下创建测试目录test_flume,并分别在node1,node2下创建配置文件flume21,flume22,如下图所示:


5 node1,node2分别启动flume(注意因为node2在后面,所以先启动node2中flume,再启动node1中flume)
①先启动node02的Flume
flume-ng agent -n a1 -c conf -f avro.conf -Dflume.root.logger=INFO,console
flume-ng agent -n a1 -c conf -f /home/test_flume/flume22 -Dflume.root.logger=INFO,console
②再启动node01的Flume
flume-ng agent -n a1 -c conf -f simple.conf2 -Dflume.root.logger=INFO,console
flume-ng agent -n a1 -c conf -f /home/test_flume/flume21 -Dflume.root.logger=INFO,console
6 打开telnet测试,node2输出结果。
5 小结
(1)Flume具有的优点:
1. Flume可以将应用产生的数据存储到任何集中存储器中,比如HDFS,HBase
2. 当收集数据的速度超过将写入数据的时候,也就是当收集信息遇到峰值时,这时候收集的信息非常大,甚至超过了系统的写入数据能力,这时候,Flume会在数据生产者和数据收容器间做出调整,保证其能够在两者之间提供一共平稳的数据.
3. Flume的管道是基于事务,保证了数据在传送和接收时的一致性.
4. Flume是可靠的,容错性高的,可升级的,易管理的,并且可定制的。
5.实时性,Flume有一个好处可以实时的将分析数据并将数据保存在数据库或者其他系统中。
(2)缺点
与logstash相比,Flume的配置很繁琐,source,channel,sink的关系在配置文件里面交织在一起,不便于管理。















 4035
4035











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









