







1、说说java中常用的集合类。
java集合中比较常用的包括Collection和Map,Collection中比较常用的有Set,List和Queue,Set对应数学中的集合,不会出现重复的元素,元素是无序的,常用的Set包括HashSet跟TreeSet;List是一种线性结构,允许出现重复元素,元素是有顺序性的;Queue也是一种先进先出的数据结构。Map是一种key-value的数据结构,充分结合了数组可以根据下标访问以及链表的插入删除的便利性的优点,常用的Map包括HashMap,TreeMap,HashTable等。
2、说说List。
List中比较常用的有ArrayList、LinkedList、Vector,ArrayList底层是使用数组进行实现的,在使用下标进行访问时可以做到o(1)的时间复杂度,但是在进行插入删除时需要移动元素,同时当ArrayList底层数组空间不足时,需要扩充容量,(默认扩大为原来的1.5倍),这会进行元素的重新拷贝,所以不适合于频繁进行插入删除操作的情况。LinkedList底层是使用双向链表实现的,因此查找一个元素时需要从头到尾进行查找,效率较低,但在进行插入元素时只需要修改下指针,而不需要移动元素,所以适合于插入删除比较频繁的操作。Vector底层也是使用数组实现的,但它是线程安全的,效率也就较ArrayList要低(其在扩容时默认扩大为原来的2倍)。
3、说说HashSet跟TreeSet。
HashSet底层是使用HashMap进行存储的,根据key值的hashcode值计算出hash值,进而找到存储位置,访问的时间复杂度为o(1),而TreeSet底层是使用红黑树实现的,元素的存储是有序的。
4、说说HashMap、HashTable跟TreeMap。
HashMap底层是一种使用链表+数组进行存储的结构,充分结合了链表跟数组的优点,它进行插入、查找元素时是根据key值的hashcode值计算出他的hash值,利用hash值计算出它在数组中的位置,这样找到那个链后,然后顺着链从前往后再根据key的equals方法进行查找,如果没有相应元素则利用首插法在链表头部进行插入。当map中元素的数量达到了负载因子对应阈值的时候会进行扩容操作,将HashMap扩容为原来的2倍。扩容后,原来的元素需要重新计算所在位置,计算所在位置时根据hash&(length-1)进行计算。
HashMap跟HashTable相比,HashMap是非线程安全的,在没有线程安全的环境下使用HashMap效率更高;而且HashMap中key跟value都允许为null,而HashTable不允许;HashMap每次扩容都扩大为原来的2倍,HashTable扩容为原来的大小*2+1;HashMap去掉了contains()方法,只使用没有歧义的containsKey()和containsValue()。
HashMap与TreeMap相比,HashMap是使用数组➕链表结构进行存储,适合于根据key值进行随机访问;而TreeMap底层使用红黑树结构进行存储,根据key值进行了排序,如果希望按key值进行排序或自定义排序,适合使用TreeMap。
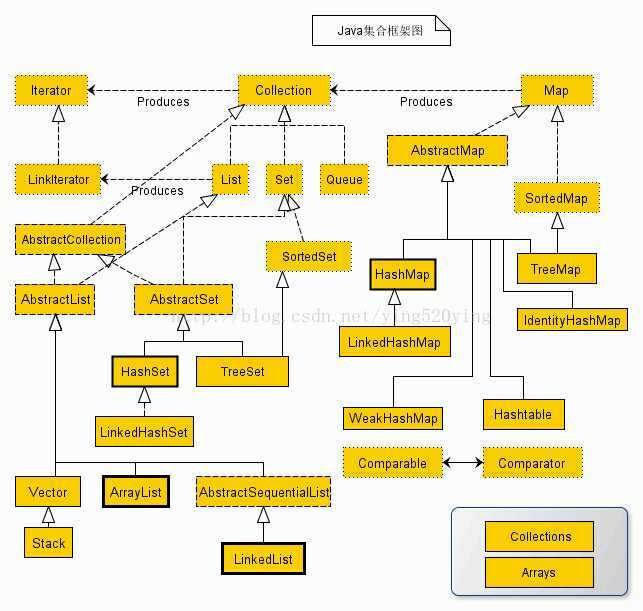
附一张漂亮的图:















 669
669











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









