







在简单入门线程池(一)中,对于线程池的定义,和Java对线程池的支持,以及线程池的构造方法和涉及的参数这些方面,对线程池进行了简单的介绍。
在简单入门线程池(二)中,对线程池的内部实现,执行流程以及任务队列,做了进一步的介绍。
接着,将对线程池进一步做一些拓展。
1. 扩展线程池
ThreadPoolExecutor是一个可拓展的线程池。
它提供了beforeExecute( )、afterExecute( )和terminated( )三个接口对线程池进行控制。
以beforeExecute( )、afterExecute( )为例,在ThreadPoolExecutor.Worker.runTask( )方法内部提供了这样的实现。
boolean ran = false;
// 运行前
beforeExecute(thread, task);
// 运行任务
try {
task.run();
ran = true;
// 运行结束后
afterExecute(task, null);
++completedTasks;
} catch (RuntimeException e) {
if (!ran) {
// 运行结束
afterExecute(task, e);
throw e;
}
}
ThreadPoolExecutor.Worker是ThreadPoolExecutor的内部类,是一个实现了Runnable接口的类。ThreadPoolExecutor线程池中的工作线程也正是Worker实例。Worker.runTask( )方法会被线程池以多线程模式异步调用,即Worker.runTask( )会同时被多个线程访问。
实例
/**
* @author LISHANSHAN
* @ClassName ExtThreadPool
* @Description TODO
* @date 2022/06/2022/6/1 21:33
*/
public class ExtThreadPool {
public static class MyTask implements Runnable{
public String name;
public MyTask(String name) {
this.name = name;
}
@Override
public void run() {
System.out.println("正在执行" + ": Thread ID: " + Thread.currentThread().getId()
+ ", Task Name = " + name);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws InterruptedException {
ExecutorService es = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()) {
@Override
protected void beforeExecute(Thread t, Runnable r) {
System.out.println("准备执行:" + ((MyTask)r).name);
}
@Override
protected void afterExecute(Runnable r, Throwable tr) {
System.out.println("执行完成:" + ((MyTask)r).name);
}
@Override
protected void terminated() {
System.out.println("线程池退出");
}
};
for (int i = 0; i < 5; i++) {
MyTask task = new MyTask("TASK-GEYM-" + i);
es.execute(task);
Thread.sleep(100);
}
es.shutdown();
}
}
执行结果
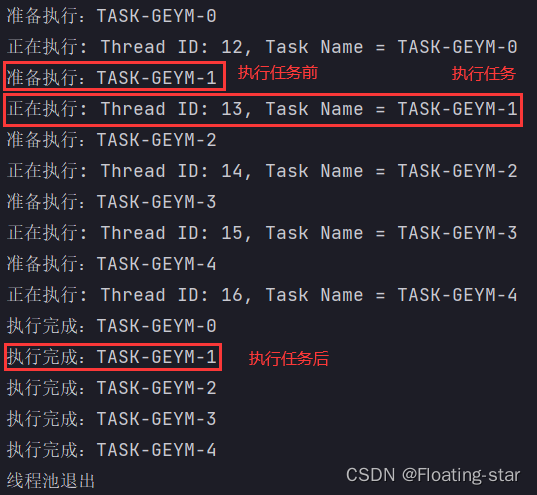
可以发现,所有任务的执行前、执行后的时间点以及任务的名字都可以被捕获,这对于应用程序的调试有利。
优化线程池的数量
线程池的大小对系统的性能有一定的影响。
过大或过小的线程数量都无法发挥最优的系统性能。
一般来说,确定线程池的大小需要考虑CPU数量、内存大小等因素。
在Java中,可以通过
Runtime.getRuntime().availableProcessors();
获得CPU的数量。
在《Java Concurrency in Pactice》中,给出了估算线程池大小的经验公式:
N
C
P
U
=
C
P
U
的数量
U
C
P
U
=
C
P
U
的使用率
(
0
≤
U
C
P
U
≤
1
)
W
/
C
=
等待时间与计算时间的比率
则可得最佳的线程池的大小
:
N
t
h
r
e
a
d
s
=
N
C
P
U
×
U
C
P
U
×
(
1
+
W
C
)
N_{CPU} = CPU的数量\\ U_{CPU} = CPU的使用率(0 \leq U_{CPU} \leq 1)\\ W/C = 等待时间与计算时间的比率\\ 则可得最佳的线程池的大小:\\ Nthreads = N_{CPU} \times U_{CPU} \times (1 + \frac{W}{C})
NCPU=CPU的数量UCPU=CPU的使用率(0≤UCPU≤1)W/C=等待时间与计算时间的比率则可得最佳的线程池的大小:Nthreads=NCPU×UCPU×(1+CW)
一个简单而且适用面比较广的公式:
- CPU密集型任务(N+1):这种任务消耗的主要是CPU资源,可以将线程数设置为N(CPU核心数) + 1, 比CPU核心数多出来的一个线程是为了防止线程偶发的缺页中断,或者其他原因导致的任务暂停而带来的影响。一旦任务暂停,CPU就会处于空闲状态,而在这种情况下就可以充分利用CPU的空闲时间
- I/O密集型任务(2N):这种任务应用起来,系统会用大量时间来处理I/O交互,而线程在处理I/O的时间段内不会占用CPU,这时就可以将CPU交出给其他线程使用。因此,可以多配置一些线程。
2. 寻找异常堆栈
多线程本身就很容易引发一些错误,更何况如今使用线程池呢。
也就是说,线程池很有可能会“吃掉”程序抛出的一场,导致我们对程序的错误一无所知。
那么,如何向线程池讨回异常堆栈呢?
用execute( )
即在提交任务时,放弃submit,而是改用execute( )方法。
pools.execute(new MyTask());
或者Future ft = pools.submit(new MyTask());
ft.get( );
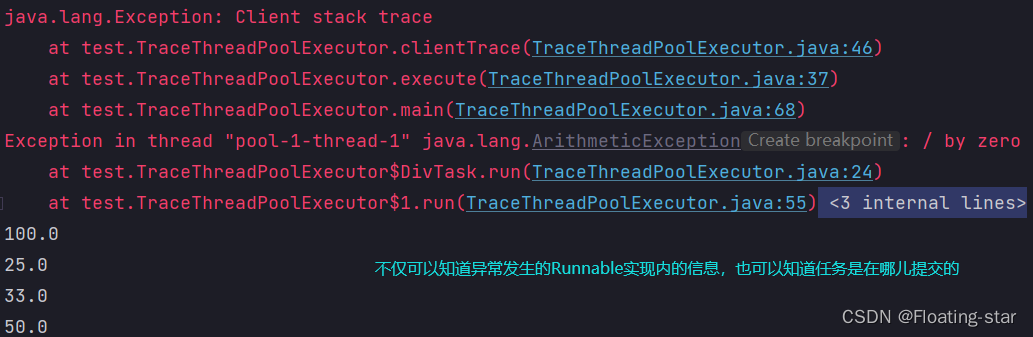
这两种方式,都可以得到部分堆栈的内容,即可以知道异常是在哪里抛出的,但是却无法知道任务是在何处提交的。因为任务的具体提交位置已经被线程池淹没了,只可以知道任务的调度流程。
案例代码
import com.sun.deploy.trace.Trace;
import java.util.concurrent.*;
/**
* @author LISHANSHAN
* @ClassName TraceThreadPoolExecutor
* @Description TODO
* @date 2022/06/2022/6/1 22:43
*/
public class TraceThreadPoolExecutor extends ThreadPoolExecutor {
public static class DivTask implements Runnable{
int a, b;
public DivTask(int a, int b) {
this.a = a;
this.b = b;
}
@Override
public void run() {
double re = a/b;
System.out.println(re);
}
}
public TraceThreadPoolExecutor(int corePoolSize, int maximumPoolSize,
long keepAliveTime, TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);
}
@Override
public void execute(Runnable command) {
super.execute(wrap(command, clientTrace(), Thread.currentThread().getName()));
}
@Override
public Future<?> submit(Runnable command) {
return super.submit(wrap(command, clientTrace(), Thread.currentThread().getName()));
}
private Exception clientTrace() {
return new Exception("Client stack trace");
}
//该wrap函数中的第2个参数为异常,里边保存着提交任务的线程的堆栈信息,该方法将我们传入的Runnable任务进行一层包装,使之能处理异常信息。
private Runnable wrap(final Runnable command, final Exception clientTrace,
String clientThreadName) {
return new Runnable() {
@Override
public void run() {
try {
command.run();
} catch (Exception e) {
clientTrace.printStackTrace();
throw e;
}
}
};
}
public static void main(String[] args) {
ThreadPoolExecutor pools = new TraceThreadPoolExecutor(0, Integer.MAX_VALUE,
0L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>());
for (int i = 0; i < 5; i++) {
pools.execute(new DivTask(100, i));
}
}
}
运行结果
3. 分而治之:Fork/Join框架
如果要处理1000个数据,那么可以在先只处理其中的10个,然后分阶段处理100次,再将100次的结果进行合成,就是最终想要的对原始1000个数据的处理结果。
简析
fork和Join
- 函数fork( )用来创建子进程,使得系统进程可以多一个执行分支。
- join( )也就是等待,使用fork( )后系统多了一个执行分支(线程),所以需要等待这个执行分支执行完毕,才有可能得到最终的结果。
- 在JDK中,给出了一个ForkJoinPool线程池。对于fork方法并不急着开启线程,而是提交给ForkJoinPool线程池进行处理,以节省系统资源。
“互帮互助”
由于线程池的优化,提交的任务和线程的数量并不是对等的关系。在绝大多数情况下,一个线程实际上是要处理多个逻辑任务的。因此,每个线程必然要有一个任务队列。因此在实际执行时,可能会出现,A的任务执行完了,但是B还有一堆任务要执行,那么A就会来帮助B,从B的任务队列中取出任务来处理。值得注意的是,当线程试图帮助别人时,总是从任务队列的底部开始拿数据,而线程试图执行自己的任务时,则是从相反顶部开始。这样可以避免线程之间发生数据冲突。
重要接口
ForkJoinPool的一个重要接口:
public <T> ForkJoinTask<T> submit(ForkJoinTask<T> task)
所谓ForkJoinTask任务就是支持fork分解和join等待的任务。
ForkJoinTask有两个重要的子类,RecursiveAction和RecursiveTask。它们分别表示没有返回值的任务和可以携带返回值的任务。
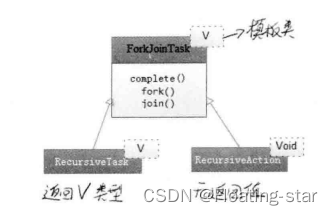
简例
public class CountTask extends RecursiveTask<Long> {
// 最大任务量
private static final int THRESHOLD = 10000;
private long start;
private long end;
public CountTask(long start, long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
long sum = 0;
boolean canCompute = (end - start) < THRESHOLD;
// 如果在计算能力内,则直接计算
if (canCompute) {
for (long i = start; i <= end; i++) {
sum = sum + i;
}
} else {
// 反之,分成100个小任务,每个任务的范围,即为步长
long step = (end - start) / 100;
ArrayList<CountTask> subTasks = new ArrayList<>();
long pos = start;
for (int i = 0; i < 100; i++) {
long lastOne = pos + step;
if (lastOne > end) {
lastOne = end;
}
// 计算当前任务
CountTask subTask = new CountTask(pos, lastOne);
// 更新任务的起始位置
pos = pos + step + 1;
// 将当前任务加入列表中
subTasks.add(subTask);
// 将当前任务进行分解。
subTask.fork();
}
// 等待列表中的所有任务执行完毕
for (CountTask t : subTasks) {
sum = sum + t.join();
}
}
// 将结果返回
return sum;
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
CountTask task = new CountTask(0, 2000L);
// 提交任务
ForkJoinTask<Long> result = forkJoinPool.submit(task);
try {
// 将结果转化为long类型
long res = result.get();
System.out.println("sum = " + res);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException ec) {
ec.printStackTrace();
}
}
}
注意
划分层次
在使用ForkJoin时要注意,如果任务的划分层次很深,一直得不到返回,那么可能出现两种情况:
第一、系统内的线程数量越积越多,严重影响性能
第二、函数的调用层次变得很深,最终导致栈溢出
无锁的栈
此外,ForkJoin线程池使用一个无锁的栈来管理空闲线程,如果下一个工作线程暂时取不到可用的任务,那么可能会被挂起,挂起的线程会压入由线程池维护的栈中。等到有任务可用时,再从栈中被唤醒














 4264
4264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









