







1、词嵌入基础
使用 one-hot 向量表示单词,虽然它们构造起来很容易,但通常并不是一个好选择。一个主要的原因是,one-hot 词向量无法准确表达不同词之间的相似度,如我们常常使用的余弦相似度。
Word2Vec 词嵌入工具的提出正是为了解决上面这个问题,它将每个词表示成一个定长的向量,并通过在语料库上的预训练使得这些向量能较好地表达不同词之间的相似和类比关系,以引入一定的语义信息。基于两种概率模型的假设,我们可以定义两种 Word2Vec 模型:
- Skip-Gram 跳字模型:假设背景词由中心词生成,即建模 P ( w o ∣ w c ) P(w_o\mid w_c) P(wo∣wc),其中 w c w_c wc 为中心词, w o w_o wo 为任一背景词;

- CBOW (continuous bag-of-words) 连续词袋模型:假设中心词由背景词生成,即建模 P ( w c ∣ W o ) P(w_c\mid \mathcal{W}_o) P(wc∣Wo),其中 W o \mathcal{W}_o Wo 为背景词的集合。

— 这个视频讲的很详细,特别是对公式 –
[MXNet/Gluon] 动手学深度学习第十六课:词向量(word2vec)
counter = collections.Counter([tk for st in raw_dataset for tk in st]) # tk是token的缩写,统计词频
counter = dict(filter(lambda x: x[1] >= 5, counter.items())) # 只保留在数据集中至少出现5次的词
idx_to_token = [tk for tk, _ in counter.items()]
token_to_idx = {tk: idx for idx, tk in enumerate(idx_to_token)}
dataset = [[token_to_idx[tk] for tk in st if tk in token_to_idx]
for st in raw_dataset] # raw_dataset中的单词在这一步被转换为对应的idx
num_tokens = sum([len(st) for st in dataset])
print('# tokens: %d' % num_tokens)
print('# dict : %d' % len(idx_to_token))
print(counter['the'])
2、二次采样
文本数据中一般会出现一些高频词,如英文中的“the”“a”和“in”。通常来说,在一个背景窗口中,一个词(如“chip”)和较低频词(如“microprocessor”)同时出现比和较高频词(如“the”)同时出现对训练词嵌入模型更有益。因此,训练词嵌入模型时可以对词进行二次采样。 具体来说,数据集中每个被索引词 w i w_i wi 将有一定概率被丢弃,该丢弃概率为
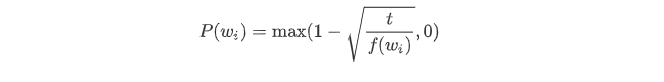
其中
f
(
w
i
)
f(w_i)
f(wi) 是数据集中词
w
i
w_i
wi 的个数与总词数之比,常数
t
t
t 是一个超参数(实验中设为
1
0
−
4
10^{−4}
10−4)。可见,只有当
f
(
w
i
)
>
t
f(w_i)>t
f(wi)>t 时,我们才有可能在二次采样中丢弃词
w
i
w_i
wi,并且越高频的词被丢弃的概率越大。(这里丢弃的是每个句子里的高频词,词典大小并没有改变)
3、负采样近似
由于 softmax 运算考虑了背景词可能是词典 V \mathcal{V} V 中的任一词,对于含几十万或上百万词的较大词典,就可能导致计算的开销过大。我们将以 skip-gram 模型为例,介绍负采样 (negative sampling) 的实现来尝试解决这个问题。
负采样方法用以下公式来近似条件概率 P ( w o ∣ w c ) = exp ( u o ⊤ v c ) ∑ i ∈ V exp ( u i ⊤ v c ) P(w_o\mid w_c)=\frac{\exp(\boldsymbol{u}_o^\top \boldsymbol{v}_c)}{\sum_{i\in\mathcal{V}}\exp(\boldsymbol{u}_i^\top \boldsymbol{v}_c)} P(wo∣wc)=∑i∈Vexp(ui⊤vc)exp(uo⊤vc):
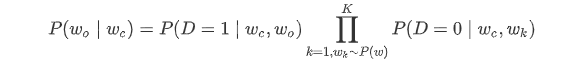
其中
P
(
D
=
1
∣
w
c
,
w
o
)
=
σ
(
u
o
⊤
v
c
)
P(D=1\mid w_c,w_o)=\sigma(\boldsymbol{u}_o^\top\boldsymbol{v}_c)
P(D=1∣wc,wo)=σ(uo⊤vc),
σ
(
⋅
)
\sigma(\cdot)
σ(⋅) 为 sigmoid 函数。对于一对中心词和背景词,我们从词典中随机采样
K
K
K 个噪声词(实验中设
K
=
5
K=5
K=5)。根据 Word2Vec 论文的建议,噪声词采样概率
P
(
w
)
P(w)
P(w) 设为
w
w
w 词频与总词频之比的
0.75
0.75
0.75 次方。
这里的k是选取噪声词的数量,用来减少模型参数,用k来近似
V
\mathcal{V}
V
…有待更新


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









