






一、使用想转就转短视频无水印解析下载助手
电脑端软件下载

软件主界面
1.1、下载方法:
点击软件左侧「短视频解析」菜单下的「头条」子菜单,可以通过今日头条视频的分享链接解析下载无水印的视频,支持单个视频下载和批量下载。可设置「分享链接」、「分享链接文件」、「输出路径」等参数。

头条菜单页面
在「头条」页面,
如果想解析下载一条短视频,则在「分享链接」文本输入框中,填写一条在今日头条视频的分享图标复制的链接,然后点击「添加到表格」按钮,将分享链接的信息添加到软件表格内。比如,下面的一条分享链接:
分享链接类似于: https://www.xxxxxx.com/video/xxxxxxxxxxxxxxxxxxxx/
添加到软件表格内后,如下图:
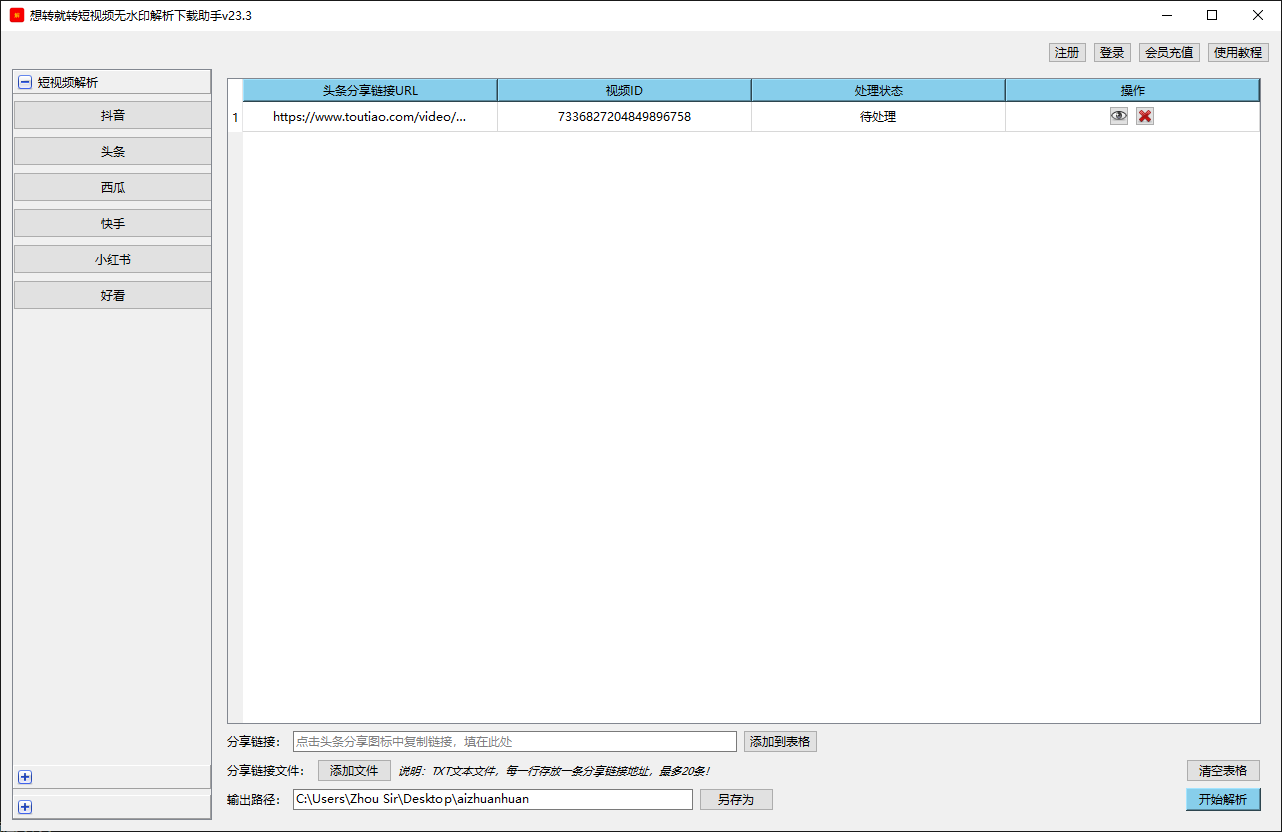
添加分享链接到表格
如果想解析下载多条短视频,请将不超过20条的分享链接,一条一行粘贴到一个文本文件中,然后在本软件的「分享链接文件」旁边,点击“添加文件”按钮,将刚才保存分享链接的文本文件添加进来,分享链接的信息会添加到软件表格内。比如,下面的文本文件有2条分享链接:

保存头条分享链接的文件
添加到软件表格内后,如下图:

添加多条分享链接到表格
「输出路径」处点击「另存为」按钮,选择解析后下载视频文件的保存路径,或者默认路径为桌面“aizhuanhuan”文件夹;
点击「开始解析」按钮,开始解析软件表格内的分享链接,当表格中对应分享链接的「处理状态」字段的值从“待处理”,变为“处理完成”,表示解析下载完毕,此时,可以在「输出路径」中找到已经下载好的文件。
点击「清空表格」按钮将清空表格内所有分享链接信息。
二、核心代码
def start_analyse(self):
# 如果表格中有文件或文件夹,且是待处理状态,则对待处理文件或文件夹进行处理
if self.tableWidget_2.rowCount() > 0:
# 遍历表格中所有行
for row_index in range(self.tableWidget_2.rowCount()):
# 判断row_index行是否为待处理文件:
# 如果是待处理,则从表格拥有分享链接信息字典self.url_dict_in_table 中获取该行文件的全路径
if self.tableWidget_2.item(row_index, 2).text() == "待处理":
# row_index行‘处理状态’字段值设置由“待处理”修改为“处理中...”
self.set_handle_status_item(row_index, "处理中...")
# 获取该行“分享链接URL”
https_url = self.tableWidget_2.item(row_index, 0).text()
# 输出文件夹路
out_folder = self.out_dir_lineEdit.text()
# 输出文件夹路径不存在则创建
if not os.path.isdir(out_folder):
os.makedirs(out_folder)
# 短视频解析:
# 标题头headers
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
# 一般User-Agent字段包括以下几个信息:浏览器标识 (操作系统标识; 加密等级标识; 浏览器语言) 渲染引擎标识 版本信息;
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36",
# cookie 必须要,但是不用登录的cookie..先进入头条的页面,按f12查看cookie就可以了,全部复制也可以,只复制ttwid也可以
"Cookie": "ttwid=1%7CarG_9zGHRnvha3xXVrDKUesY-60w8j0Wn7FI6t6ZvFM%7C1687310450%7Cd2ec6a6525f124a59045e2e1314be8c6cdddaae26f8ae8cf06696d235fe1721b; "
}
# 从分享链接'https://www.toutiao.com/video/7313169821129474587/'获取视频资源地址
res = requests.get(https_url, headers=headers, timeout=10)
html_content = res.text
# print(html_content)
# 将 HTML 内容解析为 BeautifulSoup 对象
soup = BeautifulSoup(html_content, 'html.parser')
# print(soup)
# 查找包含 "id="RENDER_DATA"" 的 script 标签
tag = soup.find('script', id='RENDER_DATA')
# 提取 JSON 字符串
json_data = tag.string
# print('json_data数据:',json_data)
json_data2 = urllib.parse.unquote(json_data)
# print('json_data2数据:',json_data2)
# 将 JSON 字符串解析为 Python 对象
data = json.loads(json_data2)
# pprint.pprint(data) # 格式化输出
# 视频的格式不一样,json格式也不一样.例如有video_list和dynamic_video
title = data['data']['initialVideo']['title'] # 标题
videoPlayInfo = data['data']['initialVideo']['videoPlayInfo'] # 该下面的属性不一样,需要判断
last_video_list = None
if videoPlayInfo.get("video_list"):
last_video_list = videoPlayInfo['video_list'][-1] # 取最后一个,是最清晰的视频链接
elif videoPlayInfo.get('dynamic_video'):
last_video_list = videoPlayInfo['dynamic_video']['dynamic_video_list'][-1] # 取最后一个,是最清晰的视频链接
backup_url = last_video_list['backup_url'] # 最终的视频链接
print('视频资源地址:', backup_url)
# 将video_id对于视频资源下载到输出文件夹out_folder
result_state = self.save_video_from_video_url(headers, title, backup_url, out_folder)
# 如果result_state为真,则表明“处理完成”
if result_state:
# 表格中“处理状态”字段单元格值设置由“处理中...”修改为“处理完成!”
self.set_handle_status_item(row_index, "处理完成!")
else:
# 表格中“处理状态”字段单元格值设置由“处理中...”修改为“出错啦!”
self.set_handle_status_item(row_index, "出错啦!")
# 如果表格中没有分享链接信息,则弹出警告
else:
# 弹出警告消息框提示
QMessageBox.warning(self, "警告", "请添加分享链接!")















 327
327











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









