







2023.11.15
175.组合两个表
https://leetcode.cn/problems/combine-two-tables/description/
- 代码:
select p.firstName,p.lastName,a.city,a.state
from Person p
left join Address a on a.personId=p.personId
181. 超过经理收入的员工
https://leetcode.cn/problems/employees-earning-more-than-their-managers/
- 分析:Employee表中的managerId代表当前这个id的员工的经理的Id;数据来自两个表,内连接。
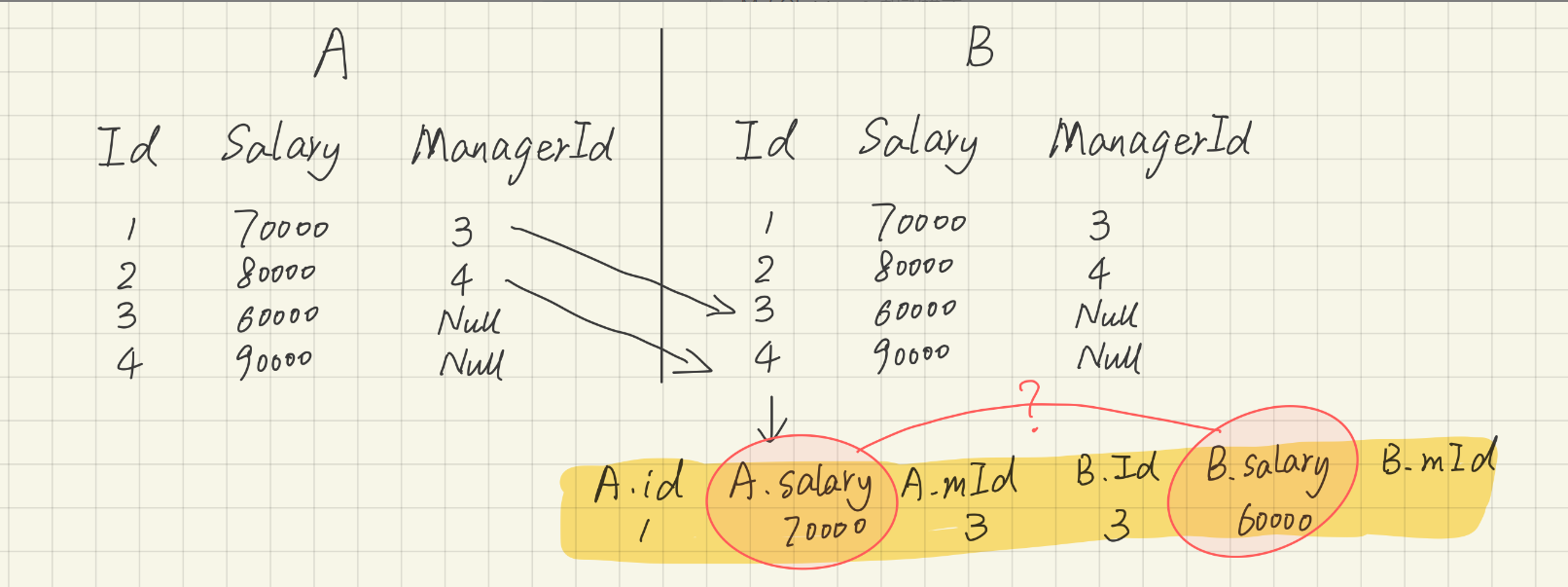
select e1.name as 'Employee'
from Employee e1,Employee e2
where e1.managerId=e2.id
and e1.salary>e2.salary
182. 查找重复的电子邮箱
https://leetcode.cn/problems/duplicate-emails/
- 分析:根据电子邮件进行分组,并having判断电子邮件的数量是否大于1
select Email
FROM Person
group by Email having count(Email)>1;
183.从不订购的客户
https://leetcode.cn/problems/customers-who-never-order/
- 分析:Orders中的customerId如果存在,就表示这个客户订购过了,那么就判断customerId在不在这个表中。
select name as Customers
from Customers c
where c.id not in
(
select customerId from Orders
)
197.上升的温度
https://leetcode.cn/problems/rising-temperature/description/
- 分析:subdate()函数,日期-1;两个表自连接。
select b.id as 'id'
from Weather a,Weather b
where a.recorddate=subdate(b.recorddate,1) and b.temperature>a.temperature
2023.11.28
577.员工奖金
https://leetcode.cn/problems/employee-bonus/description/
- 分析:Employee作为主表,Bonus左关联Bonus表
- 代码:
select
e1.name,b1.bonus
from
Employee e1
left join
Bonus b1
on e1.empId=b1.empId
where b1.bonus<=500 or b1.bonus is null
584.寻找用户推荐人
https://leetcode.cn/problems/find-customer-referee/description/
- 分析:对符合条件的id进行筛选,判断id!=2
- 代码:
select name from Customer where referee_id<>2 or referee_id is null
2023.11.29
586. 订单最多的国家(*)
https://leetcode.cn/problems/customer-placing-the-largest-number-of-orders/description/
- 分析:最大值-用逆序排序取第一个的方式来计算
- 如果最大值只有一个:
SELECT customer_number FROM orders GROUP BY customer_number ORDER BY COUNT(*) DESC LIMIT 1 ;- 如果最大值有多个:
select customer_number from Orders group by customer_number having count(customer_number)= ( SELECT COUNT(customer_number) AS 'cnt' FROM Orders GROUP BY customer_number ORDER BY cnt DESC LIMIT 1 )
595. 大的国家
https://leetcode.cn/problems/big-countries/description/
- 代码
select name,population,area
from World
where area>=3000000 or population>=25000000
2023.11.30
596.超过5名学生的课
https://leetcode.cn/problems/classes-more-than-5-students/
- 分析:统计某一列个数要比*要快
select class
from Courses
group by class
having count(Student)>=5 #计数某一列要比计数*时间快
607.销售员
https://leetcode.cn/problems/sales-person/description/
- 分析:从一个表进行筛选,用where not in 进行限定,限定后是一个表关联。
select sp.name
from SalesPerson as sp
where sp.sales_id NOT IN
(
select o.sales_id
from Orders o
left join
Company c
ON
o.com_id=c.com_id
where
c.name='RED'
)
2023.12.4
610.判断三角形
https://leetcode.cn/problems/triangle-judgement/description/
- 分析:两边之和大于第三边,and的关系
select x,y,z,
case
when x+y>z and x+z>y and y+z>x then 'Yes'
else 'No'
end as 'triangle'
from
triangle
;
619.只出现一次的最大数字
https://leetcode.cn/problems/biggest-single-number/description/
- 分析:先对数字进行去重,筛选出独立的数字,再从中选出最大的数字。
select Max(num) as num from MyNumbers
where num not in
(
select num from MyNumbers group by num having count(num) > 1
)
2023/12/5
620. 有趣的电影
https://leetcode.cn/problems/not-boring-movies/
- tips:对表起别名,可以加快查询速度
select
*
from cinema
where description !='boring' and id%2=1
order by rating desc
627. 变更性别
https://leetcode.cn/problems/swap-salary/description/
- 分析:update整个表,采用case…when…then对表中的数据进行重新赋值。
update salary
set
sex=
case sex
when 'm' then 'f'
else 'm'
END;
2023.12.7
1050. 合作过至少3次的演员和导演(*)
https://leetcode.cn/problems/actors-and-directors-who-cooperated-at-least-three-times/description/
- 分析:groupby 可以同时对一行数据进行分组(包括多列),并用having来限制groupby中的条件。
select actor_id,director_id
from ActorDirector
group by actor_id,director_id
having count(timestamp)>=3
1068. 产品销售分析1
https://leetcode.cn/problems/product-sales-analysis-i/description/
- 分析:一般字段值以谁为依据,谁是主表。
select p.product_name as product_name,s.year as year,s.price as price
from Sales s
left join
Product p
on
s.product_id=p.product_id
1075. 项目员工1(*)
https://leetcode.cn/problems/project-employees-i/description/
- 分析:求和总数再除以个数的问题可以使用AVG函数
select p.project_id,round(AVG(e.experience_years),2) as average_years
from Project p
left join
Employee e
on
p.employee_id=e.employee_id
group by p.project_id
2023.12.8
1084. 销售分析三
https://leetcode.cn/problems/sales-analysis-iii/description/
- 分析:仅在2019-01-01至2019-03-31(含)之间出售的商品–表示group by中的日期都得满足这个条件(使用between…and来处理日期的范围)
- 限定条件:在这个日期范围的日期个数与总的日期个数相同
select s.product_id,p.product_name
from Product p
left join Sales s
on p.product_id=s.product_id
group by s.product_id
having count(s.sale_date between '2019-01-01' and '2019-03-31' or null)=count(*)
1141. 查询近30天活跃用户数
https://leetcode.cn/problems/user-activity-for-the-past-30-days-i/solutions/2329645/xin-shou-jie-ti-fen-xi-ti-mu-yi-bu-yi-bu-0iaj/
-
分析:
- 要注意计数的时候,要进行去重。
count(distinct ##)- 计算近30天
- 用DATE_ADD函数减:DATE_ADD(‘2019-07-27’,INTERVAL -29 day)
- 用datediff(date1, date2),返回date1-date2的差,判断差值是否在范围里:DATEDIFF(CAST(“2019-07-27” AS DATE), activity_date) BETWEEN 0 AND 29
-
代码:
- 第一种解法:
select activity_date as day,count(distinct user_id) as active_users
from Activity
where activity_date BETWEEN DATE_ADD('2019-07-27',INTERVAL -29 day) and '2019-07-27'
group by activity_date
- 第二种解法(更快):
SELECT activity_date AS day, COUNT(DISTINCT user_id) AS active_users
FROM Activity
WHERE DATEDIFF(CAST("2019-07-27" AS DATE), activity_date) BETWEEN 0 AND 29
GROUP BY activity_date
1148. 文章浏览 I
https://leetcode.cn/problems/article-views-i/description/
- 分析:
- 直接判断两列是否相等。
- 再进行逆序排序。
select
distinct author_id as id
from
Views
where author_id=viewer_id
order by author_id
1179. 重新格式化部门表 (行转列) (**)
https://leetcode.cn/problems/reformat-department-table/description/
- 分析:
- GROUP BY id 会使department表按照id分组,生成一张虚拟表。

- 当一个单元格中有多个数据时,case when只会提取当中的第一个数据。即只会取id为1时,月份为Jan,revenue为8000的值,id为1的其他月份的值就置为NULL,这样月份为Feb的时候revenue就不再为7000。
- 为了处理一行中的其余NULL值,需要一个能够处理多个数据输入,一个结果输出的函数,所以使用了聚合函数sum()/max()。
- GROUP BY id 会使department表按照id分组,生成一张虚拟表。
存在的问题:
- 以CASE WHEN month=‘Feb’ THEN revenue END 为例,当id=1时,它只会提取month对应单元格里的第一个数据,即Jan,它不等于Feb,所以找不到Feb对应的revenue,所以返回NULL。
- 那该如何解决单元格内含多个数据的情况呢?答案就是使用聚合函数,聚合函数就用来输入多个数据,输出一个数据的。如SUM()或MAX(),而每个聚合函数的输入就是每一个多数据的单元格。
- 以SUM(CASE WHEN month=‘Feb’ THEN revenue END) 为例,当id=1时,它提取的Jan、Feb、Mar,从中找到了符合条件的Feb,并最终返回对应的revenue的值,即7000。
select
id as id,
SUM(CASE WHEN month='Jan' THEN revenue END) AS Jan_Revenue,
SUM(CASE WHEN month='Feb' THEN revenue END) AS Feb_Revenue,
SUM(CASE WHEN month='Mar' THEN revenue END) AS Mar_Revenue,
SUM(CASE WHEN month='Apr' THEN revenue END) AS Apr_Revenue,
SUM(CASE WHEN month='May' THEN revenue END) AS May_Revenue,
SUM(CASE WHEN month='Jun' THEN revenue END) AS Jun_Revenue,
SUM(CASE WHEN month='Jul' THEN revenue END) AS Jul_Revenue,
SUM(CASE WHEN month='Aug' THEN revenue END) AS Aug_Revenue,
SUM(CASE WHEN month='Sep' THEN revenue END) AS Sep_Revenue,
SUM(CASE WHEN month='Oct' THEN revenue END) AS Oct_Revenue,
SUM(CASE WHEN month='Nov' THEN revenue END) AS Nov_Revenue,
SUM(CASE WHEN month='Dec' THEN revenue END) AS Dec_Revenue
from
Department
GROUP BY id
ORDER BY id
2024年1月2日
1211. 查询结果的质量和占比
https://leetcode.cn/problems/queries-quality-and-percentage/
- 分析:
- 要是结果要百分比,分子就需要乘以100
- 筛选group by 的字段的内容不为空,需要用having语句。
select
query_name,
round(avg(rating/position),2) as quality,
round(sum(if(rating<3,1,0))*100/count(*),2) as poor_query_percentage
from
Queries
group by query_name having query_name is not null
1251. 平均售价
https://leetcode.cn/problems/average-selling-price/description/
- 分析:
- 利用左关联,只是关联条件那里,不仅要ID匹配,同时还要限定售卖日期在开始日期和结束日期之间-用between … and … 来解决。
- 判断是否为空值:IFNULL(表达式,值1),判断表达式是否为空,如果为空,则显示值1。
2024.1.3
1280. 学生们参加各科测试的次数
- 分析:
- 第一步是学生表和课程表进行笛卡尔积,也就是每一行和另外一个表的每一行做匹配。
匹配后的结果为:
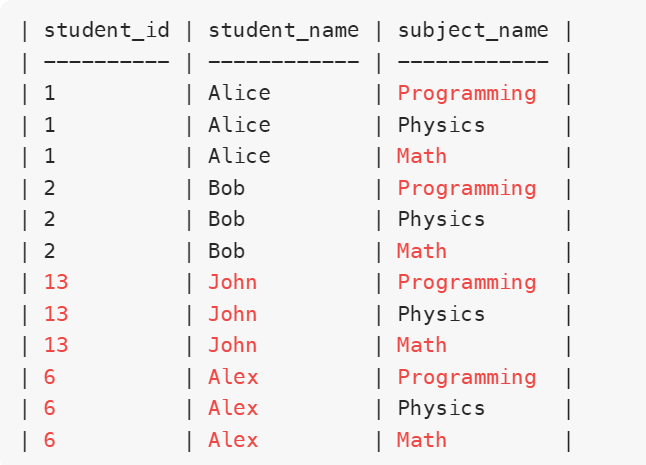
- 第二步与测试表Examinations进行左连接,条件是测试表与科目表的subject_name相同,测试表与学生表的student_id相同。
- 第三步要利用student_id和su.subject_name的进行分组和排序
- 第一步是学生表和课程表进行笛卡尔积,也就是每一行和另外一个表的每一行做匹配。
SELECT
s.student_id,
s.student_name,
su.subject_name,
COUNT(e.subject_name) AS attended_exams
FROM
Students AS s
JOIN
Subjects AS su
LEFT JOIN
Examinations AS e
ON
e.student_id = s.student_id
AND
e.subject_name = su.subject_name
GROUP BY
s.student_id,
su.subject_name
ORDER BY
s.student_id,
su.subject_name
1327.列出指定时间段内所有的下单产品
- 分析:
- 商品表Products和销售表Orders表进行左连接
- 限定销售日期可以用字符串的like语句
- 对不同商品进行分组,在组内用having选出sum(unit)>=100
having 对应的就是select里面筛选出来的字段
select
p.product_name, sum(unit) unit
from
Products p
left join
Orders o
on
p.product_id=o.product_id
where o.order_date like '2020-02%'
group by p.product_name
having sum(unit)>=100
2024.3.25
1378. 使用唯一标识码替换员工ID
https://leetcode.cn/problems/replace-employee-id-with-the-unique-identifier/description/
- 分析
- 两个表进行左关联
select b.unique_id,a.name
from Employees a
left join EmployeeUNI b
on a.id=b.id
1407. 排名靠前的旅行者
https://leetcode.cn/problems/top-travellers/description/
- 分析
- 对Rides表进行分组求和,对每个人的骑行距离进行相加,获得人id-距离一一对应的表
- 再与User表进行关联
- 对结果进行排序,一个降序,一个升序。
select a.name,if (b.travelled_distance is null,0,b.travelled_distance) as travelled_distance
from Users a
left join
(
select distinct r.user_id,sum(r.distance) as travelled_distance
from Rides r
group by r.user_id
) b
on a.id=b.user_id
order by b.travelled_distance desc,a.name asc
2024.03.27
1484.按日期分组销售产品(将分组后的内容进行拼接)*
- 拼接函数group_concat(拼接的列名 separator ‘分隔符’)
- 计数的时候要对产品去重
- 分组字段也要排序
select
sell_date,
count(distinct product) as num_sold,
group_concat(
distinct product
order by product
separator ','
) products
from
Activities
group by sell_date
order by sell_date
1517.查找拥有有效邮箱的用户(运用正则表达式)*
- 正则的规则
- ^ 表示以后面的字符为开头
- [] 表示括号内任意字符
-
- 表示连续
-
- 表示重复前面任意字符任意次数
- \ 用来转义后面的特殊字符,以表示字符原本的样子,而不是将其作为特殊字符使用
- $ 表示以前面的字符为结尾
- 题解:
- 前缀名以字母开头:^[a-zA-Z]
- 前缀名包含字母(大写或小写)、数字、下划线_、句点. 和 或 横杠-:[a-zA-Z0-9_.-]*
- 以域名’@leetcode.com’结尾:@leetcode\.com$
符号记得要将符号进行转义
select
*
from
Users
where mail REGEXP '^[a-zA-Z][a-zA-Z0-9\_\.\-]*@leetcode\\.com$'
2024.4.15
1527. 患某种疾病的患者
https://leetcode.cn/problems/patients-with-a-condition/
- 字符相似规则
- 可以使用or进行多种字符的like
select patient_id,patient_name,conditions
from Patients
where conditions like 'DIAB1%' or conditions like '% DIAB1%'
1581. 进店却未进行过交易的顾客
https://leetcode.cn/problems/customer-who-visited-but-did-not-make-any-transactions/
- 关联前就可以采用聚合函数,然后直接关联,再用条件属性进行筛选。
select customer_id,count(customer_id) as count_no_trans
from Visits v
left join Transactions t
on v.visit_id=t.visit_id
where transaction_id IS NULL
group by v.customer_id
1597. 银行账户概要
https://leetcode.cn/problems/bank-account-summary-ii/
- group by 之后,使用having对组内成分进行限定
select u.name,sum(t.amount) as balance
from Users u
left join Transactions t
on u.account=t.account
group by u.name
having sum(t.amount)>10000
2024.5.30
1633. 各赛事的用户注册率
https://leetcode.cn/problems/percentage-of-users-attended-a-contest/description/
- 除数和被除数可以用sql的查询
- 有百分制的情况下,可以用分子乘以100
select
contest_id,
round((count(distinct user_id)*100/(select count(user_id) from Users)),2) as percentage
from Register
group by contest_id
order by percentage desc,contest_id
2024.6.3
1661. 每台机器的进程平均运行时间
https://leetcode.cn/problems/average-time-of-process-per-machine/description/
- 解题思路1:
同一个machine_id可以放到一块计算,所有end都为正数,所有start都为负数,之后分组求和即可,除数是对进程的id做去重。
select machine_id,
round(sum(if(activity_type='end',timestamp,-timestamp))/count(distinct process_id),3) as processing_time
from Activity
group by machine_id
- 解题思路2:
通过表关联的方式,将表的start的time和end的time放到一行,但要在where中对a1和a2表的activity_type进行控制。
select
a1.machine_id,
round(avg(a2.timestamp -a1.timestamp ),3) as processing_time
from Activity as a1 join Activity as a2 on
a1.machine_id=a2.machine_id and
a1.process_id=a2.process_id and
a1.activity_type ='start' and
a2.activity_type ='end'
group by machine_id;
1667. 修复表中的名字
https://leetcode.cn/problems/fix-names-in-a-table/description/
- 解题思路:
-
SUBSTRING(column_name, start, length):这将从列的值中提取一个子字符串,从指定的起始位置开始,直到指定的长度。
-
left(name,1) 获得字符串左边的几个字符
-
UPPER(expression):这会将字符串表达式转换为大写。
-
LOWER(expression):这会将字符串表达式转换为小写。
-
CONCAT(string1, string2, …):这会将两个或多个字符串连接成一个字符串
-
select user_id,concat(upper(substring(name,1,1)),lower(substring(name,2))) as name
from Users
order by user_id
















 1031
1031











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











