









目录
亚马逊作为全球最大的跨境电商平台,其数据的价值不言而喻。常规的使用场景有1)关键字搜索+广告抢位;2)ASIN详情;3)评论分析。
作为完善的电商平台,其反爬的策略复杂多变,尤其是假数据部分的识别。本文重点介绍cookie生成协议的分析,侧重分析的过程。若想直接套用,可直接参考该文章:关键字搜索 - Citron Advisors
1. 需求 & 背景 & 挑战
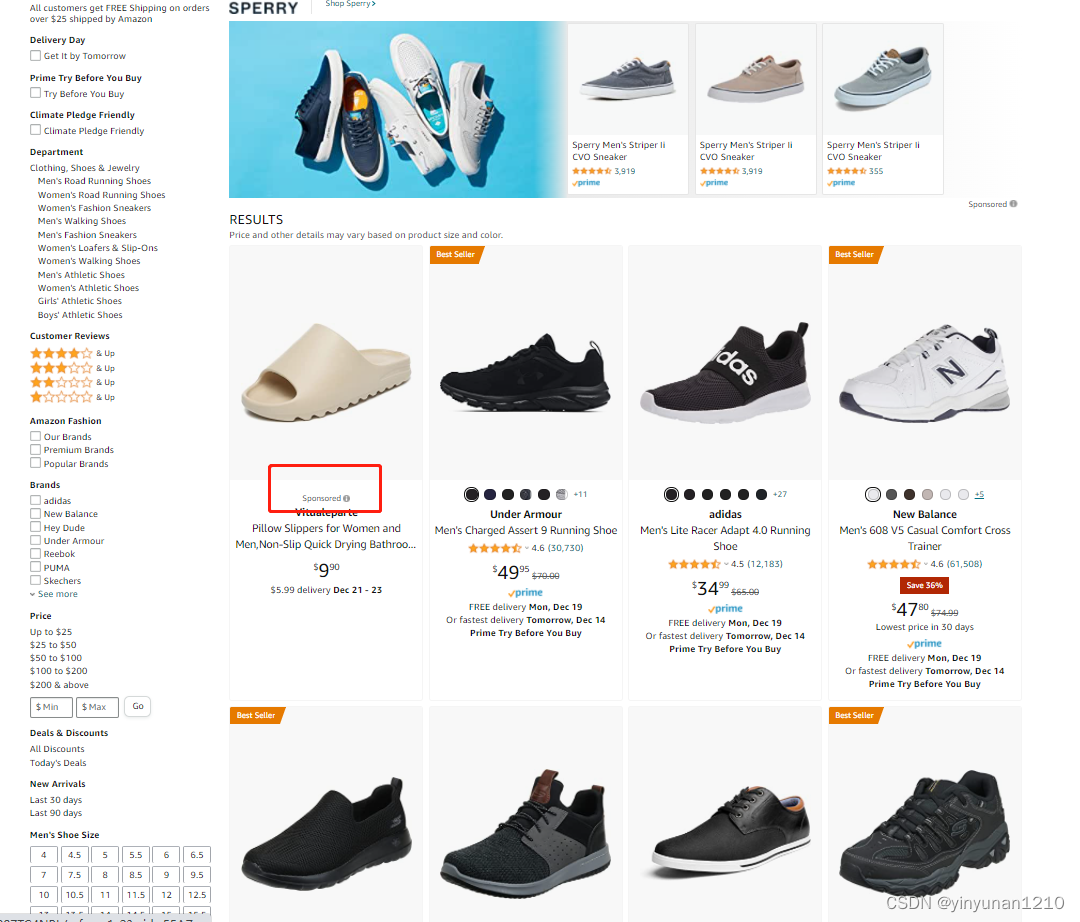
需求比较简单,比如打开www.amazon.com后,搜索man shoes,看看前3页的商品列表中,是否有自己的商品(投放广告 or 自然排名)。一般来说,越靠前的商品销量越好,所以商家都会特别关注这个排位情况,关键术语叫“抢位”。商家会根据排名情况,决定是否投放广告,以及投放广告的金额,具体可见下图:
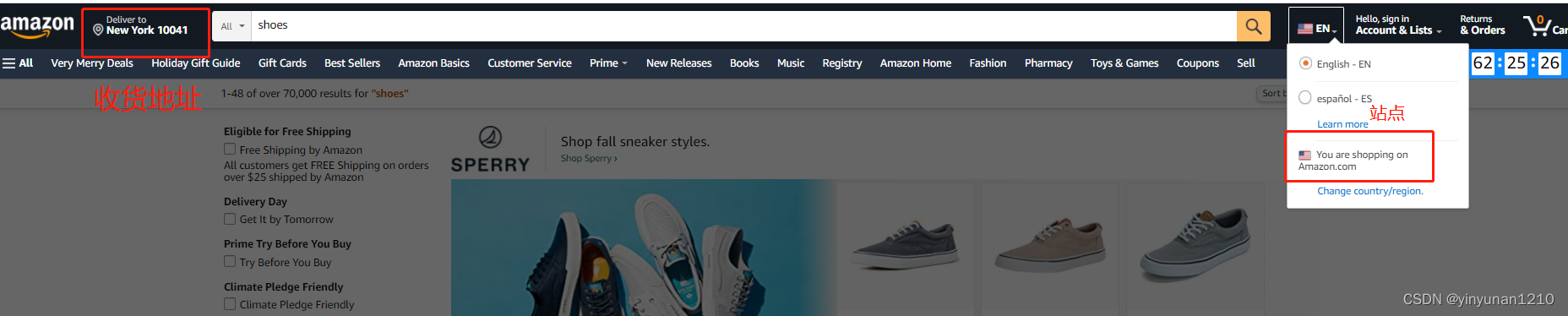
背景方面,亚马逊是全球性质的电商平台,总共有很多站点,比如美国站、德国站、日本站等,所以一般要看多个站点的关键字排名情况。排名情况的主要因素有2个:站点和收货地址,见下图:
挑战方面,主要有以下4个:
- 地址问题:需解决token、session-token、csrf-token、ubid-acbde、更改地址接口
- 验证码问题:当IP质量不行,或请求过于频繁时,会出现验证码
- IP供应商:亚马逊会定期记录可疑IP,所以需找好的供应商。
2. 抓包分析
使用Chrome的无痕模式访问www.amazon.com,并使用Charles进行抓包分析后,发现【地址切换】主要分为以下5个步骤:
为了避免法律纠纷和隐私泄露(鹅:407860264),关键信息(接口/字符/逻辑)均已打码,望大家理解。
2.1 从首页获取session等信息

2.2 获取ubid_acbde信息

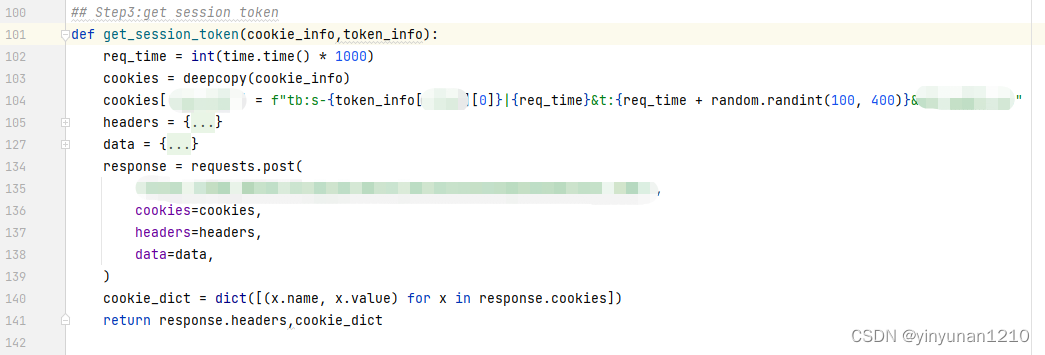
2.3 获取session-token信息
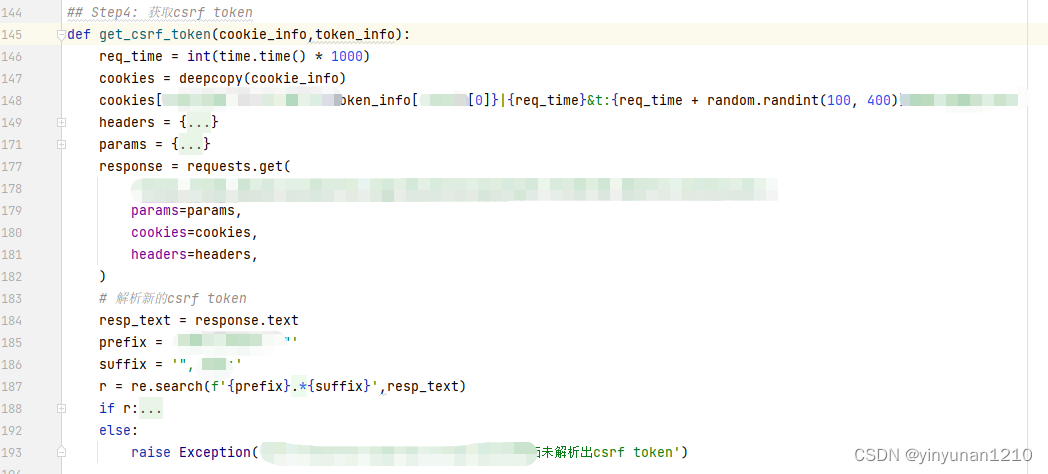
2.4 获取csrf-token信息
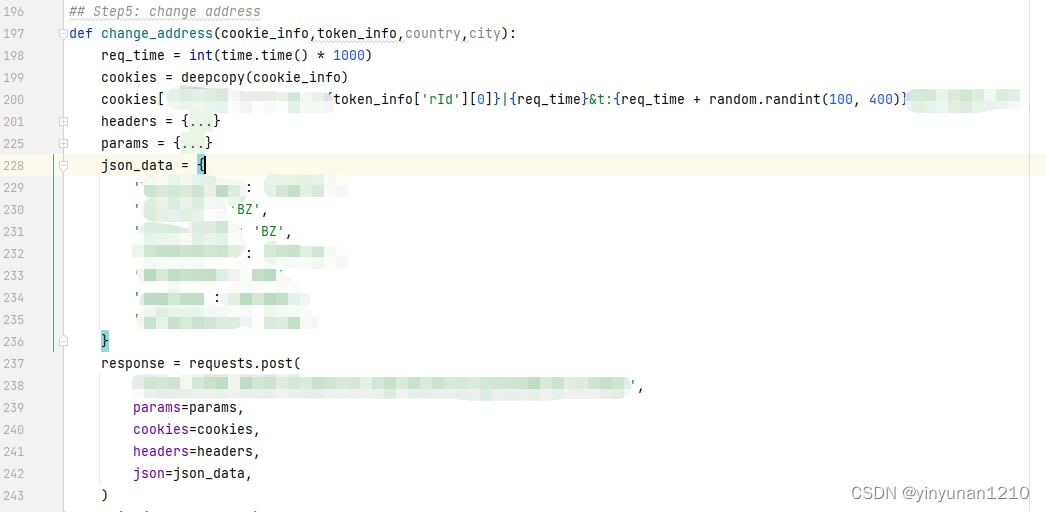
2.5 调用更改地址的接口
3. 验证码处理
亚马逊的验证码主要分为3类,其中gif类型处理比较麻烦,其他2种很简单。大家也不必从头开始造轮子,github上已有人开源,可以直接拿来二次优化后使用。
实在处理不了,换个IP就行,没必要纠结太多。

















 1594
1594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









