










目录
引言
本文介绍在VMware虚拟机下,如何搭建配置HADOOP平台,本文的目的是成功搭建HADOOP测试环境,对于技术细节原理不做介绍,过程中会把遇到的错误进行说明,避免踩坑,上篇介绍如何安装CentOS虚拟机,本篇文章为下篇,介绍如何使用CentOS虚拟机搭建HADOOP环境。
1.搭建前准备
1.1所需软件
- VMware® Workstation 15 Pro (其他版本亦可)
- CentOS-6.5-x86_64-minimal.iso(无界面操作系统镜像)
- hadoop-2.7.3
- jdk-7u79-linux-x64.rpm(java环境)
- Xshell (无版本要求,上传文件到虚拟机中时使用)
1.2HADOOP配置参数定义
本文将搭建一主三从的HADOOP环境,即一个主节点,三个从节点,为了规范配置,我们有如下定义:
- 主节点(namenode)主机名设置为node01,从节点(datanode)分别为node2、node03、node04
- node01~node03的IP地址分为设置为192.168.120.201~192.168.120.204
1.3 主要工作
本文搭建的HADOOP环境为一主三从,为了节省工作量,我们可以先在CentOS虚拟机node01上配置好各种所需参数,在通过VMware中的虚拟机克隆功能,克隆出node02、node03、node04三台虚拟机,只需重新配置好这三台虚拟的IP地址即可,其他的配置已经通过克隆node01获得。
2.配置node01的系统环境
必要技能:
- 了解简单的vi命令使用:打开并修改文件
2.1设置node01的IP信息
首先在控制台输入如下命令,查看node01中的网卡信息
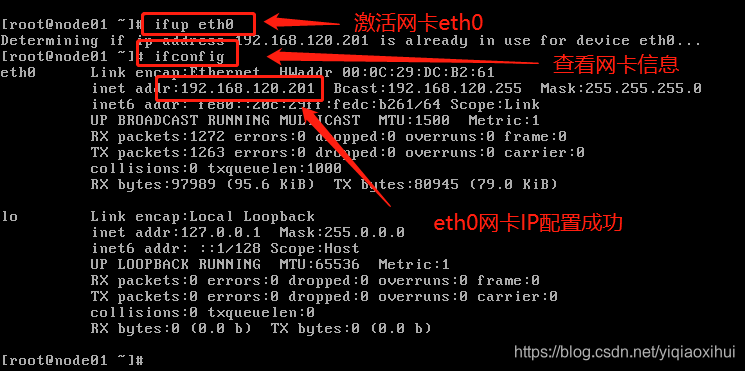
ifconfig -a #查看机器网卡信息显示结果如下图所示

从上图可以看出node01的网卡名称为 eth0
修改node01的网络配置,使用vi命令,打开并编辑文件ifcfg-eth0,vi命令不会使用的,自行百度,否则无法编辑文件
vi /etc/sysconfig/network-scripts/ifcfg-eth0ifcfg-eth0文件中需要修改的的部分参数如下,(提示,vi打开文件后,按i键进入编辑模式)
DEVICE=eth0 #DEVICE的值为网卡名称
BOOTPROTO=static
NETMASK=255.255.255.0 #子网掩码
ONBOOT=yes #开启自动配置
#HADRWARE=34:0f:23:23:df:11 #这行前面加一个 #,表示取消mac地址设置
#NM_CONTROLLED=yes
IPADDR=192.168.120.201 #设置IP地址,很重要
GATEWAY=192.168.120.2 #设置网关
修改完毕后,保存文件。(提示,vi编辑模式下,按esc键进入命令模式,然后按 shift+; 键,然后输入wq,按回车保存文件)
在控制台中输入如下命令,激活网卡
ifup eth0 #激活eth0 网卡,注意,网卡名称eth0是通过"ifconfig -a"命令查看的输出ifconfig命令查看网卡eth0是否激活成功,命令及结果如下图所示。
2.2配置DNS
配置DNS的目的主要是能进行域名访问,连接访问互联网。在 /etc/resolv.conf文件中添加DNS服务器,首先通过vi命令打开 /etc/resolv.conf文件
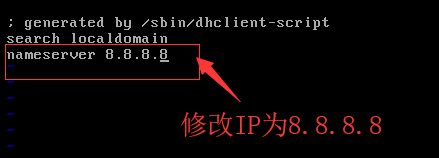
vi /etc/resolv.conf #打开域名解析文件,设置DNS服务器修改nameserver 为8.8.8.8 (Google提供的免费DNS服务器IP地址),修改后 /etc/resolv.conf文件内容如下图所示。
2.3 配置域名反向解析
这里主要是配置域名node01~node2到192.168.120.201~192.168.120.204的映射,这样我们访问node01~node04,就能直接解析成对应的IP地址了。这样做有两个目的:
- 配置hdfs-site.xml文件时,直接指定域名node01访问,而无需指定IP地址访问
- 配置slaves文件时,直接写入从机的域名node02~node04,无需指定IP地址进行互联通信,降低了配置的复杂性,更易读易记
配置域名反向解析的文件为/etc/hosts,我们使用vi命令打开并添加node01~node04的域名对应关系
vi /etc/hosts #打开hosts文件,添加node01~node04域名对应关系在hosts文件添加域名反向解析后,内容如下(node05添加备用):
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.120.201 node01
192.168.120.202 node02
192.168.120.203 node03
192.168.120.204 node04
192.168.120.205 node05
2.3禁用操作系统安全配置
首先,禁用iptable,依次输入如下两条命令禁用iptable
service iptables stop #停止功能
chkconfig iptables off #停止服务
然后,禁用selinux,方法是修改 /etc/selinux/config 文件,将SELINUX设置为disabled,同样通过vi命令打开文件
vi /etc/selinux/config #打开selinux的配置文件修改config文件后,其内容如下图所示

3.安装所需软件并配置
由于我们java安装包(jdk-7u79-linux-x64.rpm)以及haoop(hadoop-2.7.3)都在本地文件夹中,若要安装jdk和hadoop首先需解决的问题:
- 将本地文件传输到CentOS虚拟机node01中
3.1配置VMware NAT模式
为了在node01中安装传输工具,我们需要先将node01连接到互联网,之前已经设置好node01的IP地址等信息,我们现在需要将VMware中NAT模式下的子网网段和网关IP与node01~node02保持一致。
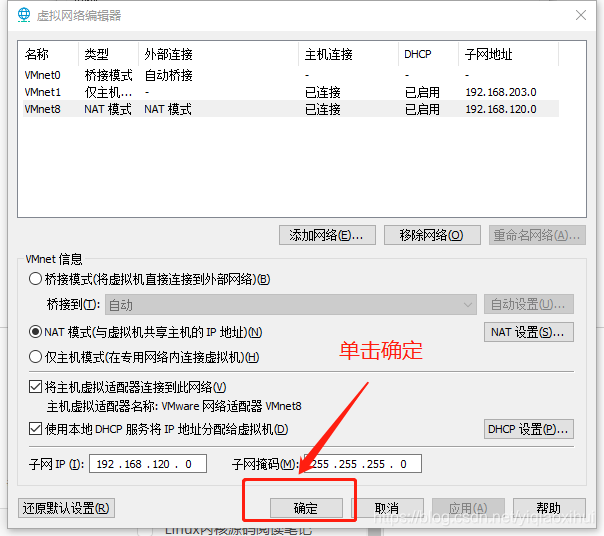
首先,选中VMware菜单下的 "编辑"->"虚拟网络编辑器",会打开如下图所示界面
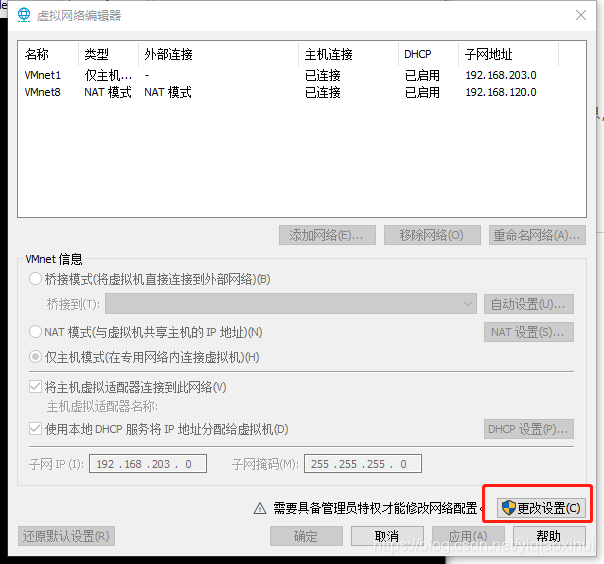
点击上图中的更改设置按钮,在弹出的对话框中点击“是”按钮后,进行如下图所示的操作
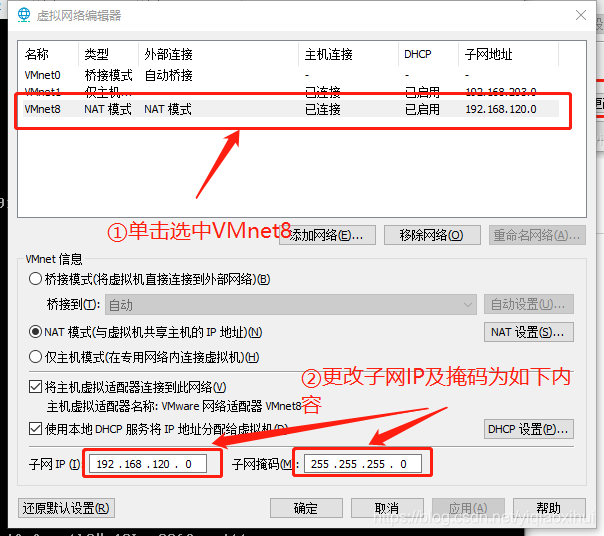
完成上图操作后,进行如下图所示的操作,将出口网关IP与node01中设置的网关IP一致
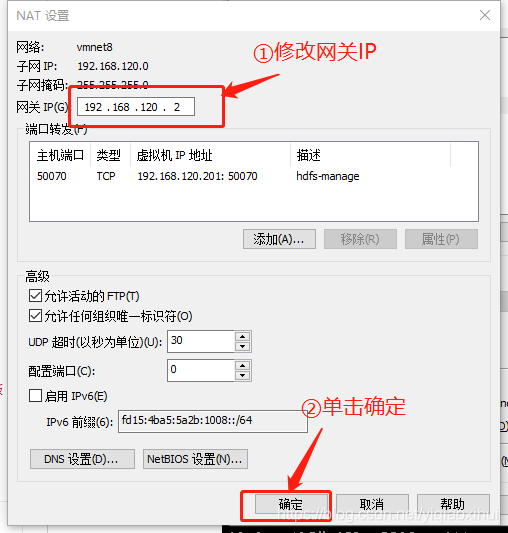
最后,单击虚拟网络编辑器窗口下方的确定按钮完成NAT的设置,如下图所示
回到node01中,输入一下命令测试网络是否连通,当然前提是电脑本身已经连接互联网
ping baidu.com #测试是否连接互联网如果显示如下图所示,则说明已经成功连接到网络

若与上图显示不一致,出现例如“...unreachable...”的字样,原因可以有以下几点
1.ip没有配置成功,判断方法:使用ifconfig命令,查看eth0网卡的配置是否与上述一致
2.dns域名解析文件未修改,参考上述第2.3小节修改确认
3.VMware网络连接模式错误,改为NAT连接模式,方法如下
首先,进行如下图所示操作
然后,执行下图操作

再回到虚拟机中,执行“ping baidu.com”,查看是否成功连接互联网。
3.2 在node01中安装可视化传输工具lrzsz
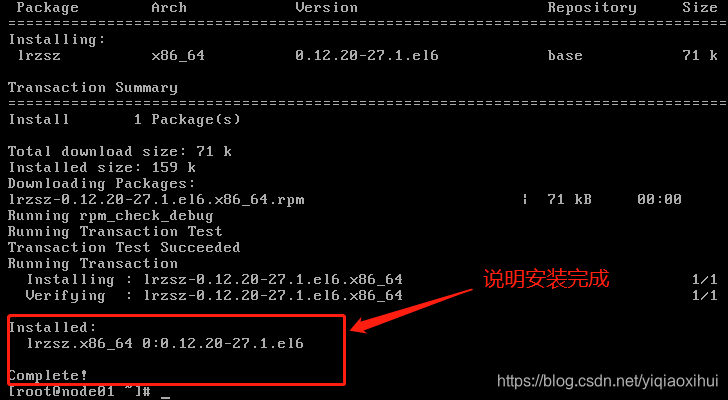
在node01能够连接互联网的前提下,我们在node01中输入以下命令安装lrzsz工具
yum -y install lrzsz如果出现输出如下图的内容,这说明安装lrzsz工具成功
3.3 使用xshell远程连接node01
由于centOS默认终端不支持lrzsz可视化文件传输,我们在自己的电脑上下载安装Xshell远程连接工具,安装完成后,打开Xshell,界面如下图所示

在Xshell中输入以下命令,按回车键 远程连接node01
ssh root@192.168.120.201 #使用Xshell远程连接node01这是会弹出输入登陆密码的窗口,如下图所示
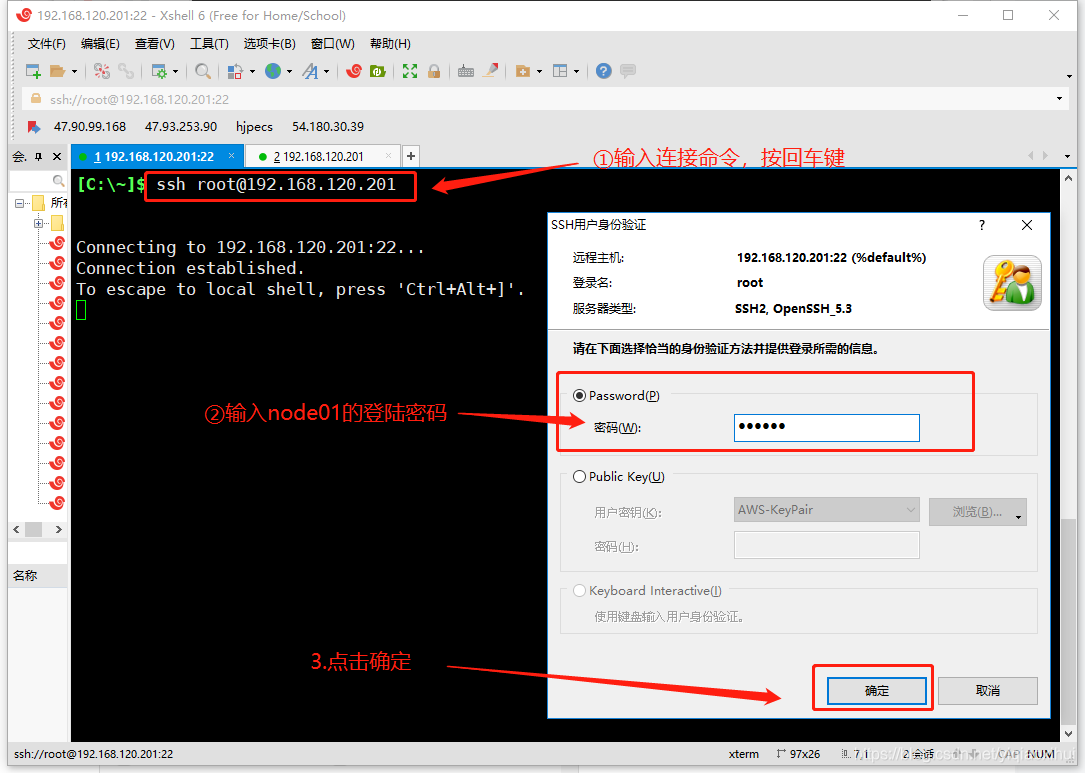
按照上图的指示输入密码后,即可远程登陆node01,登陆成功的界面如下图所示

以后,我们均使用Xshell来操作node01虚拟机,相对于直接在VMware中访问node01虚拟机,比较便捷。
3.4 安装jdk
在3.2中,我们已经使用xshell成功连接node01,我们默认已经使用Xshell成功连接node01,我们在xshell中输入rz,传输jdk到node01中,输入rz并回车后,会跳出选择文件的窗口,选择jdk-7u79-linux-x64.rpm文件并确定,等待文件传输完成即可。
待安装完成后,我们可以使用 "ls" 命令查看node01当前文件夹内容,结果如下图所示

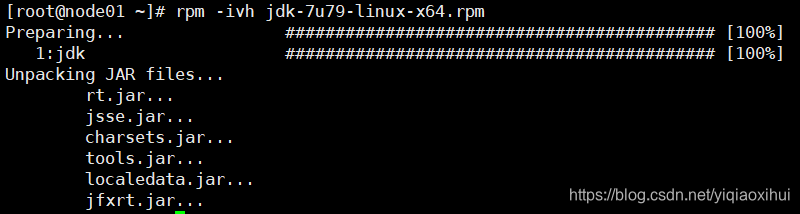
然后,输入如下命令安装jdk
rpm -ivh jdk-7u79-linux-x64.rpm显示如下图所示界面,表示安装jdk成功
接着,将jdk加入环境变量。通过vi命令打开并修改/root/.bashrc文件
vi /root/.bashrc #打开.bashrc文件在.bashrc文件的尾部添加如下内容
export JAVA_HOME=/usr/java/default
export PATH=$JAVA_HOME/bin:$PATH
添加完毕后,保存并退出。执行下面命令使导入的jdk环境变量立即生效
source /root/.bashrc #使jdk环境变量立即生效输入如下命令查看java环境是否设置成功
java -version #查看java版本信息3.5配置多机器间免密码登录
配置免密登陆的目的是在配置hadoop一主三从的分布式环境时,主从之间能够无障碍通信,输入以下命令,按回车键
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa #生成密钥对会在/root/.ssh文件夹下生成一对密钥,即公钥和私钥,如下图所示

公钥相当于锁,私钥相当于钥匙,只要我们将公钥(锁)写入别的机器上authorized_keys文件中,我们就能用私钥(钥匙)进行免密登陆别的机器了。
接着输入以下命令,将公钥写入authorized_keys文件中
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys #将公钥写入authorized_keys文件这样,当后续我们使用VMware虚拟机克隆功能将node01克隆生成node02~04时,这四个虚拟机中authorized_keys文件中写入相同的公钥,并且都与公钥(锁)对应的相同的私钥(钥匙),自然能够进行相互的免密登陆了。
4.安装hadoop
安装hadoop事实上是把hadoop拷贝到node01中,并修改相应的配置文件即可,后续我们将node01克隆生成node02~04,这样相当于每个节点都安装完成了jdk和hadoop。
4.1拷贝hadoop到node01中
首先,我们在/root目录下创建software文件夹,以后要将hadoop安装到这里,进入/root目标,并创建software文件夹,然后进入software文件夹,命令为
cd /root #进入/root文件夹
mkdir software #创建software文件夹
cd software #进入software文件夹接着,使用rz命令从本地将hadoop-2.7.3.tar.gz拷贝到node01的software目录下,其过程与3.4节拷贝jdk的过程一致。
待拷贝完成后,使用如下命令解压hadoop-2.7.3.tar.gz
tar zvxf hadoop-2.7.3.tar.gz #解压hadoop到当然目录为方便起见,在/root下创建链接指向hadoop安装目录,即创建软连接,命令如下
ln –sf /root/software/hadoop-2.7.3/ /root/hadoop #在/root下创建指向/root/software/hadoop-2.7.3/的软连接hadoop同样,将hadoop加入环境变量,首先打开.bashrc文件
vi /root/.bashrc #打开.bashrc文件修改文件内容,修改后文件内容如下
# .bashrc
# User specific aliases and functions
alias rm='rm -i'
alias cp='cp -i'
alias mv='mv -i'
# Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
export JAVA_HOME=/usr/java/default
export HADOOP_PREFIX=/root/software/hadoop-2.7.3
export PATH=$JAVA_HOME/bin:$HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbin:$PATH保存文件后,执行如下命令使其立即生效
source /root/.bashrc然后,执行“hadoop version”来检查是否成功导入环境变量
hadoop version #查看hadoop版本,检查hadoop是否成功加入环境变量4.2修改hadoop配置文件
- 修改hdfs-site.xml文件
hdfs-site.xml文件位于hadoop安装目标下的etc/hadoop目录下,使用如下命令打开该文件
vi /root/software/hadoop-2.7.3/etc/hadoop/hdfs-site.xml #打开hdfs-site.xml文件修改hdfs-site.xml文件中configuration标签内容如下所示
<configuration>
<!--指定hdfs中namenode的存储位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/data/namenode</value>
</property>
<!--指定hdfs中datanode的存储位置-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/data/datanode</value>
</property>
<!--指定hdfs保存数据的副本数量-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>- 修改core-site.xml文件
该文件在相同的目录下,将core-site.xml文件中configuration标签修改为下述内容
<configuration>
<!--指定namenode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>
<!--用来指定使用hadoop时产生文件的存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/data/tmp</value>
</property>
</configuration>- 修改slaves文件,指定datanode
slaves文件同样在相同目录下(/root/software/hadoop-2.7.3/etc/hadoop/),在该文件中添加以下内容,表示指定node02~04为从节点datenode
node02
node03
node04
5.克隆并配置node02~node04
5.1克隆node01生成node02~node04
完成第4节时,已经将node01的hadoop环境配置完成,现在通过直接克隆node01,快速生成node02~node04三个从节点,克隆,不言而喻,即从node01克隆出的node02~node04也已经具备了1~4节的各种配置。
1.关闭虚拟机
克隆虚拟机前,需要将克隆原虚拟机关闭,选择VMware菜单下:虚拟机->电源->关闭虚拟机,将虚拟机关闭
2.开始克隆
选择VMware菜单下:虚拟机->管理->克隆,启动虚拟机克隆向导

点击下一步,显然如下图所示

继续点击下一步,显然如下图所示界面

选择“创建完整克隆”后,点击下一步,界面如下图所示
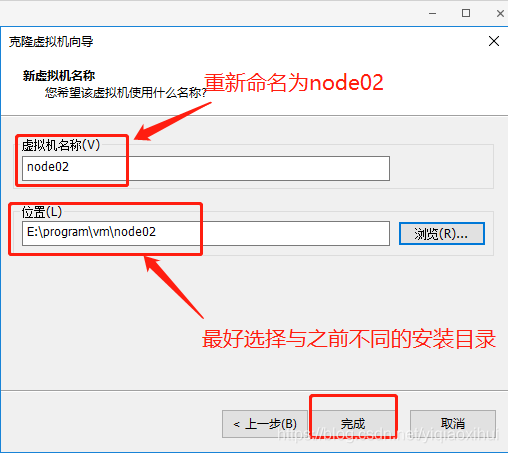
这里填写虚拟机名称为node02,位置最好新建一个不同的目录,避免产生冲突,最后点击完成,开始进行克隆。
等待克隆完成后,会在VMware主界面生成node02的虚拟机实例,如下图所示。
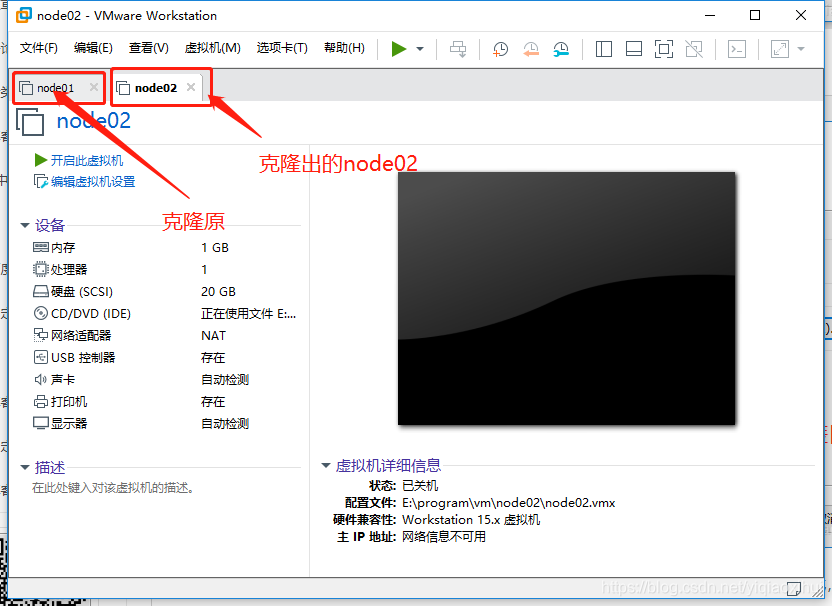
使用同样的方法,从node01中继续克隆出node03、node04,注意克隆过程中的虚拟机命名分别为node03,node04。
5.2配置node02~node04
我们知道克隆后的node02~node04几乎与node01相同,这就意味着node02~node04的:
- 主机名
- 网络配置文件ifcfg-eth0.cfg
都与node01一致,这显然不行,我们要将其改为正确的主机名,并配置正确的IP地址
1.修改网卡IP地址
以node02为例,首先启动node02虚拟机,用户名和登陆密码与node01相同,登陆成功后,输入以下命令删除克隆生成的网卡文件
rm -f /etc/udev/rules.d/70-persistent-net.rules然后重启node02,这样会自动生成正确的网卡信息。
重启后,修改网络配置文件ifcfg-eth0,事实上唯一需要修改的就是IPADDR,打开网络配置文件ifcfg-eth0,命令如下
vi /etc/sysconfig/network-scripts/ifcfg-eth0 #打开网络配置文件修改该文件的内容为如下所示,
DEVICE=eth0
#HWADDR=00:0C:29:BA:FB:80
TYPE=Ethernet
#UUID=81911134-c075-4e7c-a1b9-0b91e30f20e8
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
IPADDR=192.168.120.202 #修改为正确的IP,node03改为103,node04改为104
NETMASK=255.255.255.0
GATEWAY=192.168.120.2修改并保持后,执行激活网卡eth0的命令,命令如下:
ifup eth0 #应用ifcfg-eth0配置文件,激活网卡eth0然后使用ifconfig命令查看网卡是否配置成功,成功的结果如下
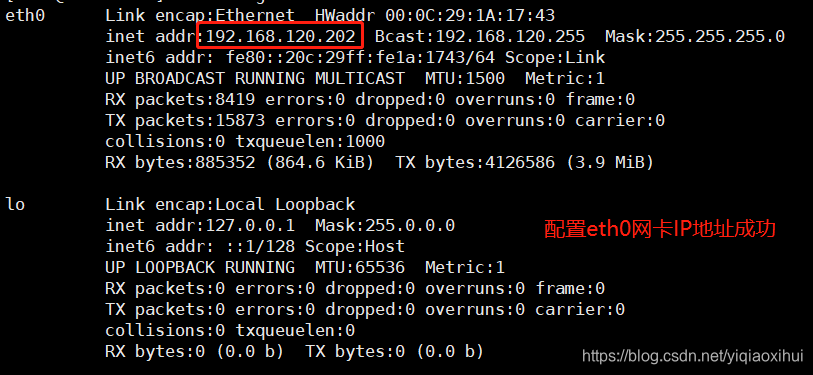
同样,对node03和node04进行依次进行对应的配置
2.修改node02的主机名
使用vi命令打开/etc/sysconfig/network文件,命令如下
vi /etc/sysconfig/network #打开主机名配置文件
将文件其中的node01(由node01克隆而来)修改为node02即可,修改后的内容如下图所示
NETWORKING=yes
HOSTNAME=node02保存并关闭该文件后,重启node02虚拟机后,配置即可生效。
同样,对node03和node04进行依次进行对应的配置。
6.运行HDOOP
经过1-5节,node01~node04已经配置完成,现在我们将node01~node04全部启动
6.1格式化HDFS
在node01上,格式化namenode,运行如下命令进行格式化
hdfs namenode –format若输出的内容只有INFO信息,没有ERROR或FAILED信息,说明格式化成功,输入内容如下图所示
6.2启动hdfs并测试
在node01上,输入以下命令,启动hdfs
start-dfs.sh #启动hdfs成功启动hdfs时,输出信息如下

测试是否启动成功:
- 在各机器上使用jps命令查看,node01上应该有namenode和secondarynamenode两个进程
- node02~04上应该是datanode进程
如下图所示

至此,一主三从的分布式HADOOP环境已经搭建完成。
我们可以选择node01中的任意一个文件,上传到hdfs上,测试是否搭建成功,这里选择/root/install.log文件上传到hdfs上,命令如下
hdfs dfs -put /root/install.log / #将本地/root/install.log文件上传到hdfs的根目录执行该命令后,如果未有任何输出,则说明环境搭建成功,否则根据输出的错误信息或这hadoop/logs文件夹下的日志文件对错误进行排查。
总结
简单的说,搭建此HADOOP环境分为三大步,第一步,先完成node01节点的环境配置,第二步从node01克隆错node02~04并修改相应配置,第三步在node01中运行hdfs。如果软件版本不同或者参数配置错误,会导致各种各样的问题,出现问题分析并追溯原因很重要,还可以借助百度等搜索引擎进行参考,学习搭建HADOOP环境一方面能够锻炼动手和解决问题的能力,同时在配置hadoop各种配置文件过程中也能对hadoop的结构特点进一步熟悉。在配置过程中如有问题或者文章如有纰漏欢迎留言讨论。
参考资料
VMware虚拟机三种网络模式详解--NAT(地址转换模式)
SSH-KEYGEN - GENERATE A NEW SSH KEY
linux系统中打rz命令后出现waiting to receive.**B0100000023be50?
Linux-使用快照克隆虚拟机时删除70-persistent-net.rules
欢迎大家扫描关注公众号:编程真相,向我提问,获取更多精彩的编程技术文章!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









