






前言
平时工作中,肯定会遇到哪个产品经理突然来找,说服务器又挂了,怎么又用不了啦!类似的紧急情况,遇到这种情况不要慌,我提供以下几点紧急补救思路。
1)重启大法保命
2)确认是否新功能发布,线上环境,紧急回退版本
3)查看服务器实例的CPU使用率、内存使用率(arthas)
4)扩充服务器资源,大多数公司上百台微服务,每台微服务实例一般资源都设置不大
5)开启GC日志,分析 xx.hprof文件
总体思路基本围绕上述展开,注意OOM不一定是一蹴而就,也可能是日积月累慢慢产生。
案例分析
紧急回退版本后,分析方向如下
- 数据一次查询读取量过大,之前用Spring Data JPA,由于框架缺陷对@Query注解先计算条数count,才查询sql数据,但框架缺陷不会识别别名,进而不走分页,查了全表数据,就必须手动指定countQuery属性(依此类推)。

- 代码逻辑无限循环,注意是否有递归调用某个方法,或者while(true)的情况,导致栈溢出
- 定时器调用频率过高,注意是不是每分钟执行一次的定时器任务,又是大量消耗资源的
- 单个业务任务过大,导致不能gc释放资源,有的人一个任务,代码写了好几百行,查询的数据很多,内存无法释放,再加上致命的for循环,直接就OOM了,解决思路,解耦放到MQ队列里慢慢消费
- 线程池设置不当,因为单个微服务的资源是有限的且都比较小,如果不是特别对响应快有要求的话,根据实际资源去设置线程池参数,或转换思路,解耦放到MQ队列里慢慢消费
- 资源不足,扩充资源,有些时候并不是代码的问题,而是服务器运行一段时间后就OOM了,这种情况可能是由于业务越来越多,服务运行就是需要更多的内存才能满足日常使用,当你每隔小业务都需要频繁在新生代创建、销毁、创建、销毁的时候,垃圾收集器就会频繁GC,而GC可能会STW或者拉高CPU使用率,最终导致微服务宕机,解决思路,扩充内存资源,降低GC频率。
- 资源已足够,重启大法保命,很多时候不是内存设置太小,而是由于业务需要,内存设置非常大来满足日常需求,但是执行到几天后已经会有OOM或则服务器卡顿现象,比如很多游戏公司,解决思路,比如每天凌晨1点服务器维护10分钟,其实就是重启服务器。
举例实操
以上就是分析的方向,除了刚上线的代码,自己知道可能是哪个地方有问题之外,其余情况还是要看服务器的GC时的运行情况,这使用就要使用一些工具或者看GC日志,两个方向,以下再举个例子,让大家看看我遇到OOM分析时的步骤
- 查看实时服务器运行情况(用到 arthas分析)
- 分析GC时日志(用到 JProfiler分析 xx…hprof)
# Windows安装:打开控制台
curl -O https://arthas.aliyun.com/arthas-boot.jar
查看实时服务器运行情况(docker 举例)
1)使用docker stats: 查看docker容器情况,现在的服务一般都部署到docker容器中,看看正常情况下的cpu使用率、内存使用

2)进入docker容器内部:docker exec -it 48e /bin/sh
3) top 、free、df、jmap -histo:live PID :经典四件套,看看能哪个进程耗资源,知道PID号,然后等等重点对该进程分析
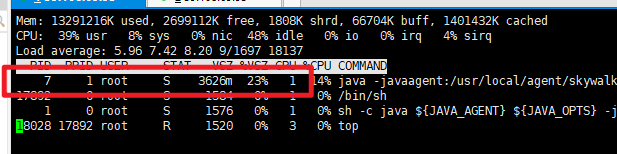
4)使用arthas分析服务器(进程),查看具体内部情况,把前面下载的arthas-boot.jar 复制到docker容器内部, 然后执行
java -jar arthas-boot.jar
中间会卡顿让你选哪个进程,我们选刚刚确定的 PID为7的 敲回车或则1

5) 使用 dashboard 命令:查看服务器情况,看看内存的平局使用是否超过50%,导致频次GC,看看GC线程的cpu使用率, 看看某一个线程的运行CPU使用率,是否需要资源扩容

5)使用命令 thread ID号:如果内存够用,也没有频繁GC,可以看看CPU占用搞的线程在执行什么任务
6)设置java运行环境内存大小:如果确实需要扩容内存了,可以调节各种内存阈值 -XX
docker inspect 容器ID
JAVA_OPTS=-Dio.netty.noUnsafe=true -XX:+UseG1GC -XX:+UseContainerSupport -XX:InitialRAMPercentage=60.0 -XX:MinRAMPercentage=60.0 -XX:MaxRAMPercentage=60.0 -XX:MaxGCPauseMillis=100 -XX:MaxMetaspaceSize=512m -XX:CompressedClassSpaceSize=256m -XX:MetaspaceSize=256m -XX:MaxDirectMemorySize=256m -XX:InitialCodeCacheSize=258m -XX:ReservedCodeCacheSize=258m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./ -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -Xloggc:./gc.log -XX:+PrintHeapAtGC -XX:+PrintTenuringDistribution -XX:GCLogFileSize=2M
arthas分析服务器运行情况的步骤基本就是以上几点,也可以通过敲其他分析命令进一步分析,到此基本可以确定是不是服务器的内存是不是接近临界值,由于业务量增多需要扩容情况
分析GC时日志
1)开启GC快照设置,设置日志位置,最后的会生成 java_pid7.hprof文件
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./ //开启日志快照,以及快照位置
-XX:+PrintGC //输出GC日志,默认是关闭的
-XX:+PrintGCDetails //输出GC的详细日志,默认是关闭
-XX:+PrintGCTimeStamps //输出GC的时间戳,以基准时间的形式
-XX:+PrintGCDateStamps // 输出GC的时间戳,以日期的形式(类似于2022-04-01T14:21:33.438+0800)
-XX:+UseConcMarkSweepGC //打开此开关参数后,使用ParNew+CMS+Serial Old收集器组合进行垃圾收集。Serial Old作为CMS收集器出现Concurrent Mode Failure的备用垃圾收集器。
-Xloggc:C:\Users\DXH\Desktop\gc.txt//指定将GC日志输出到具体的文件,默认为标准输出
2)复制docker中的java_pid7.hprof文件, 进入docker容器,如何设置了HeapDumpPath=./ 默认ls就可以看到文件,在docker外面执行cp命令
docker cp 容器ID:./xxx.hprof ./xxx.hprof
3)使用JProfiler分析工具

4)通过查看分析工具的类信息, 最大内存信息,辅助我们分析代码问题,例如看看哪个类最大,最大的对象有哪些

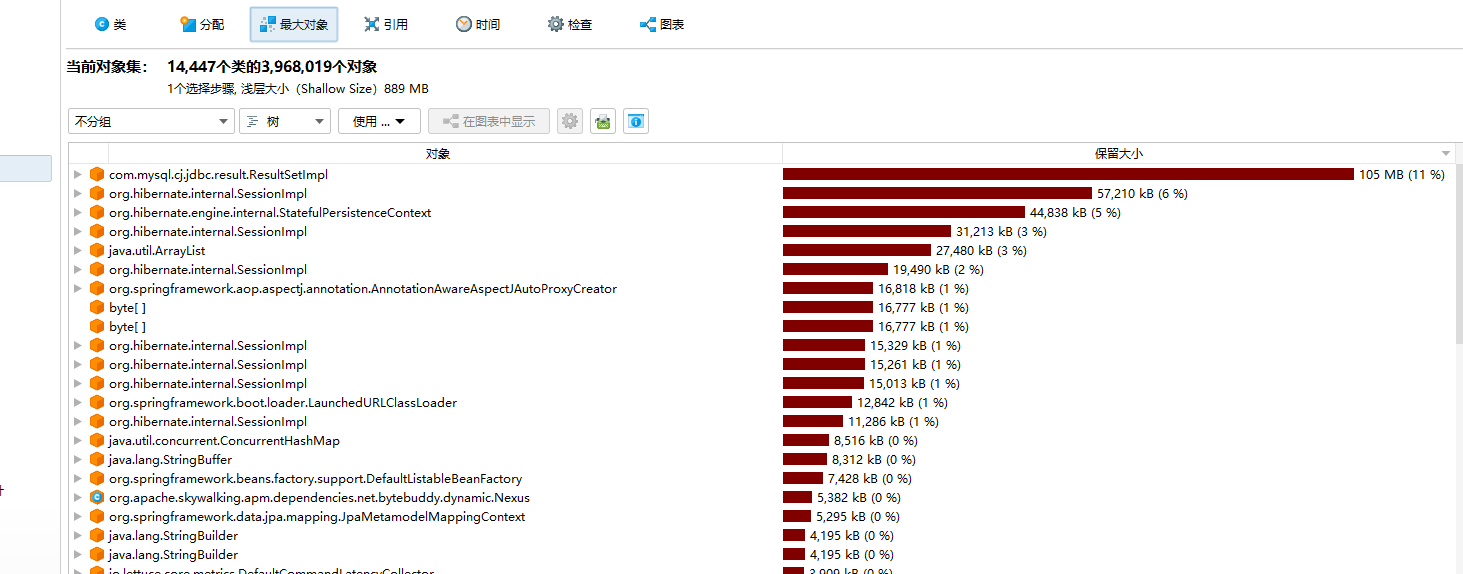
5)右键查看某个大对象集合的引用情况,合并引用进行分析,多看看哪个类大了


总结
以上就是思考和分析OOM的可能出现场景和方法,顺着这么一套下来,基本可以具体时业务激增导致需要服务器扩容,还是代码问题导致的栈溢出和内存泄漏。
注意:频繁GC是十分消耗服务器性能的,大任务就多解耦,防止内存剧增,OOM不一定是一蹴而就,也可能是日积月累慢慢产生。
















 688
688











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









