







 Spark是加州大学伯克利分校AMP实验室开发的内存并行计算框架,作为Hadoop的潜在替代品,具有运行速度快、易用性好、通用性强和随处运行等特点。相较于Hadoop,Spark通过内存计算提升了迭代计算效率,具有更高的容错性和更强的通用性。Spark生态圈包括Spark Core、Spark SQL、Spark Streaming、MLLib和GraphX等组件,提供一站式大数据处理解决方案。Spark适用于需要多次操作特定数据集、实时统计分析和交互式查询的场景。目前,Spark已被腾讯、Yahoo和淘宝等公司广泛应用在广告、推荐系统等领域。
Spark是加州大学伯克利分校AMP实验室开发的内存并行计算框架,作为Hadoop的潜在替代品,具有运行速度快、易用性好、通用性强和随处运行等特点。相较于Hadoop,Spark通过内存计算提升了迭代计算效率,具有更高的容错性和更强的通用性。Spark生态圈包括Spark Core、Spark SQL、Spark Streaming、MLLib和GraphX等组件,提供一站式大数据处理解决方案。Spark适用于需要多次操作特定数据集、实时统计分析和交互式查询的场景。目前,Spark已被腾讯、Yahoo和淘宝等公司广泛应用在广告、推荐系统等领域。
【注】该系列文章以及使用到安装包/测试数据 可以在《倾情大奉送–Spark入门实战系列》获取
1、简介
1.1 Spark简介
Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处,Spark以其先进的设计理念,迅速成为社区的热门项目,围绕着Spark推出了Spark SQL、Spark Streaming、MLLib和GraphX等组件,也就是BDAS(伯克利数据分析栈),这些组件逐渐形成大数据处理一站式解决平台。从各方面报道来看Spark抱负并非池鱼,而是希望替代Hadoop在大数据中的地位,成为大数据处理的主流标准,不过Spark还没有太多大项目的检验,离这个目标还有很大路要走。
Spark使用Scala语言进行实现,它是一种面向对象、函数式编程语言,能够像操作本地集合对象一样轻松地操作分布式数据集(Scala 提供一个称为 Actor 的并行模型,其中Actor通过它的收件箱来发送和接收非同步信息而不是共享数据,该方式被称为:Shared Nothing 模型)。在Spark官网上介绍,它具有运行速度快、易用性好、通用性强和随处运行等特点。
运行速度快
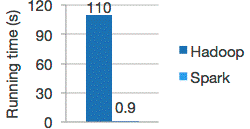
Spark拥有DAG执行引擎,支持在内存中对数据进行迭代计算。官方提供的数据表明,如果数据由磁盘读取,速度是Hadoop MapReduce的10倍以上,如果数据从内存中读取,速度可以高达100多倍。
易用性好
Spark不仅支持Scala编写应用程序,而且支持Java和Python等语言进行编写,特别是Scala是一种高效、可拓展的语言,能够用简洁的代码处理较为复杂的处理工作。通用性强
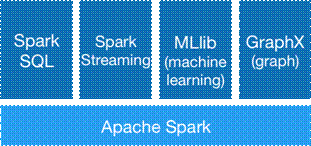
Spark生态圈即BDAS(伯克利数据分析栈)包含了Spark Core、Spark SQL、Spark Streaming、MLLib和GraphX等组件,这些组件分别处理Spark Core提供内存计算框架、SparkStreaming的实时处理应用、Spark SQL的即席查询、MLlib或MLbase的机器学习和GraphX的图处理,它们都是由AMP实验室提供,能够无缝的集成并提供一站式解决平台。
随处运行
Spark具有很强的适应性,能够读取HDFS、Cassandra、HBase、S3和Techyon为持久层读写原生数据,能够以Mesos、YARN和自身携带的Standalone作为资源管理器调度job,来完成Spark应用程序的计算。

1.2 Spark与Hadoop差异
Spark是在借鉴了MapReduce之上发展而来的,继承了其分布式并行计算的优点并改进了MapReduce明显的缺陷,具体如下:
首先,Spark把中间数据放到内存中,迭代运算效率高。MapReduce中计算结果需要落地,保存到磁盘上,这样势必会影响整体速度,而Spark支持DAG图的分布式并行计算的编程框架,减少了迭代过程中数据的落地,提高了处理效率。
其次,Spark容错性高。Spark引进了弹性分布式数据集RDD (Resilient Distributed Dataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,则可以根据“血统”(即充许基于数据衍生过程)对它们进行重建。另外在RDD计算时可以通过CheckPoint来实现容错,而CheckPoint有两种方式:CheckPoint Data,和Logging The Updates,用户可以控制采用哪种方式来实现容错。
最后,Spark更加通用。不像Hadoop只提供了Map和Reduce两种操作,Spark提供的数据集操作类型有很多种,大致分为:Transformations和Actions两大类。Transformations包括Map、Filter、FlatMap、Sample、GroupByKey、ReduceByKey、Union、Join、Cogroup、MapValues、Sort和PartionBy等多种操作类型,同时还提供Count, Actions包括Collect、Reduce、Lookup和Save等操作。另外各个处理节点之间的通信模型不再像Hadoop只有Shuffle一种模式,用户可以命名、物化,控制中间结果的存储、分区等。
1.3 Spark的适用场景
目前大数据处理场景有以下几个类型:
复杂的批量处理(Batch Data Processing),偏重点在于处理海量数据的能力,至于处理速度可忍受,通常的时间可能是在数十分钟到数小时;
基于历史数据的交互式查询(Interactive Query),通常的时间在数十秒到数十分钟之间
基于实时数据流的数据处理(Streaming Data Processing),通常在数百毫秒到数秒之间
目前对以上三种场景需求都有比较成熟的处理框架,第一种情况可以用Hadoop的MapReduce来进行批量海量数据处理,第二种情况可以Impala进行交互式查询,对于第三中情况可以用Storm分布式处理框架处理实时流式数据。以上三者都是比较独立,各自一套维护成本比较高,而Spark的出现能够一站式平台满意以上需求。
通过以上分析,总结Spark场景有以下几个:
Spark是基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合。需要反复操作的次数越多,所需读取的数据量越大,受益越大,数据量小但是计算密集度较大的场合,受益就相对较小
由于RDD的特性,Spark不适用那种异步细粒度更新状态的应用,例如web服务的存储或者是增量的web爬虫和索引。就是对于那种增量修改的应用模型不适合
数据量不是特别大,但是要求实
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1136
1136

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









