










链表去重
试题名称 3-1 链表去重
问题描述:
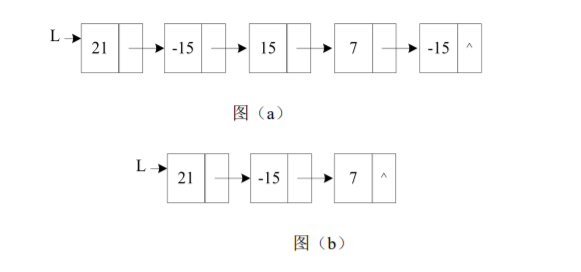
给定一个键值为整数的单链表 L,将键值的绝对值有重复的结点删除:即对任意键值 K,只有键值或其绝对值等于 K 的第一个结点被保留在 L 中。例如,下面单链表 L 包含键值 21、-15、15、7、-15,如下图(a)所示;去重后的链表 L 包含键值 21、-15、7,如下图(b)所示。
输入说明:
输入的第一行包含两个整数,分别表示链表第一个结点的地址和结点个数 n(1≤n≤100)。结点地址是一个非负的 5 位整数,NULL 指针用-1 表示。
随后 n 行,每行含 3 个整数,按下列格式给出一个结点的信息:
Address Key Next
其中 Address 是结点的地址,Key 是绝对值不超过 10000 的整数,Next 是下一个结点的地址。
输出说明:
输出的第一行为去重后链表 L 的长度,换行;接下来按顺序输出 L 的所有结点,每个结点占一行,按照 Address Key Next 的格式输出,间隔 1 个空格。
测试样例:
输入样例 1
00100 5
99999 7 87654
23854 -15 00000
87654 -15 -1
00000 15 99999
00100 21 23854
输出样例 1
3
00100 21 23854
23854 -15 99999
99999 7 -1
#include<iostream>
#include<cstdlib>
#include<algorithm>
using namespace std;
typedef struct Node {//结点类型定义
int add;//该结点地址
int data;//结点保存的数值
int nextAdd;//下一个结点地址
bool flag ;//标志位
}Node, * List;
int searchAdd(Node* p,int nextAdd ,int n);
int main() {
/*
*head和n即为输入的首地址和输入节点个数
*i,j为控制循环次数变量
*m用处暂时不介绍
*index用来输出去重后链表中元素个数
*/
int head, n,i,j,m,index=0;
cin >> head >> n;
index = n;
Node* p;
p = (Node*)malloc(n * sizeof(Node));//定义一个大小为n的自定义结构体Node类型数组
for (i = 0; i < n; i++) {//输入部分
cin >> p[i].add >> p[i].data >> p[i].nextAdd;
p[i].flag =true;//先全部设为true,该链表用数组实现,最后输出时如果为true就输出,为false就不输出
if (p[i].add == head)
m = i;
/*
这个m用来记录和首地址head对应的那个结点的位置
以用例为例:00100
结点 00100 21 23854 为输入的第五个结点,m记录为4.(p数组下标从0开始)
*/
}
i = 0;
while (p[m].nextAdd != -1) {//将乱序的输入依据首尾地址变得有序,链表用数组实现
swap(p[i], p[m]);
p[i].flag = true;
m = searchAdd(p, p[i].nextAdd, n);
i++;
}
for (i = 1; i < n; i++) {//去重环节
for (j = 0; j < i; j++) {
if (p[j].data == p[i].data || p[j].data == -p[i].data) {
p[i].flag = false;//将重复的标志位标记为false,最终打印时不输出
index--;
break;
}
}
}
/*
输出部分不介绍了,自己看吧
*/
printf("%d\n", index);
printf("%05d %d ", p[0].add, p[0].data);
for (i = 1; i < n; i++) {
if (p[i].flag) {
printf("%05d\n%05d %d ", p[i].add, p[i].add, p[i].data);
}
}
printf("-1");
return 0;
}
int searchAdd(Node* p,int nextAdd, int n) {
for (int i = 0; i < n; i++) {
if (p[i].add == nextAdd)
return i;
}
}
ps:如有错误敬请指正,如有问题欢迎评论区讨论或私信。如果未及时回复请微信私聊我。
微信号: z1654407501
如果对你有用的话,请点赞并关注支持一波.


















 618
618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











