









问题
现有采集流程使用Kettle执行采集文件,通过shell脚本定时执行采集文件,但是随着表数量、数量增加,特别是采集出现依赖关系后,一个采集文件重复执行多次,kettle占用cpu的问题就显现出来。后来采用springboot整合kettle,发现了一个半开源的免费项目–smartkettle。
smartkettle可以解决频繁启动kettle而导致的cpu占用问题,但之前的采集文件中包含的ktr文件路径为了方便移植,都是使用${Internal.Entry.Current.Directory}内置变量写的,不使用kettle执行后,这个变量就不生效了,直接报错,无法找到ktr文件了。
解决过程
(1)临时处理方案:修改job文件,将ktr文件的路径都改成的绝对路径。但每个采集文件都要修改,费时费力。
(2)将
I
n
t
e
r
n
a
l
.
E
n
t
r
y
.
C
u
r
r
e
n
t
.
D
i
r
e
c
t
o
r
y
维护到执行参数中,但是这个变量是
k
e
t
t
l
e
的内置变量,和普通的变量替换还不一样,不生效,还是找不到。(
3
)查资料后,发现
k
e
t
t
l
e
会取系统变量,查询系统变量后发现果然没有
{Internal.Entry.Current.Directory}维护到执行参数中,但是这个变量是kettle的内置变量,和普通的变量替换还不一样,不生效,还是找不到。 (3)查资料后,发现kettle会取系统变量,查询系统变量后发现果然没有
Internal.Entry.Current.Directory维护到执行参数中,但是这个变量是kettle的内置变量,和普通的变量替换还不一样,不生效,还是找不到。(3)查资料后,发现kettle会取系统变量,查询系统变量后发现果然没有{Internal.Entry.Current.Directory},这个变量。那么手动给一个:
// 查看系统变量
Properties properties = System.getProperties();
for(Map.Entry entry : properties.entrySet()){
System.out.println("系统属性key:" + entry.getKey());
System.out.println("系统属性value:" + entry.getValue());
}
//手动补变量
properties.put("Internal.Entry.Current.Directory","D:\\kettle"); properties.put("KETTLE_HOME","D:\\kettle");
properties.put("user.dir","D:\\kettle");
System.setProperties(properties);
补充后发现,在job.start()之前还是对的,但是执行时还是找不到。
(4)那么推测是在执行job之前初始化变量,被改掉了。找到job类的run方法,发现了下面这个方法:
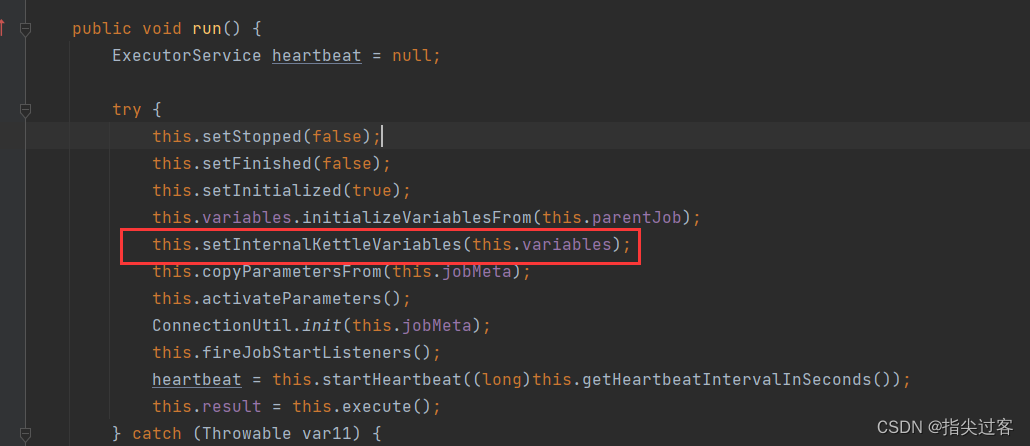
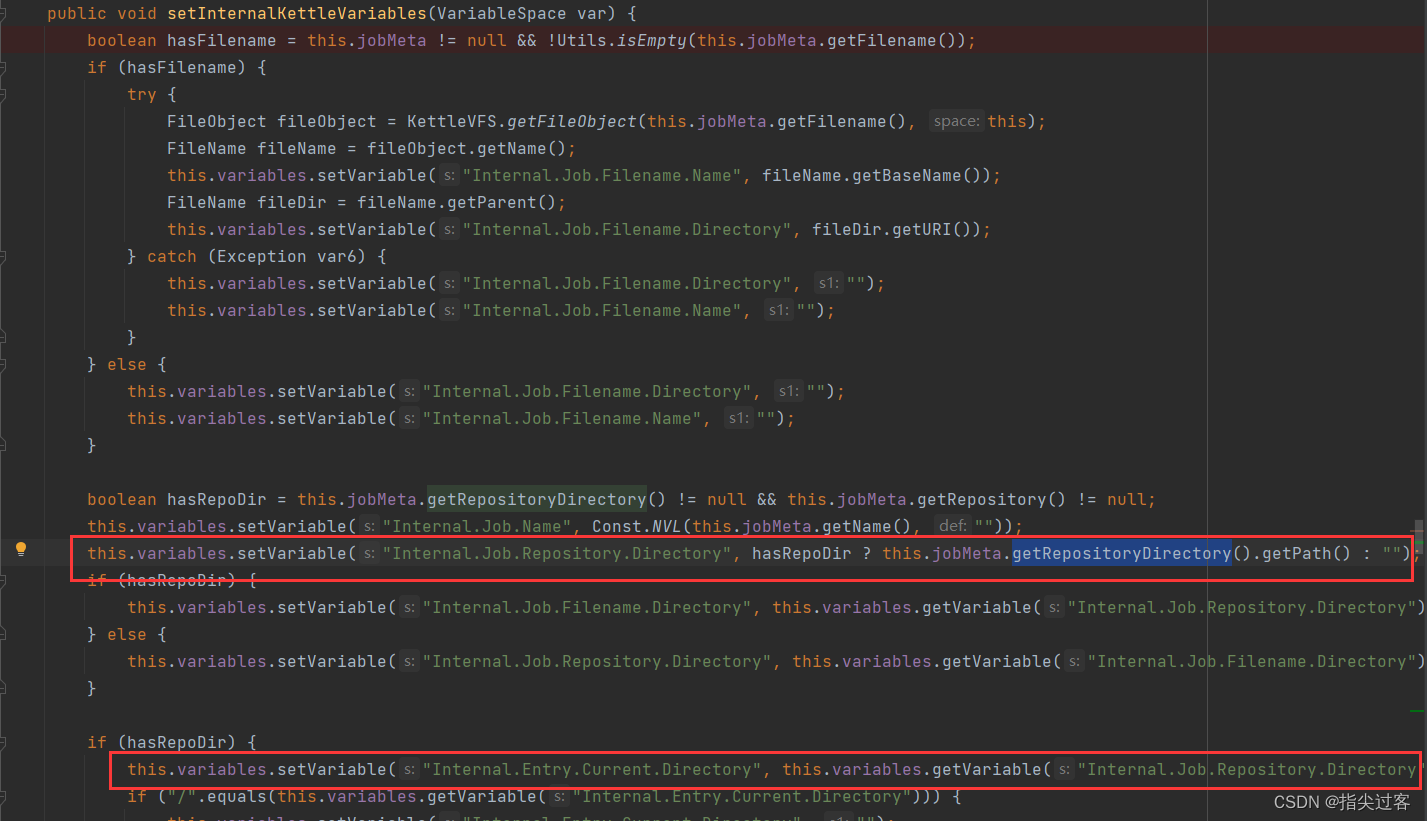
这里处理的变量${Internal.Entry.Current.Directory},之前手动给的变量不生效就是在这里被替换掉了。
那么手动补一下
this.jobMeta.getRepositoryDirectory().getPath()这个变量,应该就可以了
jobMeta.setRepositoryDirectory(new RepositoryDirectory(new RepositoryDirectory(null, null),"D://kettle"));
再执行,路径被替换,不再报错。
这样,一个采集文件维护一个参数就可以了。
















 336
336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









