







目前,主流的全文索引工具有:Lucene , Sphinx , Solr , ElasticSearch。其中Solr和Elastic Search都是基于Lucene的。Sphinx不是 apache的项目,如果你想把Sphinx放到某个商业性的项目中,你就得买个商业许可证。
此文章为个人学习备忘之用,仅适合lucene的初学者参考阅读。至于lucene能做什么,自己百度就好,这里就不多说了。本文为lucene-3.6.1的学习笔记,是当前最稳定的版本。当前最新版本为lucene-4.3,各版本之间变动较大。
对于想继续深入研究Lucene的,推荐一本史诗级的作品《LUCENE IN ACTION》,有中文版。当然,这本书写的比较早,是以JAVA语言为基础的2.4版本的教程,其中对lucene的核心、API和高级应用都做了非常详细的介绍。虽然现在很多方法发生了改变,但此书依然具有极佳的学习和参考价值。
在语言能力允许的情况下,还是推荐广大热爱学习IT技术的朋友去找点英文资料看看。一位大神曾经说过:想要在技术上与世界接轨,就必须先在语言上与国际接轨。我惭愧:英语是我的硬伤。大神说:学好哲学、数学和英语之后,再之后的学习就毫无压力了。我掩面而走:我的数学比英语伤的还重。
由于此笔记作者实在太懒,这点东西断断续续写了近两个月。可以说,这完全是一个锻炼毅力的产出品。作者本身才疏学浅,所写的内容自然也不会有太大的深度和内涵。废话结束,开始。
第一章 LUCENE基础
在全文索引工具中,都是由这样的三部分组成:索引部分、分词部分和搜索部分。
1.1 索引部分的核心类
IndexWriter:用来创建索引并添加文档到索引中。
Directory:这个类代表了索引的存储的位置,是一个抽象类。
Analyzer:对文档内容进行分词处理,把分词后的内容交给 IndexWriter来建立索引。
Document:由多个Field组成,相当于数据库中的一条记录。
Field:相当于数据库中的一条记录中的一个字段。
1.2分词部分的核心类
Analyzer:简单分词器(SimpleAnalyzer)、停用词分词器(StopAnalyzer)、空格分词器(WhitespaceAnalyzer)、标准分词器(StandardAnalyzer)。
TokenStream:可以通过这个类有效的获取到分词单元信息。
Tokenizer:主要负责接收字符流Reader,将Reader进行分词操作。
TokenFilter:将分词的语汇单元,进行各种各样过滤。
1.3搜索部分的核心类
IndexSearcher:用来在建立好的索引上进行搜索。
Term:是搜索的基本单位。
Query:把用户输入的查询字符串封装成Lucene能够识别的Query。
TermQuery:是抽象类Query的一个子类,它的构造函数只接受一个参数,那就是一个Term对象。
TopDocs:保存返回的搜索结果。
SocreDoc:保存具体的Document对象。
第二章 索引建立
索引的建立是将现实世界中所有的结构化和非结构化数据提取信息,创建索引的过程。如下图:(本章节完整代码见附件package kecheng.jichu.index;)

2.1创建Directory
privateDirectorydirectory =null;
directory = FSDirectory.open(new File("D:/Test/index/index02"));
//一般使用FSDirectory,它会自动选择适合当前环境的实现
directory = new RAMDirectory();
//RAMDirectory()是将索引保存到内存中,速度快,但不能持久.
2.2创建Writer
IndexWriter writer =null;
IndexWriterConfig iwc =new IndexWriterConfig(Version.LUCENE_36, newStandardAnalyzer(Version.LUCENE_36));
//创建标准分词器(声明lucene版本)
writer = newIndexWriter(directory,iwc);
2.3创建文档并且添加索引
Document doc = newDocument();
//创建域(文本存储)
doc.add(newField( "id","2",Field.Store.YES,Field.Index.NOT_ANALYZED_NO_NORMS ));
//创建域(数字存储)
doc.add(newNumericField( "attach",Field.Store.YES,true).setIntValue(attachs[i]));
Map<String,Float>scores =newHashMap<String,Float>();//加权值Map
scores.put("163.com", 2.0f); //设置163邮箱的加权值为2.0f
scores.put("sina.com", 1.5f); //设置sina邮箱的加权值为1.5f
String et = emails[i].substring(emails[i].lastIndexOf("@")+1);
if(scores.containsKey(et)){ //如果scores中包含这个et
doc.setBoost(scores.get(et)); //使用Map中相应的加权值
}else{
doc.setBoost(0.5f); //否则设置加权值为0.5f
}
writer.addDocument(doc); //添加索引
其他属性:
Field.Store.YES:存储。该值可以被恢复(还原)。
NO:不存储。该值不可以被恢复,但可以被索引。
Field.Index.ANALYZED:分词。
NOT_ANALYZED:不分词。
NOT_ANALYZED_NO_NORMS:不分词也不加权(即不存储NORMS信息)。
备注:NORMS是存储索引创建时间和相关性评分的。权值越大,默认搜索出来越靠前。
2.4查询索引的基本信息
IndexReader reader = IndexReader.open(directory);
//通过reader获取文档数量
System.out.println("numDocs:"+reader.numDocs());
其他属性:
reader.numDocs():存储的文档数。
maxDoc():最大文档数(包括已删除至回收站的文档)。
numDeletedDocs():被删除的文件数。
getVersion():版本信息(Long)。
hasDeletions():判断回收站有没有被删除的索引,返回true或false。
2.5删除和更新索引
(1)使用writer删除
writer.deleteDocuments(new Term("id","1"));//删除指定项文档(id为1的)
备注:
①此时删除的文档并没有被完全删除,而是存储在回收站中,可以被恢复。
②deleteDocuments()中的参数可以是一个Query,也可以是一个Term,Term是一个精确查找的值。
(2) 使用reader删除
reader.deleteDocuments(new Term("id","1"));//此方法已不提倡使用
reader.close();//在关闭时提交信息
备注:
①此时删除的文档并没有被完全删除,而是存储在回收站中,可以被恢复。
②如果已删除的值依然可以被查询,请检查reader是否已关闭(信息在关闭时提交)。
(3) 恢复删除
//恢复时,需要将IndexReader的只读(ReadOnly)设置成false
IndexReader reader = IndexReader.open(directory,false);
reader.undeleteAll();
备注:不清楚为什么会给个横线,暂时没找到替代方法。
(4) 彻底删除
writer.forceMergeDeletes();//清空回收站
writer.deleteAll(); //清空索引(包括回收站)
备注:在3.5版本之前,都是使用optimize()方法,但是这个方法消耗资源,已被弃用。
(5) 更新索引
//创建新的doc
Document doc = new Document();
doc.add(new Field("id","11",Field.Store.YES,Field.Index.NOT_ANALYZED_NO_NORMS));
doc.add(new Field("email","he@163.com",Field.Store.YES,Field.Index.NOT_ANALYZED));
//用新建的doc替换原id为1的doc
writer.updateDocument(new Term("id","1"), doc);
备注:Lucene本身并没有提供更新方法,它的更新操作其实是如下两个操作的合集:先删除,再添加。
(6) 手动优化
writer.forceMerge(2);
//会将索引合并为2段,这两段中的被删除的数据会被清空。
writer.commit();
//如果writer的生命周期没有结束,即不在finally中关闭,那么就需要使用commit提交。
备注:此方法在3.5之后不建议使用,因为会消耗大量的开销,lucene会自动处理的。
2.6 索引文件作用
索引建立成功后,会自动在磁盘上生成一些不同后缀的文件(如下图),这些文件缺一不可,这里简单的介绍下不同后缀名的文件都有些什么作用:

.fdt : 保存域的值(即Store.YES属性的文件)。
.fdx : 与.fdt的作用相同。
.fnm :保存了此段包含了多少个域,每个域的名称及索引方式。
.frq : 保存倒排表。数据出现次数(哪篇文章哪个词出现了多少次)。
.nrm : 保存评分和排序信息。
.prx : 偏移量信息。倒排表中每个词在包含此词的文档中的位置。
.tii : 保存了词典(Term Dictionary)。也即此段包含的所有的词按字 典顺序的排序。
.tis : 同上。存储索引信息。
备注:
①如上图,具有相同前缀文件的属同一个段,图中共两个段 "_0"和 "_1"。
②一个索引可以包含多个段,段与段之间是独立的,添加新文档可以生成新的段,不同的段可以合并。
③这些索引文件可以使用使用lukeall-3.5.0.jar打开,具体使用方法在后面的章节进行详述。
第三章 搜索功能
在工作中,使用最多的搜索是通过QueryParser类将用户输入的文本条件转换成Query对象。本章节完整代码详见附件package kecheng.jichu.searcher。
3.1 简单搜索
(1) 创建IndexReader
Directory directory =FSDirectory.open(new File("D:/Test/index/index01"));
IndexReader reader = IndexReader.open(directory);
(2) 创建IndexSearcher
private IndexReader reader;
IndexSearcher searcher = getIndexSearcher(directory);
public IndexSearcher getIndexSearcher(Directory directory){
try {
if(reader==null){ //reader为空,创建新的IndexReader
reader = IndexReader.open(directory);
}else{ //reader不为空,重新打开
IndexReader tr = IndexReader.openIfChanged(reader);
if(tr!=null){
reader.close(); reader = tr;
}
}
return new IndexSearcher(reader);
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
备注:IndexSearcher根据IndexReader获取,IndexReader一般以单例模式创建。
(3) 创建Term和TermQuery
//查找索引中,域name的值为“john”的数据。
Query query =new TermQuery(new Term("name","john"));
备注:TermQuery为精确匹配查询,索引值与查询值(john)必须完全相同。
(4) 根据TermQuery获取TopDocs
TopDocs tds = searcher.search(query, 10); //返回10条数据
(5) 根据TopDocs获取ScoreDoc
ScoreDoc sd = tds.scoreDocs[0];
备注:这种方法仅适合返回一条数据时使用。一般采用遍历的方式,如(6)。
(6) 根据ScoreDoc获取相应文档
for(ScoreDoc sd : tds.scoreDocs){ //遍历结果集
Document doc = searcher.doc(sd.doc);
System.out.println(doc.getBoost()+","+doc.get("name"));
}
3.2其他搜索
这里简单的测试下常见的查询方法,实际工作中BooleanQuery是比较重要的,经常和QueryParser结合使用。示例中的索引文件皆使用如下数据和输出语句:
private String[] ids = {"1","2","3","4","5","6"};//邮件ID
private String[] emails = {"aa@163.com","bb@163.com","cc@sina.com","dd@sina.com","ee@yahoo.com","ff@yahoo.com"};
private String[] contents= {"welcome to qinghai,I like food",
"hello boy,I like pingpeng ball",
"my name is cc,I like game",
"I like football",
"I like reading book,and I like girl",
"I like brid,I want fly"};//邮件内容
private int[] attachs = {2,3,1,4,5,5}; //附件个数
private String[] names = {"zhangsan","lisi","john","jetty","mike","jack"};//发件人姓名
private Date[] dates = new Date[ids.length]; //日期
dates[0] = new Date[ids.length];
dates[1] = sdf.parse("2011-11-09");
dates[2] = sdf.parse("2012-01-01");
dates[3] = sdf.parse("2010-11-12");
dates[4] = sdf.parse("2009-09-17");
dates[5] = sdf.parse("2008-10-19");输出语句:
System.out.println("一共查询了:"+tds.totalHits);
System.out.println(sd.doc+"-"+doc.getBoost()+"-"+sd.score+","+
doc.get("name")+"["+doc.get("email")+"]-->"+doc.get("id")+","
+doc.get("attach")+","+doc.get("date"));
(1) 范围查询(TermRangeQuery)
//new TermRangeQuery(查询的域,开始,结束,是否包含开始值,是否包含结束值);
Query query =new TermRangeQuery("name","l","m",true,true);
输出结果:

备注:这个结果显然是有问题的,结束值m并没有被包含在内。具体原因有待研究。
(2) 数字查询(NumericRangeQuery)
//括号内(查询的域,开始,结束,是否包含开始值,是否包含结束值);
Query query = NumericRangeQuery.newIntRange("attach", 4, 5, true,true);
输出结果:

备注:这个结果没有问题。输出的倒数第二个值是我们查询的条件。
(3) 前缀查询(PrefixQuery)
//查询name以j开头的
Query query =new PrefixQuery(new Term("name","j"));
输出结果:

备注:顺便说下,由于建立索引的时候,所有的英文字母都会被自动转换为小写,所以查询值都应该使用小写字母。
(4) 通配符查询(WildcardQuery)
//在传入的value中,可以使用通配符(?或*)
Query query =new WildcardQuery(new Term("email","*@16?.com"));
输出结果:

备注: *代表任意个字符,?代表一个字符。但这种查询方式效率较低,尤其是把通配符放在查询条件前面的时候。
(5) 多条件查询(BooleanQuery)
//查询name为zhangsan,且content包含like的数据
BooleanQuery query =new BooleanQuery();
query.add(new TermQuery(new Term("name","zhangsan")), Occur.MUST);
query.add(new TermQuery(new Term("content","like")), Occur.MUST);
输出结果:

其他属性:
Occur.Must:此条件必须符合。
Occur.MUST_NOT:此条件必须不符合(name必须不能是zhangsan)。
Occur.SHOULD:此条件可以不符合。
(6) 短语查询(PhraseQuery)
//查询content中包含i和book短语的,两个短语之间间隔2位
PhraseQuery query =new PhraseQuery();
query.setSlop(2);//设置单词间隔数
query.add(new Term("content","i"));
query.add(new Term("content","book"));
输出结果:

备注:短语查询,对英文非常有效,汉语没多大作用。
(7) 模糊查询(FuzzyQuery)
//FuzzyQuery(Term,匹配程度,匹配距离);值越小,匹配上的比率越大
FuzzyQuery query =new FuzzyQuery(new Term("name","jahn"),0.4f,0);
System.out.println("匹配距离:"+query.getPrefixLength());
System.out.println("最小匹配程度:"+query.getMinSimilarity());
输出结果:

备注:模糊查询的效率较低,一般使用较少。
3.3QueryParser
(1) 创建QueryParser
//创建QueryPrase对象.设置默认搜索域为content
QueryParser parser = new QueryParser(Version.LUCENE_36,"content",
new StandardAnalyzer(Version.LUCENE_36));
//改变默认操作符(空格)的作用。
parser.setDefaultOperator(Operator.AND); //设置空格为and
//开启第一个字符为通配符的匹配。默认为关闭,因为效率不高。
parser.setAllowLeadingWildcard(true);
(2) 各种匹配方式
//搜索content中包含like的
Query query = parser.parse("fly");
//搜索有football或者有food的,空格默认为or
query = parser.parse("football food");
//改变默认搜索域。name为mike的
query = parser.parse("name:mike");
//名字为j开头的.邮箱@后为4位字符的*为任意数,?代表一个字符。
query = parser.parse("name:j*");
query = parser.parse("email:*@????.com");
//name中不能有mike,内容中必须有football
query = parser.parse("-name:mike + football");
//匹配id为1-3的。TO必须大写
query = parser.parse("id:[1 TO 3]");
//查询id为1和3的,类似parser.parse("id:1 id:3");。可能是版本问题,在3.5中为闭区间,查询结果为id是2的。
query = parser.parse("id:(1 to 3)");
//查询email首字母为a-c的,但输出结果不包含c。
query = parser.parse("email:[a TO c]");
//短语匹配。双引号中的短语必须完全匹配
query = parser.parse("\"i like football\"");
//匹配i和football之间有1个以内单词的。~n即<n个单词
query = parser.parse("\"i football\"~1");
//模糊查询(mike)。只能有一个字符的差异。
query = parser.parse("name:mie~");
备注:这种QueryParser不能匹配数字,需要自己扩展。
3.4 分页搜索
(1) 普通分页
//查询content中包含"java"的数据,并按每页10条进行分页。展示第3页。
searchPage("java", 3, 10); //(查询的内容,页码,每页数量)
public void searchPage(String query,int pageIndex,int pageSize){
Directory dir = FileIndexUtils.getDirectory();
IndexSearcher searcher = getIndexSearcher(dir);
QueryParser parser = new QueryParser(Version.LUCENE_36,
"content",new StandardAnalyzer(Version.LUCENE_36));
Query q;
try {
q = parser.parse(query);
TopDocs tds = searcher.search(q, 500);
ScoreDoc[] sds = tds.scoreDocs;
int start = (pageIndex-1)*pageSize; //计算开始位置
int end = pageIndex*pageSize; //计算结束位置
for(int i=start;i<end;i++){ //遍历这个区间
Document doc = searcher.doc(sds[i].doc);
System.out.println(sds[i].doc+":"+doc.get("path")
+"-->"+doc.get("filename"));
}
searcher.close();//关闭searcher
} catch (org.apache.lucene.queryParser.ParseException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
备注:这种分页是每次取出所有的数据,在所有的数据中进行再查询,内存开销很大。
(2) searchAfter分页
//查询content中包含"java"的数据,并按每页10条进行分页。展示第1页。
searchPageByAfter("java", 1, 10); //(查询的内容,页码,每页数量)
public void searchPageByAfter(String query,int pageIndex,
int pageSize){
Directory dir = FileIndexUtils.getDirectory();
IndexSearcher searcher = getIndexSearcher(dir);
QueryParser parser = new QueryParser(Version.LUCENE_36,
"content",new StandardAnalyzer(Version.LUCENE_36));
Query q;
try {
q = parser.parse(query);
//先获取上一页的最后一个元素
ScoreDoc lastSd = getLastScoreDoc(pageIndex, pageSize,
q, searcher);
//通过最后一个元素搜索下一页
TopDocs tds = searcher.searchAfter(lastSd,q,20);
for(ScoreDoc sd : tds.scoreDocs){
Document doc = searcher.doc(sd.doc);
System.out.println(sd.doc+":"+doc.get("path")+"-->"+
doc.get("filename"));
}
searcher.close();
} catch (org.apache.lucene.queryParser.ParseException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
//获取上一页的最后一个ScoreDoc
private ScoreDoc getLastScoreDoc(int pageIndex,int pageSize,
Query query,IndexSearcher searcher) throws IOException{
if(pageIndex==1)return null; //如果是第一页,返回null
int num = (pageIndex-1)*pageSize;
TopDocs tds = searcher.search(query, num);
return tds.scoreDocs[num-1];
}
备注: searchAfter分页查询,是3.5版本以后出现的方法,极大的优化了内存占用。
第四章 分词基础
不同的分词器具备不同的功能,可以根据自己的业务需求进行选择。目前,中文分词是最为复杂的,使用最多的中文分词器有:paoding、mmseg4j 和IK。其中paoding已经停止更新了。mmseg4j是使 用 Chih-Hao Tsai 的 MMSeg算法 实现的中文分词器,自带搜狗词库。IK采用了特有的“正向迭代最细粒度切分算法“,多子处理器分析模式,支持api级的用户词库加载,和配置级的词库文件指定。这里涉及的中文分词器皆使用mmseg4j-1.8版本分词器作为示例。
本章节先对各种分词器进行分词效果演示,然后再介绍分词原理。
4.1 分词效果
(1) 准备分词输出类
public static void displayToken(String str,Analyzer a){
try {
//由分词器a进行分词后,会生产一个存储了大量的属性的流TokenStream
TokenStream stream = a.tokenStream("content",
new StringReader(str));
//CharTermAttribute保存的是相应的词汇
//创建一个属性,这个属性会添加在流中,随着这个TokenStream增加
CharTermAttribute cta =
stream.addAttribute(CharTermAttribute.class);
while(stream.incrementToken()){
System.out.print("["+cta+"]");
}
System.out.println();
} catch (IOException e) {
e.printStackTrace();
}
}
备注:这个类会根据传入的字符串和分词器,输出相应的分词信息。
(2) 创建分词器
public void test01(){
//标准分词器
Analyzer a1 = new StandardAnalyzer(Version.LUCENE_36);
//停用词分词器
Analyzer a2 = new StopAnalyzer(Version.LUCENE_36);
//简单分词器
Analyzer a3 = new SimpleAnalyzer(Version.LUCENE_36);、
//空格分词
Analyzer a4 = new WhitespaceAnalyzer(Version.LUCENE_36);
String txt = "This is my house,I am come from sandong zoucheng,My
email is yiwangxianshi@gmail.com,My QQ is 513361564";
AnalyzerUtils.displayToken(txt, a1);
AnalyzerUtils.displayToken(txt, a2);
AnalyzerUtils.displayToken(txt, a3);
AnalyzerUtils.displayToken(txt, a4);
}
备注:这个测试类创建了各种的分词器,将对txt这段英文进行分词。
(3) 英文分词效果
执行test01()方法,输出结果如下:
a1://标准分词器StandardAnalyzer
[my][house][i][am][come][from][sandong][zoucheng][my][email][yiwangxianshi][gmail.com][my][qq][513361564]
a2://停用词分词器StopAnalyzer
[my][house][i][am][come][from][sandong][zoucheng][my][email][yiwangxianshi][gmail][com][my][qq]
a3://简单分词器SimpleAnalyzer
[this][is][my][house][i][am][come][from][sandong][zoucheng][my][email][is][yiwangxianshi][gmail][com][my][qq][is]
a4://空格分词器WhitespaceAnalyzer
[This][is][my][house,I][am][come][from][sandong][zoucheng,My][email][is][yiwangxianshi@gmail.com,My][QQ][is][513361564]
由以上输出结果可以看出,标准分词器去除了this、is这样的单词,以及@和,符号。停用词分词器不仅去除了this、is这样的单词,还去除了数字。简单分词器只是去除了@和,符号和数字。空格分词器从字面理解就好,它什么都不处理,只是按照文本的空格分的词。除了空格分词器,其它的几种分词器全部都把单词转成了小写。
(4) 中文分词效果
在test01()方法中,我们新增一个中文分词器。
//中文分词
Analyzer a5 = new MMSegAnalyzer(
new File("G:\\lucene\\mmseg4j-1.8\\data"));
//将文本txt的值改为汉字
String txt = "我来自山东省邹城市";
//添加分词查看
AnalyzerUtils.displayToken(txt, a5);
执行,输出结果如下:
a1://标准分词器StandardAnalyzer
[我][来][自][山][东][省][邹][城][市]
a2://停用词分词器StopAnalyzer
[我来自山东省邹城市]
a3://简单分词器SimpleAnalyzer
[我来自山东省邹城市]
a4://空格分词器WhitespaceAnalyzer
[我来自山东省邹城市]
a5://中文分词器MMSegAnalyzer
[我][来自][山东][省][邹][城市]
由以上输出结果可见,标准分词器将每个汉字都分成一个词,停用词分词器、简单分词器和空格分词器没有做任何处理。只有中文分词器做了一些处理,识别出了“来自”、“山东”和“城市”这几个词。
当然,这是远远不够的,如果你认为在这里把“邹城”分成一个词更为合适,可以通过自定义词库实现。
打开mmseg4j-1.8/data文件夹,找到words-my.dic文件,使用记事本打开,在里面添加“邹城”,然后保存退出,如下图:

再次执行程序,a5的分词发生了变化:
a5://中文分词器MMSegAnalyzer
[我][来自][山东][省][邹城][市]
备注:中文分词就先带过了,我也不懂。一些分词器在处理英文分词的时候,效率和准确率都是很高的,但在中文分词上完全发挥不了作用。所以,很多的企业都会在现有中文分词器的基础上扩展词库,打造适合自己的分词器。
4.2分词原理
(1) TokenStream
分词器(Analyzer)做好处理之后得到的一个流(即TokenStream),这个流中存储了分词的各种信息,可以通过TokenStream有效的获取到分词单元信息。
生成的流程:
在这个流中所需要存储的数据:
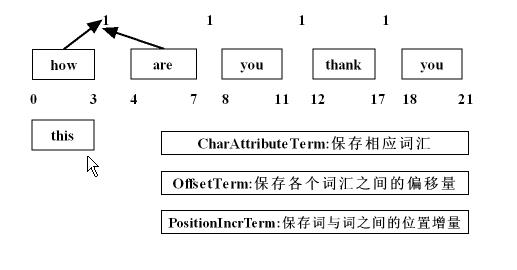
备注:这张图需要介绍下。第一行的“1”,代表位置增量。所谓的位置增量就是分词结果每个分词之间的距离,比如“how”和“are”之间的位置增量是1,如果“are”在分词的时候被去除掉的时候,“how”和“you”之间的位置增量则为2。第二行的数字是偏移量,这个属性在4.3分词属性中再说。这些属性保证了索引信息的还原和同义词定义。
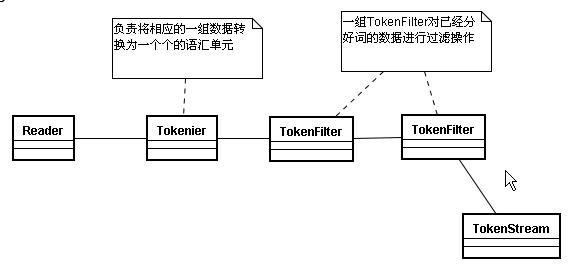
(2) Tokenizer
将一组数据划分为不同的语汇单元。主要负责接收字符流Reader,将Reader进行分词操作。有如下一些实现类:

LowerCaseTokenizer:把读进来的数据全部转换成小写。
LetterTokenizer:把数据按标点符号拆分。
WhitespaceTokenizer:空格分词流,按空格拆分。
KeywordTokenier:不分词,传进来什么样就是什么样。
StandardTokenizer:标准分词,有一些智能的分词功能,比如识别邮箱。
CharTokenizer:字符控制。
备注:注意这张图的箭头,顺序是自下往上的。完成这张图的操作后,数据会被交给TokenFilter。
(3) TokenFilter
将分词的语汇单元,进行各种各样过滤:
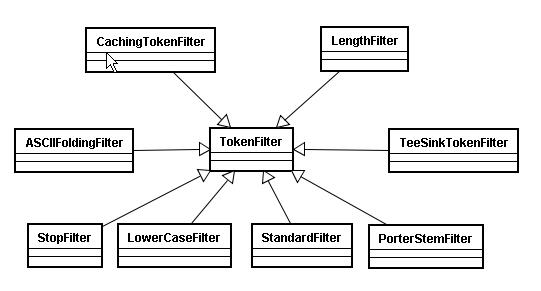
StopFilter:对一些词进行停用。比如“is”,“this”等。
LowerCaseFilter:把词的大写转为小写。
StandardFilter:对标准输出流进行控制。
PorterStemFilter:单词还原。比如“coming”还原成“come”。
TeeSinkTokenFilter:可以使得已经分好词的Token全部或者部分的被保存下来,用于生成另一个TokenStream可以保存在其他的域中。
LengthFilter:当前字符串的长度在指定范围内的时候则返回true。
备注:图片最下面一排是最常用的。
4.3分词属性
(1) 分词属性查看
public static void displayAllTokenInfo(String str,Analyzer a){
TokenStream stream = a.tokenStream("content",
new StringReader(str));
//位置增量属性(存储语汇单元之间的距离)
PositionIncrementAttribute pia =
stream.addAttribute(PositionIncrementAttribute.class);
//每个语汇单元的位置偏移量
OffsetAttribute oa =
stream.addAttribute(OffsetAttribute.class);
//分词单元信息
CharTermAttribute cta =
stream.addAttribute(CharTermAttribute.class);
//使用分词器的类型
TypeAttribute ta = stream.addAttribute(TypeAttribute.class);
try {
for(;stream.incrementToken();){
System.out.print(pia.getPositionIncrement()+":");
System.out.print(cta+
"["+oa.startOffset()+"-"+oa.endOffset()+"]");
System.out.print("--->"+ta.type()+"\n");
}
} catch (IOException e) {
e.printStackTrace();
}
}备注:这个类依次输出了分词位置增量、分词单元信息、偏移量和分词类型。
(2) 分词属性对比
创建一个测试用例,去调用上面的分词属性查看方法
public void test03(){
//标准分词器
Analyzer a1 = new StandardAnalyzer(Version.LUCENE_36);
//停用词分词器
Analyzer a2 = new StopAnalyzer(Version.LUCENE_36);
//简单分词器
Analyzer a3 = new SimpleAnalyzer(Version.LUCENE_36);
//空格分词
Analyzer a4 = new WhitespaceAnalyzer(Version.LUCENE_36);
String txt = "how are you thank you";
AnalyzerUtils.displayAllTokenInfo(txt, a1);
System.out.println("------------------------");
AnalyzerUtils.displayAllTokenInfo(txt, a2);
System.out.println("------------------------");
AnalyzerUtils.displayAllTokenInfo(txt, a3);
System.out.println("------------------------");
AnalyzerUtils.displayAllTokenInfo(txt, a4);
}
执行test03(),输出结果如下:

备注:位置增量:分词单元信息[位置偏移量]—->分词器类型。
4.4自定义分词器
(1) 自定义Stop分词器
这里我们自定义一个MyStopAnalyzer类,在这个过程中,可以选择完全自定义停用词,也可以选择在原有停用词库上添加新的停用词。示例代码如下:
public class MyStopAnalyzer extends Analyzer {
private Set stops;
public MyStopAnalyzer(String[] sws){
System.out.println("查看原来的停用词:"
+StopAnalyzer.ENGLISH_STOP_WORDS_SET);
//true:是否忽略大小写。会自动将字符串数组转换为set
stops = StopFilter.makeStopSet(Version.LUCENE_36, sws, true);
//将原有的停用词,加入到现在的停用词中
stops.addAll(StopAnalyzer.ENGLISH_STOP_WORDS_SET);
}
public MyStopAnalyzer(){
//获取原有的停用词
stops = StopAnalyzer.ENGLISH_STOP_WORDS_SET;
}
public TokenStream tokenStream(String arg0, Reader reader) {
//为这个分词器设定过滤链和Tokenizer
return new StopFilter(Version.LUCENE_36,
new LowerCaseFilter(Version.LUCENE_36,
new LetterTokenizer(Version.LUCENE_36, reader)),stops);
}
}
备注:所有的分词器均继承Analyzer类。原有的停用词有:[but,be, with, such, then, for, no, will, not, are, and, their, if, this, on, into,a, or, there, in, that, they, was, is, it, an, the, as, at, these, by, to, of]。
(2) 实现简单同义词索引
这里将通过自定义分词器的方式,实现同义词的自定义,主要功能将在自定义的过滤器中实现。最终实现的效果是,比如搜索“天朝”或“大陆”,会自动关联“中国”这个词。
a) 创建自定义同义词
public interface SameWordContext {
public String[] getSameWords(String name);
}
//创建同义词
public class SimpleSameWordContext implements SameWordContext {
Map<String,String[]> maps = new HashMap<String, String[]>();
public SimpleSameWordContext(){
maps.put("中国", new String[]{"天朝","大陆"});
maps.put("我", new String[]{"咱","俺"});
}
public String[] getSameWords(String name) {
return maps.get(name);
}
}
b) 创建自定义分词器
//所有的分词器,均需继承Analyzer
public class MySameAnalyzer extends Analyzer {
private SameWordContext sameWordContext; //在a)中创建的同义词接口
//在构造方法中为sameWordContext赋值
public MySameAnalyzer(SameWordContext swc){
this.sameWordContext = swc;
}
@Override
public TokenStream tokenStream(String arg0, Reader reader) {
//获取MMSeg分词器的词库
Dictionary dic =
Dictionary.getInstance("G:\\lucene\\mmseg4j-1.8\\data");
//返回自定义的流
return new MySameTokenFilter(new MMSegTokenizer(
new MaxWordSeg(dic), reader),sameWordContext);
}
}
备注:这里所使用的自定义过滤器将在下面创建,所有实现同义词添加的操作,也是在在定义操作流中完成的。
c) 创建自定义过滤器
/*
* 自定义分词器:添加同义词
* 原理:cta是一个map,经过MMseg分词后,每个原始的词为key,在其value中添加词
即为同义词
*/
public class MySameTokenFilter extends TokenFilter {
private CharTermAttribute cta = null; //存储分词数据
private PositionIncrementAttribute pia = null; //存储位置数据
private AttributeSource.State current; //状态存储
private Stack<String> sames = null; //栈
private SameWordContext sameWordContext; //存储同义词的接口
protected MySameTokenFilter(TokenStream input,SameWordContext sameWordContext) {
super(input);
cta = this.addAttribute(CharTermAttribute.class);
pia = this.addAttribute(PositionIncrementAttribute.class);
sames = new Stack<String>();
this.sameWordContext = sameWordContext;
}
@Override
public boolean incrementToken() throws IOException {
while(sames.size()>0){
//将元素出栈,并且获取这个同义词
String str = sames.pop();
restoreState(current); //还原状态
cta.setEmpty(); //清空
cta.append(str); //添加同义词
//设置位置为0
pia.setPositionIncrement(0);
return true;
}
//input继承与父类,如果没有元素,返回false
if(!this.input.incrementToken())return false;
if(addSames(cta.toString())){
//如果有同义词,先保存当前状态
current = captureState();
}
return true;
}
//获取同义词
private boolean addSames(String name){
String sws[] = sameWordContext.getSameWords(name);
if(sws!=null){
for(String str:sws){
sames.push(str);
}
return true;
}
return false;
}
}
备注:这样就实现了同义词的添加。这是一个原理的流程演示,实际项目中还需要自己扩展。
d) 测试同义词索引
public void test05(){
try {
//创建自定义分词器
Analyzer a1 = new MySameAnalyzer(
new SimpleSameWordContext());
String txt = "我来自中国山东省邹城市";
//将索引保存到内存中
Directory dir = new RAMDirectory();
IndexWriter writer = new IndexWriter(dir,
new IndexWriterConfig(Version.LUCENE_36,a1));
Document doc = new Document();
//将字符串txt保存到content域中
doc.add(new Field("content",
txt,Field.Store.YES,Field.Index.ANALYZED));
//将文本添加到索引
writer.addDocument(doc);
//索引建立完成,关闭writer
writer.close();
//创建IndexSearcher,准备搜索
IndexSearcher search =
new IndexSearcher(IndexReader.open(dir));
TopDocs tds = search.search(new TermQuery(
new Term("content","天朝")), 10); //查询“天朝”这个词
doc = new Document();
for(ScoreDoc s:tds.scoreDocs){ //遍历结果集,输出查询结果
doc = search.doc(s.doc);
System.out.println("--:"+doc.get("content"));
}
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (LockObtainFailedException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
执行test05(),输出结果如下:

由输出结果可见,我们搜索的“天朝”这个词,在原文中并不存在,但通过同义词的匹配依然被搜索出来了。我们可以借用第四章第三节的分词属性查看的代码,看下详细的分词信息,输出结果的for语句后添加如下代码:
AnalyzerUtils.displayAllTokenInfo(txt, a1);
执行test05(),输出结果如下:

第五章 高级搜索
通过前四章的内容,我们已经了解lucene建立索引,分词和搜索的工作流程,可以实现简单的lucene操作了。但在实际项目中,还会有更多的需求,比如:排序、搜索过滤、自定义评分等。这章将会简单的介绍下这些东西。
本章节中的索引,是找了一堆乱七八糟的文件,复制了一下,然后冠以一堆乱七八糟的后缀建立而成,为了使本章内容看起来不会特别抽象,所以先放出索引建立类,参考代码如下(看下域名就好):
//建立索引
public static void index(boolean hasNew){
IndexWriter writer = null;
try {
writer = new IndexWriter(directory,new IndexWriterConfig(Version.LUCENE_36, new StandardAnalyzer(Version.LUCENE_36)));
if(hasNew){
writer.deleteAll();
}
File file = new File("D:/Test/example");//路径根据自己的设定
Document doc = null;
Random ran = new Random();
int index = 0;
for(File f:file.listFiles()){
int score = ran.nextInt(600);
doc = new Document();
doc.add(new Field("id",String.valueOf(index++),Field.Store.YES,Field.Index.NOT_ANALYZED_NO_NORMS));
doc.add(new Field("content",new FileReader(f))); //内容
doc.add(new Field("filename",f.getName(),Field.Store.YES,Field.Index.NOT_ANALYZED)); //文件名
doc.add(new Field("path",f.getAbsolutePath(),Field.Store.YES,Field.Index.NOT_ANALYZED)); //路径
doc.add(new NumericField("date",Field.Store.YES,true).setLongValue(f.lastModified()));//文件最后修改时间
//f.length()/1024:将字节转换成kb单位
doc.add(new NumericField("size",Field.Store.YES,true).setIntValue((int)f.length()));//文件大小
//做自定义评分排名测试,无实际意义
doc.add(new NumericField("score",Field.Store.YES,true).setIntValue(score));
writer.addDocument(doc);
}
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (LockObtainFailedException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally{
if(writer != null)
try {
writer.close();
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
5.1 搜索排序
(1) 建立搜索类
public void searcherBySort(String querystr,Sort sort){
IndexSearcher search = getSearcher();
QueryParser parser = new QueryParser(Version.LUCENE_36,"content",new StandardAnalyzer(Version.LUCENE_36));
try {
Query query = parser.parse(querystr);
TopDocs tds;
if(sort!=null){
tds = search.search(query, 100,sort);
}else{
tds = search.search(query, 100);
}
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");
for(ScoreDoc sd : tds.scoreDocs){
Document d = search.doc(sd.doc);
System.out.println(sd.doc+":("+sd.score+")"+d.get("filename") +"【"+d.get("path")+"】---"+d.get("score")+"--->"+d.get("size")+"---"+sdf.format(new Date(Long.valueOf(d.get("date")))));
}
search.close();
} catch (ParseException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
public void searcherBySort(String querystr,Sort sort){
IndexSearcher search = getSearcher();
QueryParser parser = new QueryParser(Version.LUCENE_36,"content",new StandardAnalyzer(Version.LUCENE_36));
try {
Query query = parser.parse(querystr);
TopDocs tds;
if(sort!=null){
tds = search.search(query, 100,sort);
}else{
tds = search.search(query, 100);
}
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");
for(ScoreDoc sd : tds.scoreDocs){
Document d = search.doc(sd.doc);
System.out.println(sd.doc+":("+sd.score+")"+d.get("filename") +"【"+d.get("path")+"】---"+d.get("score")+"--->"+d.get("size")+"---"+sdf.format(new Date(Long.valueOf(d.get("date")))));
}
search.close();
} catch (ParseException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
备注:传入查询的字段,和排序规则,输出查询结果。后面排序演示均调用这个方法。
(2) 默认排序
st.searcherBySort("java", null);
输出结果如下:

备注:结果较多,截取了一部分,凑合看吧。括号()内的数字是评分,可见默认输出的结果也是经过排序的,即默认就是按评分排序。但我们依然还要演示下按评分排序,因为单独演示按评分排序存在一点小问题。
(3) 根据评分排序
st.searcherBySort("java", Sort.RELEVANCE);
输出结果如下:

备注:由输出结果可见,按评分排序和默认排序的结果是一样的,但经过Sort排序之后,括号内的评分看不到了,如果不拿默认排序做比对,这个结果很难看出效果。⊙﹏⊙
(4) 根据索引号排序
st.searcherBySort("java", Sort.INDEXORDER);
输出结果如下:

备注:第一个数值就是索引号。这个Sort.INDEXORDER是按索引的id排序,相当于Oracle中的rownum。
(5) 根据文件大小排序
st.searcherBySort("java",new Sort(new SortField("size", SortField.INT)));
输出结果如下:

备注:由于使用的文档大多是复制品,只是后缀不同,所以文件大小大多一致,为了能看出效果,多截取了一点。在日期前的数值是文件的大小。这种自定义的排序,需要声明域的类型,“size”的类型是INT。
(6) 根据日期排序
st.searcherBySort("java",new Sort(new SortField("date", SortField.LONG)));
输出结果如下:

备注:最后的就是日期,这个很明显。和文件大小排序唯一的区别就是,“data”域是LONG型的。
(7) 根据文件名排序(倒序)
st.searcherBySort("java",new Sort(new SortField("filename", SortField.STRING,true)));
输出结果如下:

备注:括号后的即是文件名。这个是以倒序排列的,倒序很简单,只是在域类型后面加了一个参数“true”,这个参数代表是否翻转。
(8) 多条件排序
//先以文件大小排序,再以评分排序
st.searcherBySort("java",new Sort(new SortField("size",SortField.INT),new SortField("score", SortField.INT)));
输出结果如下:

备注:倒数第三个即评分域的值,需要注意的是,这个评分不是lucene给的相关性评分,而是我们自定义的,在创建索引时随机添加的,只是用于这个演示,无任何实际意义。
可以发现,结果是按照文件大小以升序排列的,相同大小的文件,又按照评分进行了升序排列。如果需要更多的条件,可以直接在代码后面继续添加new SortField()。
5.2 搜索过滤
(1) 建立搜索类
public void searcherByFilter(String querystr,Filter filter){
IndexSearcher search = getSearcher();
QueryParser parser = new QueryParser(Version.LUCENE_36,"content",new StandardAnalyzer(Version.LUCENE_36));
try {
Query query = parser.parse(querystr);
TopDocs tds;
if(filter!=null){
tds = search.search(query,filter,100);
}else{
tds = search.search(query, 100);
}
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");
for(ScoreDoc sd : tds.scoreDocs){
Document d = search.doc(sd.doc);
System.out.println(sd.doc+":("+sd.score+")"+d.get("filename")+"【"+d.get("path")+"】---"+d.get("score")+"--->"+d.get("size")+"---"+sdf.format(new Date(Long.valueOf(d.get("date")))));
}
search.close();
} catch (ParseException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
备注:这个类和搜索排序的类几乎是一样的,只是将传入的值Sort换成了Filter。
(2)文本域范围过滤(TermRangeFilter)
//查询“filename”中在“LICENSE.she”和“LICENESE.txt”之间的
Filter tr =new TermRangeFilter("filename","LICENSE.she","LICENSE.txt",true,true);
输出结果如下:

备注:后面的两个参数代表是否包含开始值和是否包含结束值。
(3)数字域范围过滤(NumericRangeFilter)
Filter tr = NumericRangeFilter.newIntRange("size", 1, 10000, true,true);
输出结果如下:

备注:倒数第二个值为文件大小。可以对比搜索排序中的输出结果。
(4)查询结果过滤(QueryWrapperFilter)
//查询文件名后缀为“.hhh”的
Filter tr =new QueryWrapperFilter(new WildcardQuery(new Term("filename","*.hhh")));
输出结果如下:

备注:由输出可见,在搜索出符合条件的结果后,并默认的按评分排序了。
5.3自定义评分
自定义评分的本质,相当于一个自定义Query。默认情况实现的评分是通过原有的文档评分乘以传入进来的评分域所获取的评分来确定最终评分的。
自定义评分一般分为两步:首先创建一个自定义Query类,继承CustomScoreQuery,覆盖其中的getCustomScoreProvider(IndexReader reader)方法,在这个方法中调用一个自定义评分类。然后创建这个自定义评分类,继承于CustomScoreProvider。覆盖其中的customScore() 方法,在customScore() 方法中根据不同的需求,自己进行评分的设定。最后,调用这个Query类,就可以实现自定义评分了。
在这里,我们实现一个需求来演示自定义评分:后缀为“.txt”或“.ini”的文件为其加分,使其排名靠前。
(1)创建一个类继承CustomScoreQuery
private class FilenameScoreQuery extends CustomScoreQuery{
private static final long serialVersionUID = 1L;
public FilenameScoreQuery(Query subQuery) {
super(subQuery);
}
//覆盖getCustomScoreProvider()方法
@Override
protected CustomScoreProvider getCustomScoreProvider
(IndexReader reader) throws IOException {
//默认情况下:原有的评分*评分域的评分=最终评分
//我们将在下面的方法中改变这个规则
return new FilenameScoreProvider(reader);
}
}
备注:FilenameScoreQuery和FilenameScoreProvider这两个类的名称是自定义的。后者将在第二步创建。
(2)创建一个类继承CustomScoreProvider
private class FilenameScoreProvider extends CustomScoreProvider{
String[] filenames = null;
public FilenameScoreProvider(IndexReader reader) {
super(reader);
try {
filenames =
FieldCache.DEFAULT.getStrings(reader, "filename");
} catch (IOException e) {
e.printStackTrace();
}
}
//覆盖customScore ()方法
@Override
public float customScore(int doc, float subQueryScore,
float valSrcScore) throws IOException {
//根据doc获取相应的field的值
//subQueryScore:表示默认文档的打分
//valSrcScore:表示评分域的打分
String filename = filenames[doc];
//如果后缀是.txt或.ini为其加分
if(filename.endsWith(".txt") || filename.endsWith(".ini")){
return subQueryScore*15f;
}
return subQueryScore/1.5f;
}
}
备注:在reader没有关闭之前,所有的数据会存储到一个域缓存中。可以通过域缓存换取许多有用的信息。filenames =FieldCache.DEFAULT.getStrings(reader, "filename");可以获取所有的filename域的信息。
(3)自定义评分效果测试
public void searchByFileScoreQuery(){
try {
IndexSearcher searcher = new IndexSearcher(
IndexReader.open(FileIndexUtils.getDirectory()));
Query q = new TermQuery(new Term("content","java"));
FilenameScoreQuery query = new FilenameScoreQuery(q);
TopDocs tds = searcher.search(query, 100);
SimpleDateFormat sdf =
new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");
for(ScoreDoc sd : tds.scoreDocs){
Document d = searcher.doc(sd.doc);
System.out.println(sd.doc+":("+sd.score+")"+
d.get("filename")+"【"+d.get("path")+"】---"+
d.get("score")+"--->"+d.get("size")+"---"+
sdf.format(new Date(Long.valueOf(d.get("date")))));
}
searcher.close();
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
输出结果如下:

备注:由结果可以看出,后缀为“.txt”和“.ini”的评分明显高于其它评分,排名也比较靠前。代码中下划线标出的即是我们创建的自定义评分Query。
5.4 自定义QueryParser
在实际应用中,对于某些QueryParser(FuzzyQuery,WildcardQuery)在查询时会使得性能降低,所以考虑将这些查询禁用。在具体的查询时,很有可能有这样一种需求:需要获取的是一个数字的范围查询,而QueryParser本身是不支持的(可以自己试下,不会报错,但返回结果集是空的),所以必须扩展原有的QueryParser才能进行查询。
实现思路:覆盖QueryParser类,并且重载相应方法。
(1)限制低性能的QueryParser
public class CustomParser extends QueryParser {
//构造方法(LUCENE版本,默认搜索域,分词器)
public CustomParser(Version matchVersion, String f,Analyzer a) {
super(matchVersion, f, a);
}
@Override //重载通配符查询getWildcardQuery
protected org.apache.lucene.search.Query getWildcardQuery(String field,String termStr) throws ParseException {
throw new ParseException("由于性能原因,通配符查询已被禁用,请输入更精确的信息进行查询");
}
@Override // 重载模糊查询getFuzzyQuery
protected org.apache.lucene.search.Query getFuzzyQuery(String field, String termStr, float minSimilarity) throws ParseException {
throw new ParseException("由于性能原因,模糊查询已被禁用,请输入更精确的信息进行查询");
}
}
备注:这个自定义的QueryParser重载了模糊查询和通配符查询,当调用这两个方法时会抛出异常
(2)扩展基于数字和日期的查询
@Override
protected org.apache.lucene.search.Query getRangeQuery(String field,String arg1, String arg2, boolean arg3) throws ParseException {
if(field.equals("size")){ //域名为“size”
return NumericRangeQuery.newIntRange(field, Integer.parseInt(arg1), Integer.parseInt(arg2), arg3, arg3);
}else if(field.equals("date")){ //域名为“date”
String dateType = "yyyy-MM-dd";
Pattern pattern = Pattern.compile("\\d{4}-\\d{2}-\\d{2}");
if(pattern.matcher(arg1).matches() && pattern.matcher(arg2).matches()){
SimpleDateFormat sdf = new SimpleDateFormat(dateType);
try {
long start = sdf.parse(arg1).getTime();
long end = sdf.parse(arg2).getTime();
return NumericRangeQuery.newLongRange(field, start, end, arg3, arg3);
} catch (java.text.ParseException e) {
e.printStackTrace();
}
} else {
throw new ParseException("要检索的日期格式不正确,请使用"+dateType+"这种格式");
}
}
return super.newRangeQuery(field, arg1, arg2, arg3);
}
备注:在实际中,遇到需要对数字和日期进行范围查询的时候,需要对指定域做处理。这个示例是对“size”和“date”两个数字域做了特殊处理。
Ps:把这段代码添加到CustomParser类中。
(3)自定义QueryParser效果测试
public void searcherByCustomQuery(String value){
IndexSearcher search;
try {//自己封装一个getDirectory()方法就好
search = new IndexSearcher(
IndexReader.open(FileIndexUtils.getDirectory()));
CustomParser parser = new CustomParser(Version.LUCENE_36,"content",new StandardAnalyzer(Version.LUCENE_36));
Query queryStr = parser.parse(value);
System.out.println(queryStr);
TopDocs tds = search.search(queryStr, 50);
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");
for(ScoreDoc sd : tds.scoreDocs){
Document d = search.doc(sd.doc);
System.out.println(sd.doc+":("+sd.score+")"+d.get("filename")+"【"+d.get("path")+"】---"+d.get("score")+"--->"+d.get("size")+"---"+sdf.format(new Date(Long.valueOf(d.get("date")))));
}
search.close();//关闭search
} catch (CorruptIndexException e1) {
e1.printStackTrace();
} catch (IOException e1) {
e1.printStackTrace();
} catch (ParseException e) {
//.err使用红色打印。捕获异常直接打印信息。
System.err.println(e.getMessage());
}
}
这个输出方法与之前的一些没很大区别,只是把查询的Query换成了我们自定义的。我们将调用这个方法来测试自定义QueryParser的效果。
a) 通配符查询测试
searcherByCustomQuery("ja?va");
输出结果如下:

备注:这句话,正是我们在覆盖通配符查询时所抛出的异常信息。可见禁用成功了。
b) 模糊查询测试
searcherByCustomQuery("java~");
输出结果如下:

备注:在测试代码时,偶尔可能会使用"java*"这种格式进行测试,系统会把它默认为前缀匹配。前缀匹配方法在我们的示例中并没有被重载,所以依然是可用的。项目中是否禁用,就参照个人需求吧。
c) 数字查询测试
searcherByCustomQuery("size:[1 TO 1000]");
输出结果如下:

备注:倒数第二个值是“size”值。
d) 日期查询测试
searcherByCustomQuery("date:[2012-10-01 TO 2013-12-12]");
输出结果如下:

备注:从第一行输出结果来看,我们的查询条件已经将String条件(date:[2012-10-01 TO 2013-12-12])转换成了Long型(date:[1349020800000 TO 1386777600000])。
我们更换下条件,将yyyy-MM-dd的日期格式更换为yyyy-MM的格式,测试下日期格式验证是否有效:
searcherByCustomQuery("date:[2012-10 TO 2013-12-12]");
输出结果如下:

备注:很显然,2012-10是不被认可的。
5.5 自定义过滤器
自定义过滤器的简单步骤就是:定义一个Filter类继承Filter;覆盖getDocIdSet方法,设置DocIdSet。为了更贴近实际应用,这里我们将使用接口编程的方式进行演示。
相对于普通的需求来说,前面的搜索过滤基本就可以满足了。但对于复杂的和大型的索引程序,合理的使用自定义过滤器可以大幅度的提升效率。
比如淘宝或京东这样的大型购物网站,经常会推出一些活动,而这些活动的特点就是时间周期短,活动过后,这些活动商品就不应该被搜索到。还有更直观的例子就是,当卖家把某个商品下架,这个已经下架的商品信息也应该不被搜索到。这时,使用deleteDocuments()方法直接删除索引从功能上是可以实现的,但效率不高。因为对于数据量极大的索引来说,更新是很耗时间的一种操作,会严重的影响用户体验。所以,比较好的解决方案就是,先把活动结束的或已下架的商品信息隐藏,等到用户访问量最少的时间段,再执行删除操作。自定义过滤器就可以很好的实现这一点,它可以使指定的信息快捷的显示或隐藏。
(1)分析需求,创建接口
public interface FilterAccessor {
//设置指定文档
public String[] values();
//获取域
public String getField();
/*
* 设置是否可见
* true:仅指定文档可见
* false:仅指定文档不可见
*/
public boolean set();
}
备注:接口中的三个方法,能提供自定义过滤器所需要的所有内容和属性。我们可以在一个类中实现它们,然后在调用自定义过滤器的时候直接将接口当参数传入。
(2)创建过滤器,继承Filter
public class MyIDFilter extends Filter {
private FilterAccessor accessor; //(1)中的接口
public MyIDFilter(FilterAccessor accessor) {
this.accessor = accessor; //数据通过接口传入
}
@Override //覆盖getDocIdSet()方法
public DocIdSet getDocIdSet(IndexReader reader) throws IOException {
//创建一个bit,默认所有的元素都是0
OpenBitSet obs = new OpenBitSet(reader.maxDoc());
if(accessor.set()){ //true:仅指定文档可见
set(reader,obs);
} else { //false:仅指定文档不可见
clear(reader,obs);
}
return obs;
}
//设置指定文档可见
private void set(IndexReader reader,OpenBitSet obs){
try {
int[] docs = new int[1]; //索引中的文档位置
int[] freqs = new int[1]; //索引中的出现次数
//获取id所在的doc的位置,并且将其设置为非零数字
for(String delId : accessor.values()){
TermDocs tds = reader.termDocs(new Term(accessor.getField(),delId));
//会将查询出来的位置存储在docs中,将出现的频率存储到freqs中
//返回获取询的条数
int count = tds.read(docs, freqs);
if(count==1){
obs.set(docs[0]); //将这个位置的元素展示
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
//设置指定文档不可见
private void clear(IndexReader reader,OpenBitSet obs){
try {
obs.set(0,reader.maxDoc()); //先把元素填满
int[] docs = new int[1]; //索引中的文档位置
int[] freqs = new int[1]; //索引中的出现次数
//获取id所在的doc的位置,并且将其设置为0
for(String delId : accessor.values()){
TermDocs tds = reader.termDocs(new Term(accessor.getField(),delId));
//条数=tds.read(查询出来的位置, 出现的频率);
int count = tds.read(docs, freqs);
if(count==1){
obs.clear(docs[0]); //将这个位置的元素删除
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
(3)实现接口,效果演示
public void searchByCustomFilter(){
try {
IndexSearcher searcher = new IndexSearcher(IndexReader.open(FileIndexUtils.getDirectory()));
Query q = new TermQuery(new Term("content","java"));
TopDocs tds = searcher.search(q,new MyIDFilter(new FilterAccessor() { //使用内部类实现接口
public String[] values() { //设置内容
return new String[]{"10","20","69","130"};
}
public boolean set() { //设置是否显示
return true;
}
public String getField() { //设置域名
return "id";
}
}), 100);
for(ScoreDoc sd : tds.scoreDocs){
Document d = searcher.doc(sd.doc);
System.out.println(sd.doc+":("+sd.score+")"+d.get("filename")+"【"+d.get("path")+"】---"+d.get("score")+"--->"+d.get("size")+"------>"+d.get("id"));
}
searcher.close();
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
输出结果如下:

备注:示例依然是查询count中包含“java”的。这里输出了三个值,但我们在设置值的时候设置了四个(newString[]{"10","20","69","130"};),其中10没有显示。这是因为id为10的文档不符合搜索条件,即不包含“java”。
现在我们改变需求,使指定id的信息不被搜索到。此时,只需要改变实现类的一个属性即可:
publicboolean set() { //设置是否显示
returnfalse; //把原来的true改成false
}
用上面的代码把内部类中的代码替换掉,再次执行。
输出结果如下:

备注:结果很多,我截取了一部分。输出结果里面id为{"10","20","69","130"}的已经被过滤掉了。
同理,我们如果想以其它域作为过滤条件,只需修改下实现类即可。比如:
public String[] values() {
returnnew String[]{"NOTICE.txt","LICENSE.txt"};
}
publicboolean set() { returntrue; }
public StringgetField() { return"filename"; }
输出结果如下:

备注:由上面的例子可见,这种封装方式是非常方便扩展的,这也是在实际开发中需要的。Lucene的简单应用到这就结束了,接下来是些扩展内容。
第六章 LUCENE扩展
6.1 Luke
Luke是一个查看索引文件的工具,使用方便,几乎成了lucene开发者的必备工具。我们可以通过这个工具查看索引、分词等信息,执行搜索操作。当我们认为检索结果不合理的时候,也可以使用Luke工具打开索引,进行验证。
Luke应该使用和Lucene相同的版本,但我没找到3.6版本的Luke,所以暂时使用lukeall-3.5.0 版本,目前没发现任何不兼容的问题。
(1)启动Luke
下载lukeall-3.5.0.jar文件放在一个自己可以找到的目录,然后通过命令提示符打开它(ctrl+r-->cmd-->找到目录-->java –jar lukeall-3.5.0.jar)。如下图:

执行成功,Luke会被打开:

(2)索引概述页面
点击Browse选择索引路径,然后点击OK,就可以进入到该索引的概述页面了。如下图:

界面的上面显示的是索引的路径、文件数、域和最后修改时间等信息。如果索引被重建了,可以点击右侧的Re-open重新打开,相当于刷新。界面下方左侧是域的信息,右侧是分词的信息。选中一个域名,点击Show top terms按钮,可以查看域的分词信息(在按钮下可以设置显示数量),如下图:

(3)查看索引信息
点击第二个标签Documents,可以查看索引的详细信息:

这个界面按钮挺多,但并不常用。上部分是操作区,下半部分则是显示区。左上位置是通过索引id查看索引信息的,可以通过左右箭头执行上一个和下一个操作。右上方的操作区是通过域名查看索引信息的,First Term可以返回第一个索引。选择域名后,点击Next Term可以到下一个。下一个索引文件信息会将相应的域值展示在右上方的文本框中,下半部分的显示区不会发生改变。

剩下的这些按钮则是对索引执行操作的。比如在右上方选择name域,文本框中显示zhangsan的时候,点击Show All Docs,则会跳转到查询页面,找到name为zhangsan的索引信息,相当于执行了一个TermQuery。
备注:在下方的显示区内,并没有count域,这是因为我们在创建索引的时候没有保存它,即count域的属性为Field.Store.NO。
(4)查询索引信息
第三个标签search,则是执行查询操作的。如下图:

在左上方的文本框中输入查询条件,格式与QueryParser相同。然后点击右侧最大的按钮Search,就可以在下方看到查询的结果了。在最下方位置,会在刚查询结束的时候显示一个红色的查询时间,可以用来检验查询条件的效率。

后面还有两个标签,Files是索引文件信息,Plugins中有分词、hadoop等其他的一些工具,有兴趣可以自己看下。
顺便再说下,Luke是一个辅助工具,在各个页面经常可以看到update、setnorm、delete等按钮,这些修改索引的操作还是建议在程序中完成,在这里虽然很便捷,但也容易发生一些无法预知的问题。
备注:提示下,在Luke工具运行的同时,不要关闭dos命令窗口。还有一点值得注意的是,当使用luke打开索引文件的时候,可能会出现索引文件被占用,无法删除的现象。比如新建索引时执行writer.deleteAll()无效(不报错,会创建新的段)。
6.2 Tika
Tika是2008年才产生的一个apache的项目,主要用于打开各种不同的文档。这里,我们将演示Tika的基本用法和原理。
(1)Tika的使用
现在,我们创建一个Tika工具类,效果是:传入一个File,输出File的文件信息,并以字符串的形式返回文件内容。
public String tikaTools(File f) throws IOException, TikaException{
Tika tika = new Tika();
//如不需要Metadata可以不添加,Metadata是文件的属性信息
Metadata metadata = new Metadata();
metadata.set(metadata.AUTHOR, "刺猬");//添加作者
metadata.set(metadata.RESOURCE_NAME_KEY, f.getName()); //文件名
String str = tika.parseToString(new FileInputStream(f), metadata); //获取文件内容
for(String name : metadata.names()){ //遍历,输出文件属性信息
System.out.println(name+":"+metadata.get(name));
}
return str;
}
工具类完成,现在传入一个文件输出下(web项目中的index.jsp):
//.doc.pdf等格式都可以
System.out.println(iu.tikaTools( new File("D:/Test/example2/index.jsp")) );
输出结果如下:

(2)Tika的原理
还是使用老方法,写一个类实现和(1)中Tika相同的功能,看看它在获取文件—>输出文本内容之间都封装了些什么。
public String fileToTxt(File f){
//parser相当于解析器,AutoDetectParser则是实现自动匹配的
//可解析.doc/.pdf等几乎所有格式的文档
Parser parser = new AutoDetectParser();
InputStream is = null;
try {
is = new FileInputStream(f); //输入流
// ContentHandler存储所有解析出来的内容
ContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
metadata.set(metadata.AUTHOR, "刺猬");//作者在这无效,被原名覆盖
metadata.set(metadata.RESOURCE_NAME_KEY, f.getName());
ParseContext context = new ParseContext();
context.set(Parser.class, parser);
parser.parse(is, handler, metadata, context);
for(String name : metadata.names()){
System.out.println(name+":"+metadata.get(name));
}
return handler.toString();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (TikaException e) {
e.printStackTrace();
} finally {
try {
if(is != null)is.close(); //关闭输入流
} catch (IOException e) {
e.printStackTrace();
}
}
return null;
}
工具类完成,现在传入一个文件输出下(.doc文档):
System.out.println(iu.fileToTxt(new File("D:/Test/example2/第一天.doc")));
输出结果如下:

备注:这个例子是说明原理的,一般不用,但是效率比tika.parseToString(f)要高一些。
Tika和Luke一样,也是可以单独运行的。使用java –jar命令执行,可以看到可视化的界面。具体操作自己看下就好,一共两个大类的功能标签,可以提供属性查看和输出效果预览,这里就不介绍了。
6.3高亮显示
大家都经常使用搜索引擎,无论用百度还是谷歌,甚至是一些网站的站内搜索,它们都会将用户搜索的关键词用红色标注出来。这能带来良好的用户体验,现在我们也要实现这个功能。
首先,我们需要引入jar包:lucene-highlighter-3.6.1.jar。
(1)自定义高亮标签
public void lighter01(){
try {
String txt = "宿命得不到宽恕,往事却在轮回中重演。";
Query query = new QueryParser(Version.LUCENE_36, "f", new MMSegAnalyzer()).parse("宿命轮回");
QueryScorer scorer = new QueryScorer(query);
Fragmenter fragmenter = new SimpleSpanFragmenter(scorer); //分段
Formatter formatter = new SimpleHTMLFormatter("<span style='color:red'>", "</span>"); //自定义标签
Highlighter highlighter = new Highlighter(formatter,scorer);
highlighter.setTextFragmenter(fragmenter);
String str = highlighter.getBestFragment(new MMSegAnalyzer(), "f", txt);
System.out.println(str);
} catch (IOException e) {
e.printStackTrace();
} catch (InvalidTokenOffsetsException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
在这个方法中,使用了MMSegAnalyzer分词器对一句话进行了分词,自定义了html标签。输出结果如下:

我们的关键词是“宿命轮回”,分词器把他们分成了两个词,并分别添加了<span>标签,这个标签我们定义成了红色,也可以根据需求定义成其他颜色或其他标签,比如超链接什么的。
如果这个分词没有达到想要的效果,就可以使用前面的自定义分词来处理一下。我们这个示例解析的是固定的一句话,即便生成索引保存到硬盘,我们现在也只是对一个域实现了高亮。在实际项目中,我们需要的是标题和内容都要实现高亮。这就需要使用多个域的联合查询了。
备注:高亮显示的效率我没测试过,投入实际使用请自行评估。
(2)多个域高亮显示
我们来实现这样一个需求:传入一个字符串,在标题和内容中同时查找,并都以高亮的形式显示出来。
因为需要在多个域中进行同样的高亮处理,所以我们它封装成一个方法,传入分词器,Query,查询内容和域的信息,返回处理后结果。
public String lighterStr(Analyzer a,Query query ,String txt,String fieldname) throws IOException, InvalidTokenOffsetsException{
String str = null;
QueryScorer scorer = new QueryScorer(query);
Fragmenter fragmenter = new SimpleSpanFragmenter(scorer);
Formatter formatter = new SimpleHTMLFormatter("<span style='color:red'>", "</span>");//设置标签
Highlighter highlighter = new Highlighter(formatter, scorer);
highlighter.setTextFragmenter(fragmenter);
str = highlighter.getBestFragment(a, fieldname, txt);
if(str==null)return txt;
return str;
}public void searcherByHighlighter(String name){
try {
Analyzer a = new MMSegAnalyzer();
IndexSearcher searcher = new IndexSearcher(IndexReader.open(FileIndexUtils.getDirectory()));
//MultiFieldQueryParser可以搜索多个域
//在一个String[]数组中,设置搜索域
MultiFieldQueryParser parser = new MultiFieldQueryParser(Version.LUCENE_36, new String[]{"title","content"}, a);
Query query = parser.parse(name);
TopDocs tds = searcher.search(query, 2); //返回两条数据
for(ScoreDoc sd : tds.scoreDocs){
Document doc = searcher.doc(sd.doc);
String title = doc.get("title");
//调用上面封装的方法
title = lighterStr(a,query,title,"title");
System.out.println(title); //输出标题
System.out.println("***************************");
String content = new Tika().parseToString(new File(doc.get("path")));
content = lighterStr(a,query,content,"content");
System.out.println(content); //输出内容
System.out.println("------------------------------");
}
searcher.close();
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
} catch (InvalidTokenOffsetsException e) {
e.printStackTrace();
} catch (TikaException e) {
e.printStackTrace();
}
}
这个索引是由各种文本生成的,包含.pdf/.doc/.xls/.vm/.html等格式的文件,内容比较杂乱,这里就随便搜个词吧:
searcherByHighlighter("编程");
输出结果如下:

标题和内容之间使用了星号分割线,每个结果之间使用了减号分割线。这个结果还是比较靠谱的,标题和内容中的“编程”均被加上了标签,实现了多个域的高亮显示。当然,重点在MultiFieldQueryParser。
LUCENE基础内容到这就结束了,如果想把它应用到项目中去,还需要再重点学习索引建立和搜索等各方面的优化。
备注:再说一个我遇到的问题吧。在创建索引的时候,如果单个文档过大,很容易出现内存溢出。
6.4近实时搜索
这点内容整理的很痛苦,网上资料大多是3.5版本的,我看着3.5的教程学习的3.6版本,前期还好,到了这个地方变动太大了,方法完全不一样。传闻有些大神直接使用Zoie去了(这是一个构建在Apache Lucene之上的实时搜索和索引系统)。
很多项目中都会用到实时搜索,即要求刚添加的索引就应该被检索到。前面也提到过,当数据量非常大的时候,更新索引是一件很耗时的事情。实现实时搜索的方案就是将新增、更改等操作信息保存在内存中,用线程周期性的重新打开IndexSearcher,等到提交的时候再将索引写入磁盘。
Lucene通过NRTManager和SearcherManager实现了实时搜索。
在3.5版本中,通过 SearcherManager 获取IndexSearcher。通过 NRTManager管理 IndexWriter,封装了对索引的增、删、改等操作。通过 NRTManager 的getSearcherManager(true); 方法,在索引发生改变时重新获取 SearcherManager。还有很重要的一点,NRTManager 是线程安全的。
然而在3.6中,NRTManager 发生了很大的变化,不再提供增、删、改操作,没有了addDocument,deleteDocument等方法,将这些交付给了TrackingIndexWriter类来执行。
流程:
① 创建TrackingIndexWriter:管理 IndexWriter,将增、删、改等方法暴露给用户调用,它的操作全部在内存中进行,如果不调用commit方法,磁盘上的索引是不会发生改变的。
② 创建SearcherManager:通过 acquire() 方法获取 IndexSearcher,通过 maybeRefresh()方法检测是否需要刷新,通过 release 方法释放 IndexSearcher。
③ 创建 NRTManager:和SearcherManager功能基本一样。但官方说“The difference vs SearcherManager is that thisclass enables individual requests to wait until specific indexing changes arevisible.”。
④ 创建NRTManagerReopenThread:该线程负责实时跟踪索引内存变化。
备注:若程序在运行中崩溃,没有commit的索引数据将会丢失。
(1) 近实时搜索的创建
Directory directory = null;
IndexWriter writer = null;
TrackingIndexWriter tiw = null;
SearcherManager mgr = null;
NRTManager nrtMgr = null;
//为了能看出效果,使用磁盘索引
directory = FSDirectory.open(new File("D:/Test/index/index02"));
writer = new IndexWriter(directory,
new IndexWriterConfig(Version.LUCENE_36,
new StandardAnalyzer(Version.LUCENE_36)));
//创建TrackingIndexWriter,替代IndexWriter
tiw = new TrackingIndexWriter(writer);
//创建NRTManager。SearcherFactory可以单独创建,这里使用内部类实现。
nrtMgr = new NRTManager(tiw, new SearcherFactory(){
@Override
public IndexSearcher newSearcher(IndexReader reader) throws IOException {
//每次刷新IndexSearcher都会执行这里,可以根据需求做些过滤等设置
System.out.println("reopen");
return super.newSearcher(reader);
}
});
//NRTManager的reopen线程,根据设置的时间定期刷新NRTManager
NRTManagerReopenThread reopen = new NRTManagerReopenThread(nrtMgr, 5.0, 0.025);//最小25秒
reopen.setDaemon(true);//设置为后台线程,程序关闭自动退出
reopen.setName("NRTManager Reopen Thread");//设置线程名称
reopen.start();//启动线程
(2) 近 实时搜索的使用
public void search03(){
IndexSearcher search = null;
try {
//mgr.maybeReopen(); //3.5中使用这个方法,但在3.6中已经被弃用了
mgr.maybeRefresh();//如果索引有变动,刷新SearcherManager
search = mgr.acquire();//通过SearcherManager获取IndexSearcher
//精确搜索,content中包含like的
TermQuery query = new TermQuery(new Term("content","like"));
TopDocs tds = search.search(query, 100);
for(ScoreDoc sd:tds.scoreDocs){
Document doc = search.doc(sd.doc);
System.out.println(sd.doc+"-"+doc.get("name")+"["+doc.get("email")+"]-->"+doc.get("id"));
}
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally{
try {
mgr.release(search); //通过release方法释放IndexSearcher
} catch (IOException e) {
e.printStackTrace();
}
}
}
备注:这是查询,增、删、改操作就不演示了,只是把IndexWrite换成了TrackingIndexWriter,方法都是一样的,一定记得在最后执行commit()。另外IndexSearcher还可以通过NRTManager获取。















 1222
1222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









