






 本文介绍了Scrapy的命令行工具及其应用场景,包括创建项目、启动爬虫、调试解析等功能。详细展示了如何利用Scrapy shell进行页面数据的提取实验,以及如何通过XPath和CSS选择器抓取特定内容。
本文介绍了Scrapy的命令行工具及其应用场景,包括创建项目、启动爬虫、调试解析等功能。详细展示了如何利用Scrapy shell进行页面数据的提取实验,以及如何通过XPath和CSS选择器抓取特定内容。
本博客地址【http://blog.csdn.net/xiantian7】
scrapy 命令行工具
scrapy 提供了一些命令行工具(Command line tool),之前创建 Project 的时候用到的startproject 就是其中之一。而除了这个之外,其他工具也各自提供了相当有用的功能。
$ scrapy
Scrapy 0.14.4 - project: lawson
Usage:
scrapy <command> [options] [args]
Available commands:
crawl Start crawling from a spider or URL
deploy Deploy project in Scrapyd target
edit Edit spider
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
list List available spiders
parse Parse URL (using its spider) and print the results
runspider Run a self-contained spider (without creating a project)
server Start Scrapyd server for this project
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
Use "scrapy <command> -h" to see more info about a command
如果在执行 scrapy shell "http://www.dmoz.org/Computers/Programming/Languages/Python/Books/"后
输入
response.body【得到Html】response.headers【得到头】
shell
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/"
运行后会进入 Python Interpreter,在这里我们能进行各种试验,配合Firebug 之类的工具,为程序构建一个原型:
shell 会提前初始化一个selector变量 sel ,然后我们可以在命令行中对sel这个变量进行操作
Selectors有下面四个基础方法:
- xpath():返回一系列的selectors,每一个表示一个被xpath参数表达式选择的节点
- css():返回一系列的selectors,每一个表示一个css参数表达式选择的节点
- extract():返回一个选中的数据的unicode字符串
- re():返回一串一个unicode字符串,为使用正则表达式抓取出来的内容
In [1]: sel.xpath(’//title’)【返回选取所有 title子元素,而不管它们在文档中的位置】
Out[1]: [<Selector xpath=’//title’ data=u’<title>Open Directory - Computers: Progr’>]
In [2]: sel.xpath(’//title’).extract()
Out[2]: [u’<title>Open Directory - Computers: Programming: Languages: Python: Books</title>’]
In [3]: sel.xpath(’//title/text()’)【选择在<title>节点中的元素 】
Out[3]: [<Selector xpath=’//title/text()’ data=u’Open Directory - Computers: Programming:’>]
In [4]: sel.xpath(’//title/text()’).extract()
Out[4]: [u’Open Directory - Computers: Programming: Languages: Python: Books’]
In [5]: sel.xpath(’//title/text()’).re(’(\w+):’)【正则匹配-返回一个元组】
Out[5]: [u’Computers’, u’Programming’, u’Languages’, u’Python’]
又一个例子
假如我们要处理的页面由下面这样子的组成
<fieldset class="fieldcap">
<legend>See also:</legend>
<ul class="directory">
<li>
<a href="/Computers/Programming/Languages/Python/Resources/">Computers: Programming: Languages: Python: Resources</a>
<em>(5)</em>
</li>
<li>
<a href="/Computers/Programming/Languages/Ruby/Books/">Computers: Programming: Languages: Ruby: Books</a>
<em>(7)</em>
</li>
</ul>
</fieldset>
<fieldset class="fieldcap fieldcapN">
<legend>This category in other languages:</legend>
<ul class="language">
<li>
<a href="/World/Deutsch/Computer/Programmieren/Sprachen/Python/B%C3%BCcher/">German</a>
<em>(7)</em>
</li>
<li>
<a href="/World/Russian/%D0%9A%D0%BE%D0%BC%D0%BF%D1%8C%D1%8E%D1%82%D0%B5%D1%80%D1%8B/%D0%9F%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5/%D0%AF%D0%B7%D1%8B%D0%BA%D0%B8/Python/%D0%9A%D0%BD%D0%B8%D0%B3%D0%B8/">Russian</a>
<em>(3)</em>
</li>
</ul>
</fieldset>就是这个网站:http://www.dmoz.org/Computers/Programming/Languages/Python/Books/
检查了这个页面,偶们发现我们要的信息放在了<ul> 元素中间,
其实是在下面的 <li>元素中间,那么我们可以这样提取:
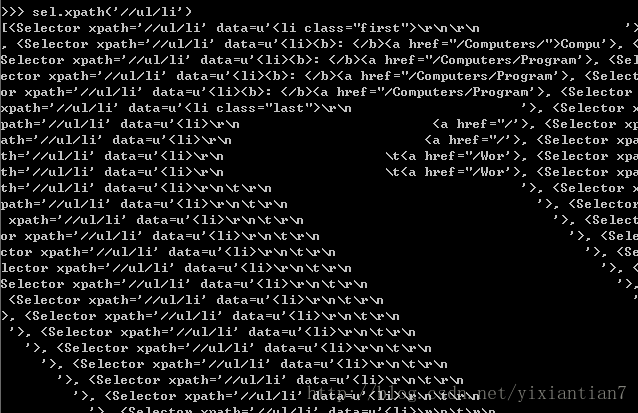
sel.xpath(’//ul/li’)
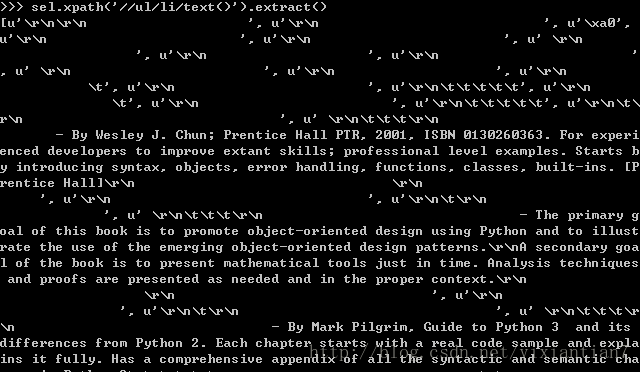
页面的描述可以这样提取
sel.xpath(’//ul/li/text()’).extract()
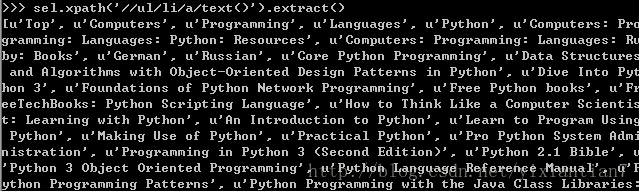
页面标题可以这样提取
sel.xpath(’//ul/li/a/text()’).extract()
页面链接可以这样提取:
sel.xpath(’//ul/li/a/@href’).extract()
四个命令得到结果的:

.xpath()这个方法返回的是一个selectors的列表,所以我们可以把代码 写得更加简练一点
sites = sel.xpath(’//ul/li’)
for site in sites:
title = site.xpath(’a/text()’).extract()
link = site.xpath(’a/@href’).extract()
desc = site.xpath(’text()’).extract()
print title, link, desc那么我们的Spider的代码就可以写成这样子
#-*- coding: utf-8 -*-
from scrapy.spider import Spider
class DmozSpider(Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = ["http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
sel = Selector(response)
sites = sel.xpath('//ul/li')
for site in sites:
title = site.xpath('a/text()').extract()
link = site.xpath('a/@href').extract()
desc = site.xpath('text()').extract()
print title, link, desc这就是用命令行来为编写代码带来方便的一个例子
而 shell 不仅能从命令行直接调用,还能从程序中调用直接进入以便分析程序做调试:
class LawsonSpider(BasePoiSpider):
...
def parse_geo(self, response):
inspect_response(response)
def parse_store_list(self, response):
...这样在执行到
parse_geo 时就会掉入 shell 界面,可以做进一步调试。
item的使用
item类使用来装抓取的数据的容器
所以在parse函数中如果需要保存我们抓取的数据,那么需要在后面加这么两句【为方便看,代码段全部贴出】
class DmozSpider(Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = ["http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
sel = Selector(response)
sites = sel.xpath('//ul/li')
for site in sites:
title = site.xpath('a/text()').extract()
link = site.xpath('a/@href').extract()
desc = site.xpath('text()').extract()
print title, link, desc
sites = sel.xpath(’//ul/li’)
for site in sites:
title = site.xpath(’a/text()’).extract()
link = site.xpath(’a/@href’).extract()
desc = site.xpath(’text()’).extract()
items.append(item)
return items在命令行中最简单的存储抓取数据的命令是:
scrapy crawl dmoz -o items.json -t json
会产生一个items.json来存储我们抓取的数据
这种存储数据的方法只适合小量数据,大量数据需要在pipelines.py,中 写相关的处理函数
详解 Scrapy shell
命令:
scrapy shell <url>
用来爬取url这个网页
输入上面这个命令以后,可以继续输入下面几个命令
shelp() : 打印目前可以使用的object和shortcut
fetch (request_or_url ):从request返回一个新的response,或者是刷新对应的object
view(response):在浏览器中打开这个response,这个命令会在你的电脑上生成一个临时文件,并且这个文件不会自动删除
可以使用的object
crawler: 目前可以使用的爬虫对象
spider:可以用来爬取url 的蜘蛛机器人
request:最后被抓取 的页面的对象
reponse :包含最后抓取页面对象的返回值
sel:产生最后抓取页面对应的selector
setting:目前蜘蛛机器人的设置

















 821
821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









