







查看python镜像:
pip config list如果为空的话,设置清华镜像:
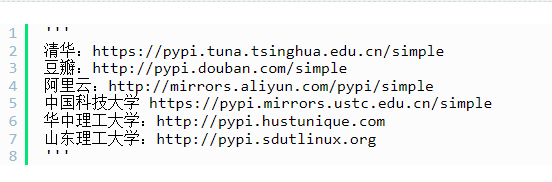
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple镜像地址:
安装scrapy:
如果python版本是3
就使用
pip3 install scrapy
如果是2
使用
pip install scrapy安装结束后查看scrapy版本:
scrapy --versionscrapy项目开发流程:

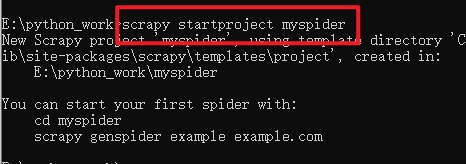
创建项目:
结果展示:
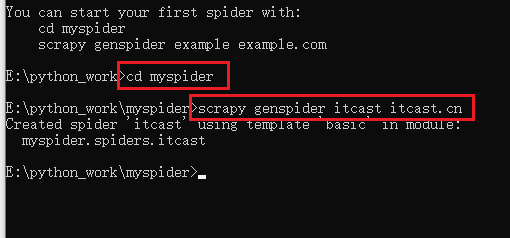
创建爬虫:
1进入目录
2编写命令
目录结果:
编写代码:下载某一个首页:
根目录下运行:
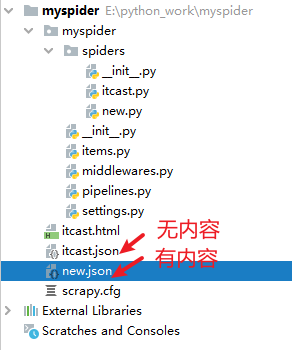
根目录下出现一个文件:
附加:此处介绍 xpath的语法:
相对路径: //
绝对路径:/
bottom_home下的btm_menu 怎么写?
res=response.xpath('//div[@class="bottom_home"]/div[@class="btm_menu"]').get()
直接获取文本: /text()
text() 获取文本内容 get() 剔除selector后的内容
获取数量: len(node_list)
获取一个列表:
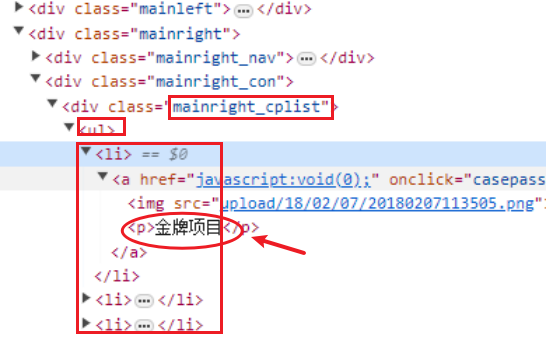
对应代码:
import scrapy
class ItcastSpider(scrapy.Spider):
name = "itcast"
allowed_domains = ["****.com"]
start_urls = ["http://www.****.com/case.php?language=zh"]
def parse(self, response):
node_list = response.xpath('//div[@class="mainright_cplist"]/ul/li')
for node in node_list:
temp={}
temp['name']=node.xpath('./a/p/text()').get()
print(temp)
break执行命令:(--nolog的意思是去掉日志信息)
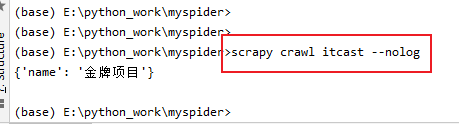
如何通过管道将数据保存到json文件中?
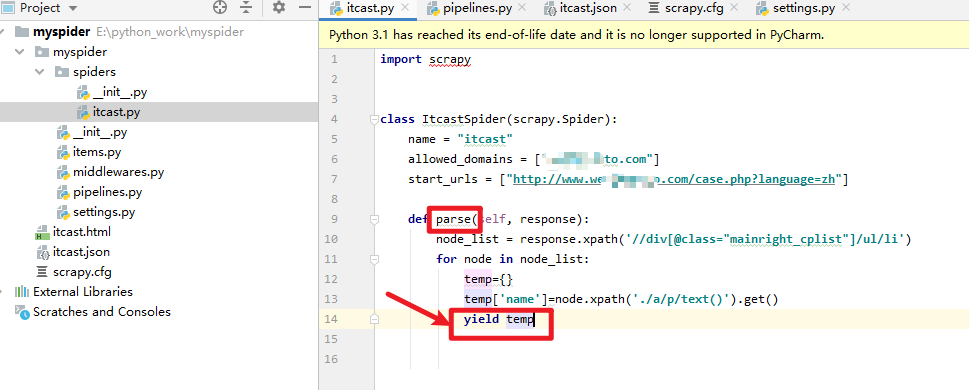
第一步:
在爬虫中将数据存入管道:
第二步: 开通管道:
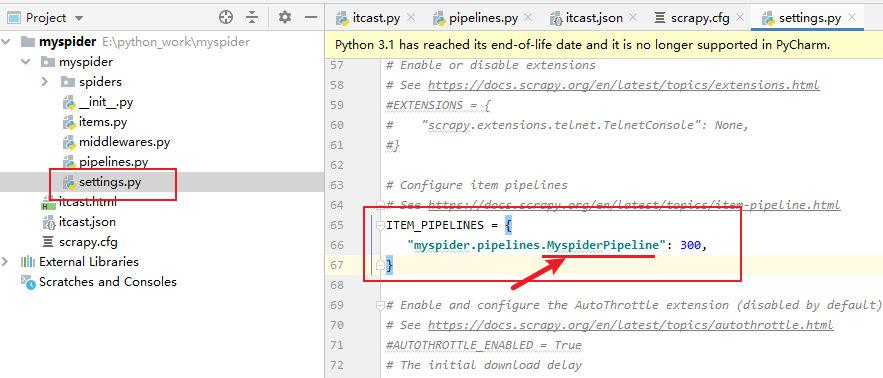
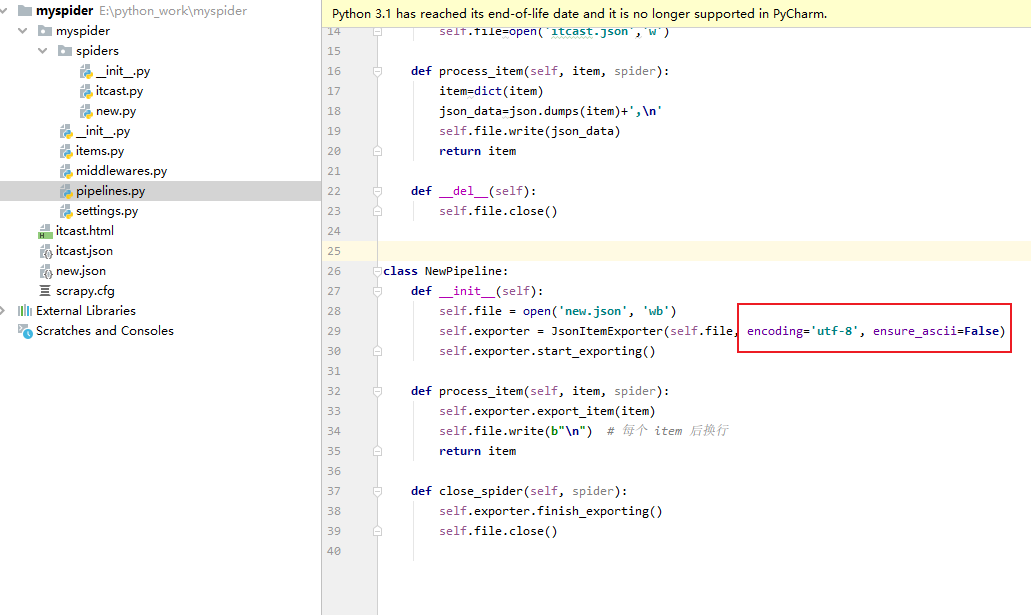
第三步:处理管道
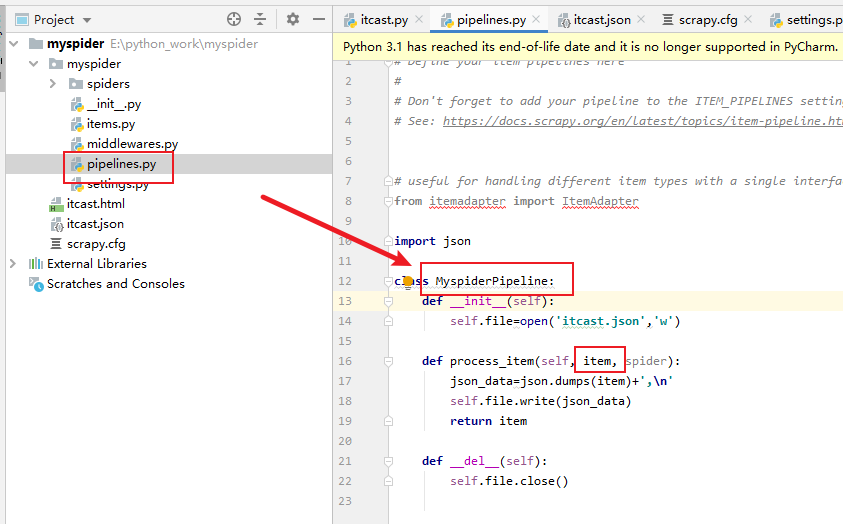
第四步:运行命令:

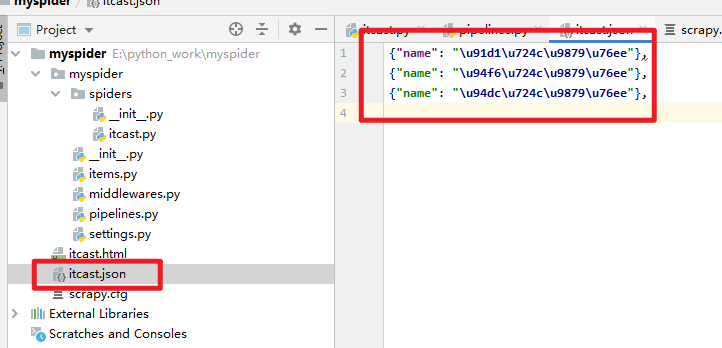
最终查看:生成的文件:
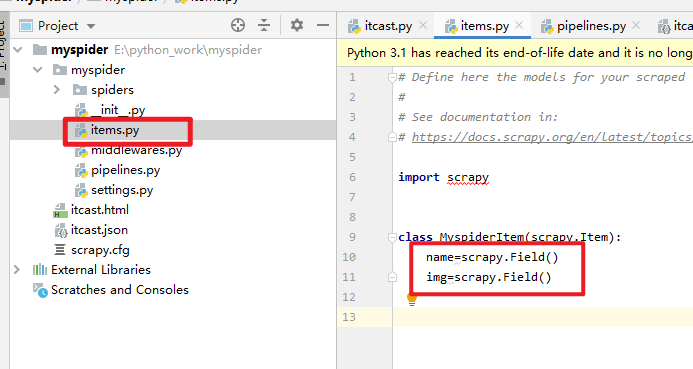
如何进行建模?
如何理解建模?就是将存储的数据字段进行预先定义。
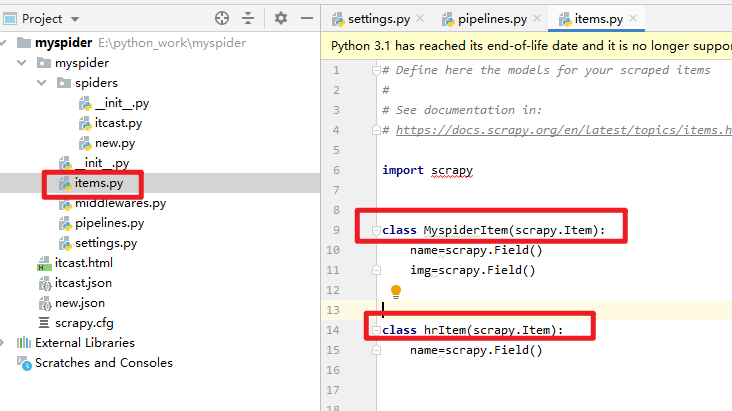
建模两个字段:name和img
爬虫文件中引入建模:
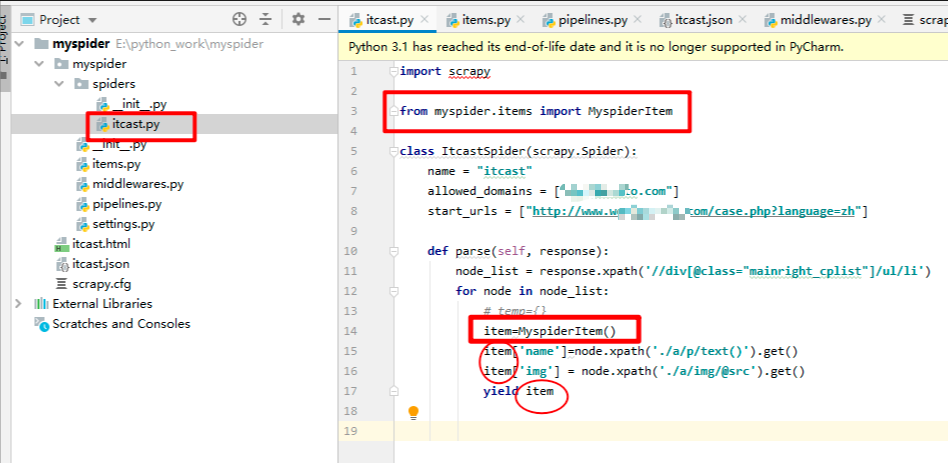
管道文件中,将item进行字典化:
运行命令:
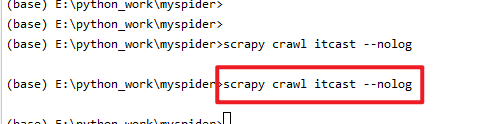
最终展示:
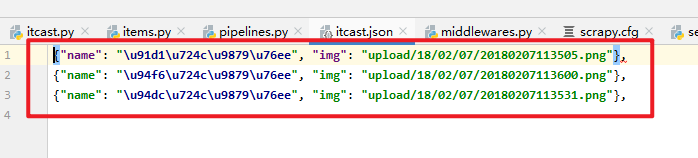
循环前的数据截止到哪里?li 上
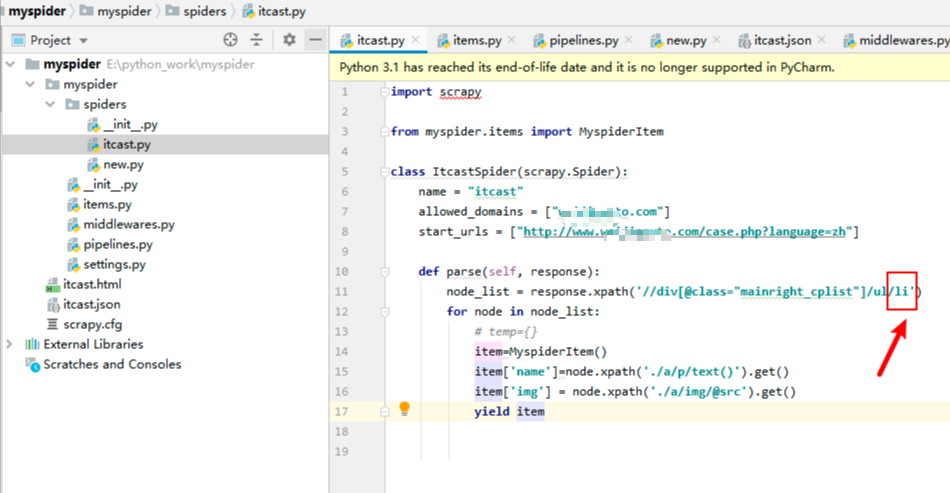
指定爬虫文件的管道怎么写?
1 注释掉settings中的管道设置:
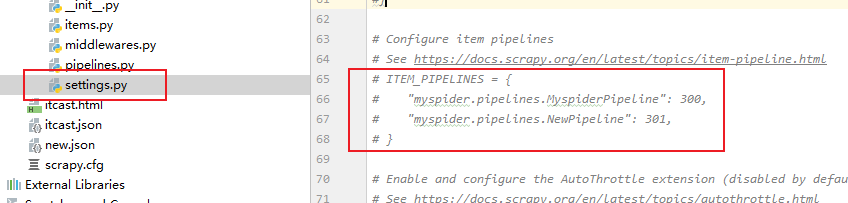 2 两个管道文件:
2 两个管道文件:
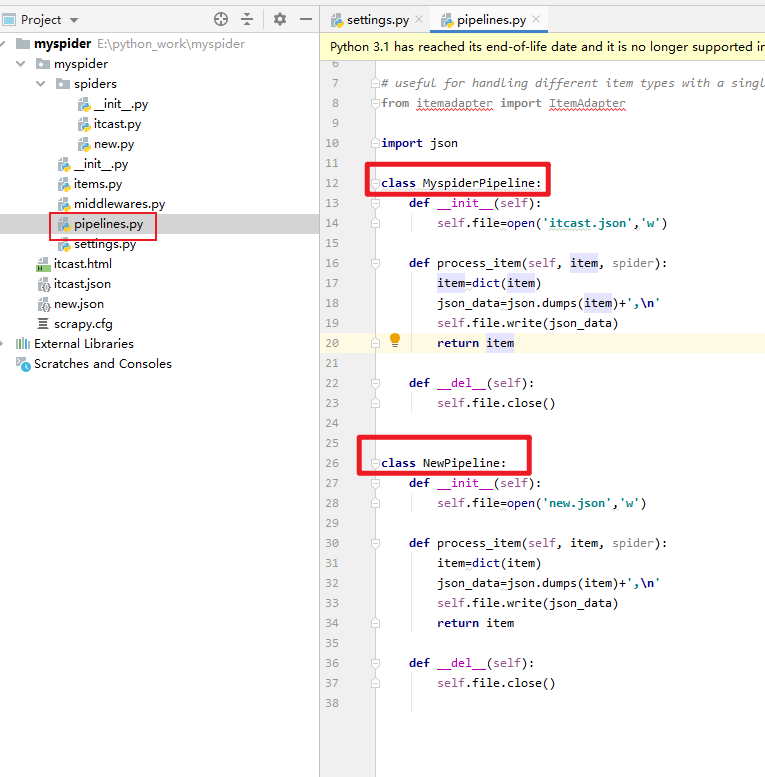
3 两个模型:
4 爬虫文件中指定管道:
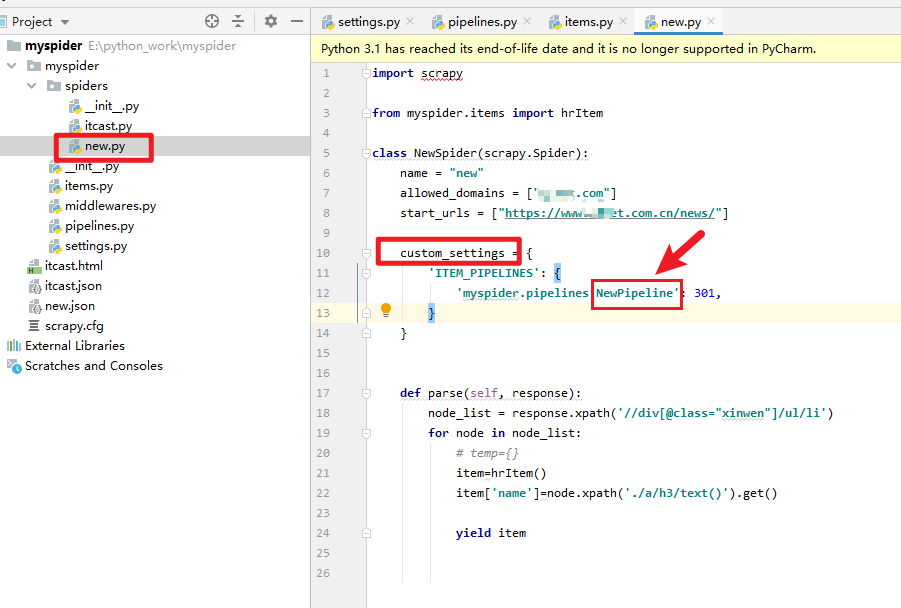
4 运行:
.5 展示:
如何翻页?
重新调用:callback=self.parse 重新执行parse方法

管道的中文写法:
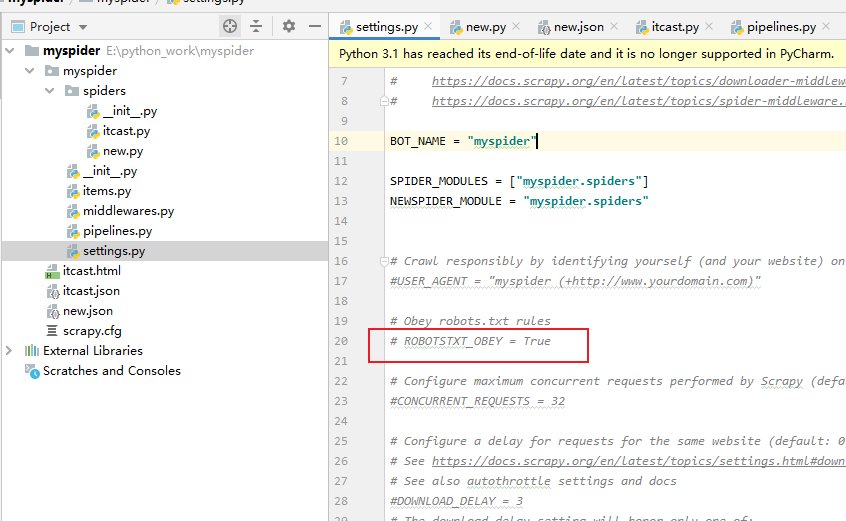
关闭robots.txt:
执行命令:

翻页注意点:
1 域名中不能写错,否则只能获取第一页的数据:
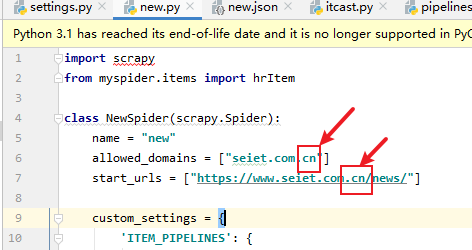
2 执行结果如果不正确,一定要将命令中nolog去掉进行排错:
根据新闻列表并获取详情页内容,怎么写?(注意,将meta传过去)
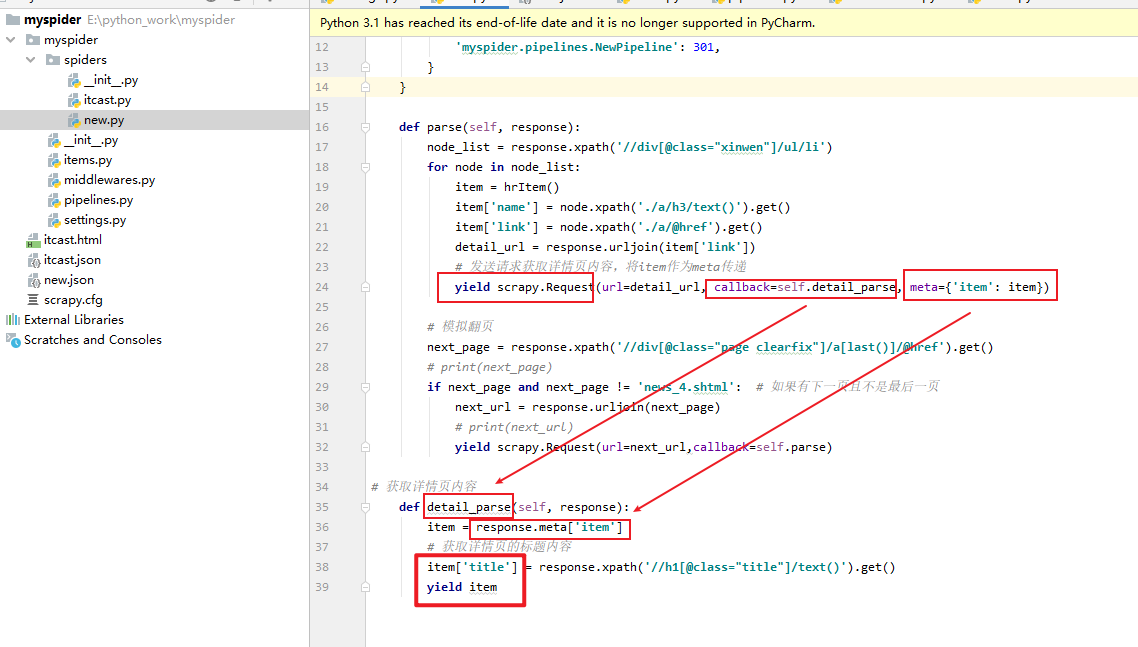
对应代码:
import scrapy
from myspider.items import hrItem
class NewSpider(scrapy.Spider):
name = "new"
allowed_domains = ["***.com.cn"]
start_urls = ["https://www.***.com.cn/news/"]
custom_settings = {
'ITEM_PIPELINES': {
'myspider.pipelines.NewPipeline': 301,
}
}
def parse(self, response):
node_list = response.xpath('//div[@class="xinwen"]/ul/li')
for node in node_list:
item = hrItem()
item['name'] = node.xpath('./a/h3/text()').get()
item['link'] = node.xpath('./a/@href').get()
detail_url = response.urljoin(item['link'])
# 发送请求获取详情页内容,将item作为meta传递
yield scrapy.Request(url=detail_url, callback=self.detail_parse, meta={'item': item})
# 模拟翻页
next_page = response.xpath('//div[@class="page clearfix"]/a[last()]/@href').get()
# print(next_page)
if next_page and next_page != 'news_4.shtml': # 如果有下一页且不是最后一页
next_url = response.urljoin(next_page)
# print(next_url)
yield scrapy.Request(url=next_url,callback=self.parse)
# 获取详情页内容
def detail_parse(self, response):
item = response.meta['item']
# 获取详情页的标题内容
item['title'] = response.xpath('//h1[@class="title"]/text()').get()
yield item
















 1551
1551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









