







上一篇我们安装了Linux系统,想要搭建hadoop集群,还需要安装一些软件。比如JDK和hadoop,下面以JDK1.8和hadoop2.9.0为例介绍如何安装与配置。配置完一台Linux后只需要将这台机器复制几份后配置就完成了几群的搭建。
首先还是去官网下载JDK1.8和hadoop2.9.0,我都是以tar 方式安装。
第一步下载压缩文件使用Xftp5将文件上传至Linux系统/usr/java下。执行tar -xzvf jdk-8u151-linux-x64.tar.gz

解压完成后:

配置环境变量vi /etc/profile 添加
export JAVA_HOME=/usr/java/jdk1.8.0_151
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:JRE_HOME/lib
export PATH=$JAVA_HOME/bin:$PATH
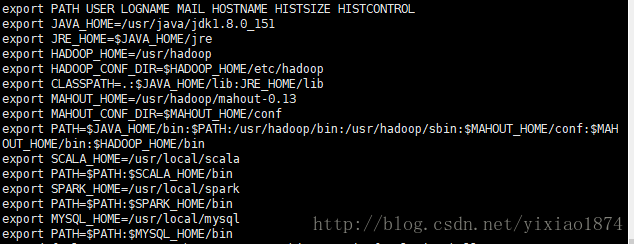
保存退出后,执行 source /etc/profile使环境变量生效

你也可以新建一个java文件输出hello world 试试。
第二步安装hadoop并配置环境变量
tar -xzvf hadoop-2.9.0.tar.gz 并将解压后的文件hadoop-2.7.3修改成hadoop,执行mv hadoop-2.7.3 hadoop
配置hadoop环境便变量,跟JDK相同的操作,vi /etc/profile 添加export(如上图)执行source /etc/profile使配置生效
配置hadoop的JAVA_HOME
vi /usr/hadoop/etc/hadoop/hadoop-env.sh
添加:export JAVA_HOME=/usr/java/jdk1.8.0_151
修改master的/usr/local/hadoop/etc/hadoop/core-site.xml,指明namenode的信息
vi /usr/local/hadoop/etc/hadoop/core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> </configuration> 此时hadoop就配置好了,测试hadoop是否安装完成,执行hadoop

第三步搭建hadoop集群
在虚拟节master上右键复制--》输入名称(slave1、slave2、slave3)--》选择完全复制



然后按照上一篇的配置分别配置slave1 slave2 slave3 IP为
slave1 192.168.56.101
slave2 192.168.56.102
slave3 192.168.56.103
并修改主机名称为slave1 slave2 slave3
使用xshell连接三台机器


修改4台机器的/etc/hosts,让他们通过名字认识对方,测试一下互相用名字可以ping通。
192.168.56.100 master
192.168.56.101 slave1
192.168.56.102 slave2
192.168.56.103 slave3


修改master下的/usr/hadoop/etc/hadoop/slaves

此时hadoop的集群及搭建好了,master上运行start-all.sh

所有机器执行jps会看到下图下过就完成了
















 328
328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









