






使用谷歌colab显卡资源训练模型。白嫖计算资源,主要是自己没有显卡
目录
1、登录谷歌云盘:https://drive.google.com/
3、创建colab笔记本,并装载谷歌云盘,装载完成后,刷新下就出来了
1、登录谷歌云盘:https://drive.google.com/
2、关联colab应用


3、创建colab笔记本,并装载谷歌云盘,装载完成后,刷新下就出来了
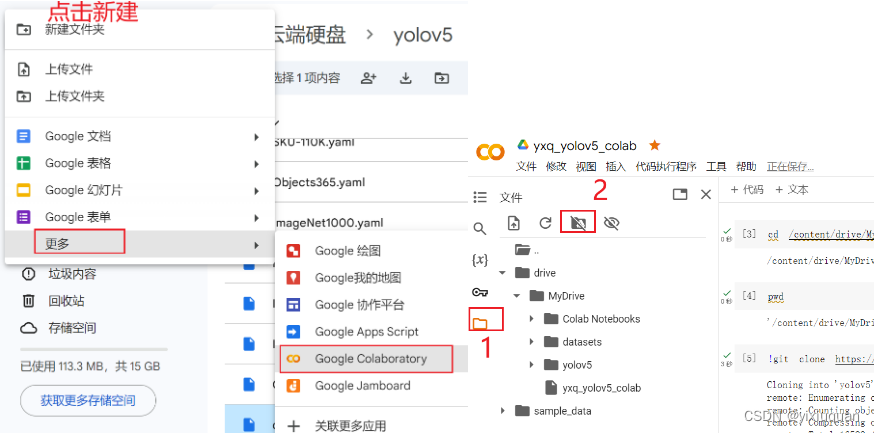
4、下载yolov5代码、coco128
先右键MyDrive 复制路径

点击左上角的+代码
在文本输入框中输入:cd /content/drive/MyDrive 表示进入该目录下

下载代码
!git clone https://github.com/ultralytics/yolov5
cd yolov5/
在yolov5下面创建datasets文件夹,并进入,下载coco128.zip并解压
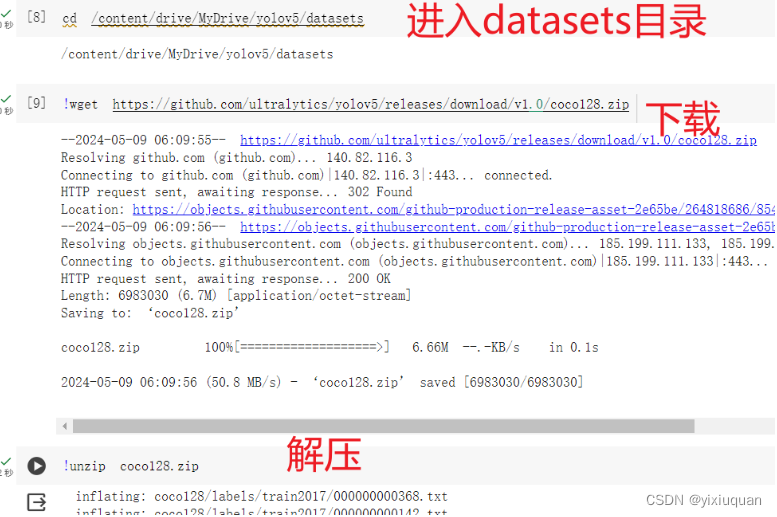
删除coco128里面原先的图片和标注信息

5、上传labelimg标注的图片和标注信息
去谷歌云盘,进入yolov5/datasets/coco128/labels/train2017目录下,将标注的txt文件拖进来。
同样的方法把图片也上传到yolov5/datasets/coco128/imgages/train2017目录下

在这里说下,labelimg一开始不会用直接在默认的类别下新建的,导致我要训练的class标号是15了(yolo是0-15,classes.txt中是第16行)。标注完成后才发现这个问题,就写了python 脚本:
import os
# 设置目录路径
dir_path = 'D:\\work\\svn\\ai\\yolov5-6.0\\coco128\\labels\\train2017'
# 遍历目录下的所有文件
for filename in os.listdir(dir_path):
if filename.endswith('.txt'): # 只处理 txt 文件
file_path = os.path.join(dir_path, filename) # 获取完整的文件路径
with open(file_path, 'r') as file:
lines = file.readlines() # 读取所有行
with open(file_path, 'w') as file:
# 遍历每一行,并替换 '15 ' 为 '0 '
for line in lines:
file.write(line.replace('15 ', '0 ', 1)) # 只替换行的第一个匹配项6、修改训练文件
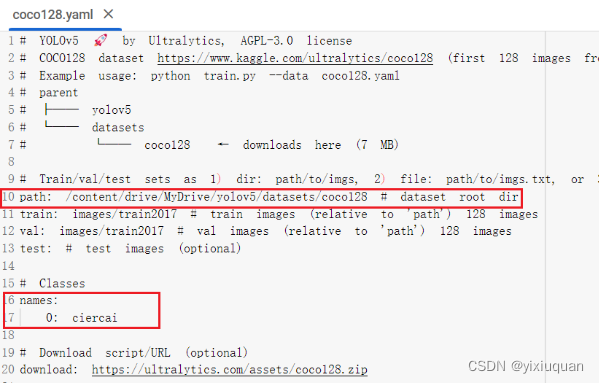
修改/yolov5/data/coco128.yaml
path改成绝对路径,默认的是相对路径,但是训练时拼接起来的路径少了yolov5,所有改成了绝对路径
names 原先有79类,但是此次我只训练一个类别,就把之前的都删除了,只留下了我标注的ciercai
修改/yolov5/models/yolov5s.yaml
由于此次只训练一个class,所以把nc值改成1

修改/yolov5/train.py
--weights:默认就是yolov5s所以不用动
--cfg: 修改default路径./models/yolov5s.yaml
--data: 默认不动
--epochs: 改为100。batch_size和epoch这两个参数可以这么理解,比如我们有1万张图片用来训练,然后batch_size假如等于128,然后epoch=50,那batch_size相当于每次处理128张,然后处理(10000/128)次就把这10000张全处理一遍了,全处理一遍就是一个epoch了,50个epoch就是相当于把10000张图片反复训练了50遍,就像小学生背诵课文他读一遍印象不深,反复读50遍记忆更深刻,算法效果更好。(摘自陈大佬的解释)
--save-period: 设置为0
--device:设置为0,colab只给了一个T4只有一个显卡,所以只能设置为0,如果有其他的显卡可设置为0,1,2,3...
parser.add_argument("--weights", type=str, default=ROOT / "yolov5s.pt", help="initial weights path")
parser.add_argument("--cfg", type=str, default="./models/yolov5s.yaml", help="model.yaml path")
parser.add_argument("--data", type=str, default=ROOT / "data/coco128.yaml", help="dataset.yaml path")
parser.add_argument("--epochs", type=int, default=100, help="total training epochs")
parser.add_argument("--batch-size", type=int, default=16, help="total batch size for all GPUs, -1 for autobatch")
parser.add_argument("--device", default="0", help="cuda device, i.e. 0 or 0,1,2,3 or cpu")
parser.add_argument("--save-period", type=int, default=10, help="Save checkpoint every x epochs (disabled if < 1)")
7、设置显卡T4,显卡训练更快


8、开始训练
!python train.py --img 640 --batch 128 --epochs 100 --data coco128.yaml --cfg ./models/yolov5s.yaml --weights yolov5s.pt --device 0
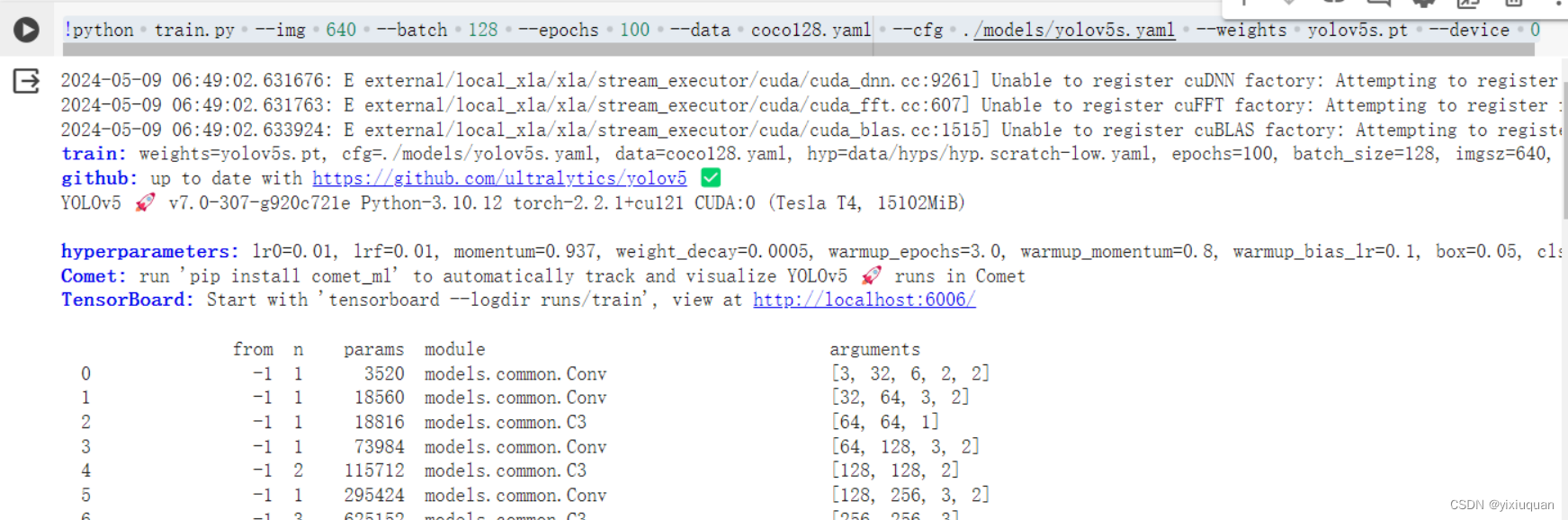
由于之前没执行pip install -r requirements.txt,执行这个命令时会自动去下载需要的包,那样会耽误一些时间。本来训练就很耗时,去下载包的时间可以忽略不计。
我这次训练标注了50张图片,训练时间不算长。

训练完成后,打开/yolov5/runs/train/exp3 看下各个图片
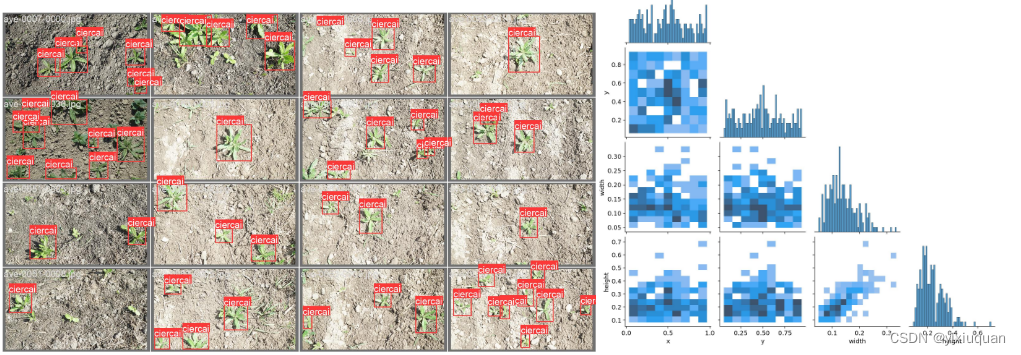
9、验证,测试下效
在yolov5目录下创建test_val文件夹,上传一些验证的图片
执行如下命令进行验证测试:!python detect.py --weights /content/drive/MyDrive/yolov5/runs/train/exp3/weights/best.pt --data coco128.yaml --source /content/drive/MyDrive/yolov5/test_val


如果效果不好,就去修改阈值。打开/content/drive/MyDrive/yolov5/detect.py
修改阈值为0.7,具体改成多少可通过查看结果确认。识别错误的都是低于多少阈值的
parser.add_argument("--conf-thres", type=float, default=0.7, help="confidence threshold")
修改后重新执行下即可,结果会在runs/detect/exp+目录下,依次递增
也可以直接在命令里面设置阈值
!python detect.py --weights /content/drive/MyDrive/yolov5/runs/train/exp3/weights/best.pt --data coco128.yaml --conf-thres 0.6 --source /content/drive/MyDrive/yolov5/test_val
10、后续计划
1、继续标注数据,重新训练
2、增加训练种类,业务逻辑使用的时候只用我们需要的类别ciercai
如果训练多种模型,使用的环境不一样,则使用conda
安装conda
!wget https://repo.anaconda.com/archive/Anaconda3-5.2.0-Linux-x86_64.sh
!chmod +x Anaconda3-5.2.0-Linux-x86_64.sh
!bash ./Anaconda3-5.2.0-Linux-x86_64.sh -b -f -p /usr/local
!conda config --set ssl_verify no 配置参数
!conda create --name yxqyolov5 python=3.8 创建虚拟环境
!conda activate yxqyolov5 激活环境















 5507
5507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









