



 本文介绍了一种使用PHP进行网页爬取的方法,详细步骤包括创建爬虫脚本、执行命令行操作、保存爬取结果到本地文件并最终通过本地服务器访问。通过这个实例,读者可以了解如何利用PHP实现简单的网页爬取。
本文介绍了一种使用PHP进行网页爬取的方法,详细步骤包括创建爬虫脚本、执行命令行操作、保存爬取结果到本地文件并最终通过本地服务器访问。通过这个实例,读者可以了解如何利用PHP实现简单的网页爬取。
1、爬取百度首页
(1)创建文件crawler01.php,代码如下
$curl = curl_init("http://www.baidu.com");
curl_exec($curl);
curl_close($curl);
(2)打开cmd
(3)进入到crawler01.php存放目录
(4)执行php -f crawler01.php 命令,返回下图中的内容说明执行成功
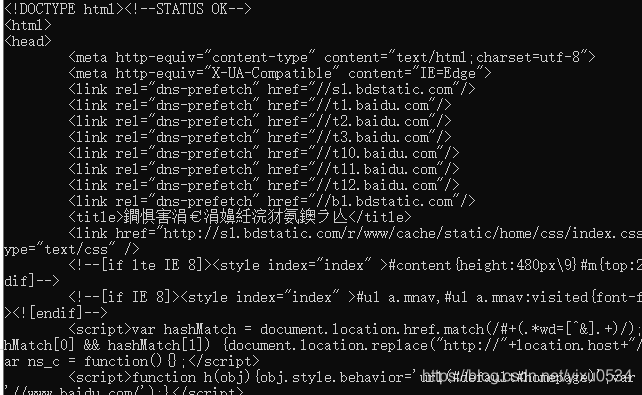
(5)把爬下的内容放入文件中
php -f crawler01.php > baidu.html
(6)通过localhost访问baidu.html文件
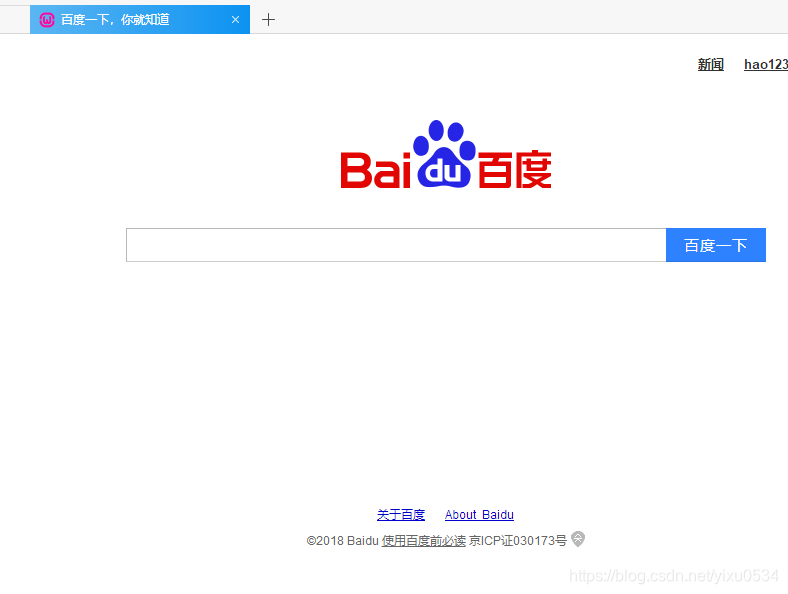

















 587
587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









