







Linux 系统内核分析实验二
--进程的创建与可执行程序的加载
--SA12*****178 叶*冬
1,编程实现fork(创建一个进程实体)
#include<stdlib.h>
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
pid_t pid;
pid=fork();
if(pid==0)
{
printf("child process!\n");
}
else if(pid>0)
{
printf("prarent process!\n");
}
else
{
printf("fork failure!\n");
}
exit(0);
}
运行该文件后:


1,编程实现exec(将ELF可执行文件内容加载到进程实体)
#include<stdlib.h>
#include<unistd.h>
int main()
{
execl("/usr/bin/vi","vi",NULL);
perror("execl");
exit(1);
}
编译后生成文件如下:
运行结果:
打开了vi 编辑器。

3,分析fork和exec的执行过程
一些预备知识:
1、进程可以看做程序的一次执行过程。在linux下,每个进程有唯一的PID标识进程。PID是一个从1到32768的正整数,其中1一般是特殊进程init,其它进程从2开始依次编号。当用完32768后,从2重新开始。
2、linux中有一个叫进程表的结构用来存储当前正在运行的进程。可以使用“ps aux”命令查看所有正在运行的进程。
3、进程在linux中呈树状结构,init为根节点,其它进程均有父进程,某进程的父进程就是启动这个进程的进程,这个进程叫做父进程的子进程。
4、fork的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量、环境变量、程序计数器等)数值都和原进程一致,但是是一个全新的进程,并作为原进程的子进程。
(引自http://www.cnblogs.com/leoo2sk/archive/2009/12/11/talk-about-fork-in-linux.html)
进程的数据结构:
分析过程:
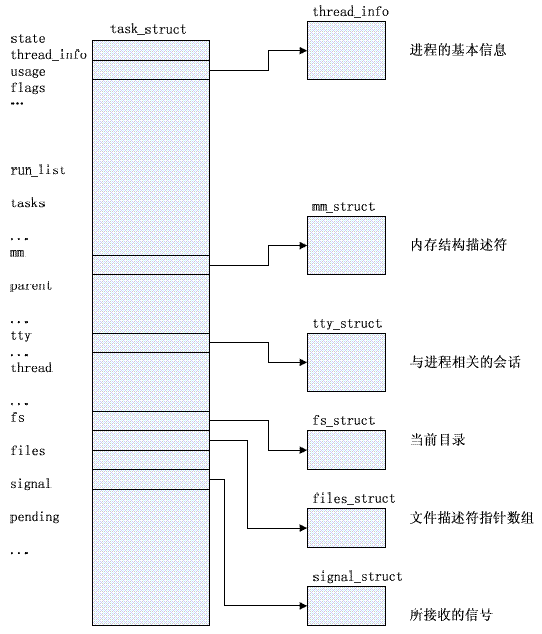
fork( )函数通过复制当前进程创建一个子进程,子进程和父进程的拥有不同的PID,PPID和某些资源和统计量,在linux中fork()是通过
clone()来实现的饿,先调用了clone( ),然后调用了do_fork( )完成了进程创建。
具体过程如下:
1,在创建新进程之前,为新进程准备内核栈,thread_info和task_struct等进程数据结构,并且这些结构中存放着当前进程的值,即
子进程和父进程具有相同的描述符;
2,子进程将自己的进程描述符的一些成员清零或者设定初值;
3,做一些必要准备:子进程的状态设置为TASK_UNINTERRUPTIBLE,确保不会投入运行;设置task_struct中相应的标志位;分配一个有效的进程ID;
4,前期准备工作基本做完以后,根据传递给clone( )的参数标识进行复制或者共享资源等;
5,最后,fork()函数给调用者返回该子进程的pid.
exec( )函数在当前进程的上下文中加载并运行一个新程序,通过代码知道只有在发生错误时才会返回调用函数,可见,exec()只调用一次,
并且从不返回,这是与fork()函数不同的,fork()函数会一次调用,却返回两次。
具体过程如下:
1,删除当前进程的虚拟空间中已经存在的区域结构;
2,加载可执行文件到当前可执行文件的进程地址空间中;
2.1,启动加载器,加载器删除子进程现有的虚拟地址段;
2.2,加载器根据可执行文件的头部信息为之创建一组新的代码段,数据段,堆栈段。其中,堆栈段初始化为零,代码段和数据段映射为该文件的
代码段和数据段;
2.3;根据可执行文件的ELF中的.interp段查找动态连接器的路径名,把动态连接器加载到地址空间,由动态连接器来掌握执行控制权执行一系列
初始化操作,然后根据可执行文件的ELF中的.dynamic段,这个段中保存了动态加载器所需要的相关信息,根据这些信息可以查找和加载可执行文件所依赖的共享对象并映射到进程地址空间和共享区域中;
2.4,当所有的动态链接工作完成后,动态连接器会将控制权转交给该可执行文件的入口地址,即转向执行该文件的_start ()启动代码并调用新进程的main函数开始执行。
3,设置程序计数器的值,使之指向新的代码的入口点,调用启动代码,启动代码设置栈,控制传给新的程序的主函数。
4,ELF文件格式:
ELF主要有三种类型:
1. 可重组(relocatable)文件包含了适合用来链接其他对象文件的代码和数据,从而创建出可执行或可共享的对象文件;
2. 可执行(executable)文件包含了用于执行的程序,该文件规定了exec如何创建一个程序的进程映像;
3. 可共享对象(shared object)文件包含了用来在两个上下文之间链接的代码和数据。首先,链接器ld将该文件和其他的可重组文件或可共享对象文件进行处理后,创建出新对象文件,其次,动态链接器将该新对象文件与可执行文件或共享对象组合,来共同创建一个进程映像;
经过汇编器以及链接器创建成的对象文件,其是在处理器上可直接执行的程序的二进制代表。本部分主要描述文件格式以及其如何用来构建程序。后一部分也描述了对象文件,集中在程序执行所必须的信息上。
数据的表示 :
对象文件格式支持8位、32位等架构的大量处理器。然而,为了保证其容易扩展到更多的体系架构,因此对象文件提供了一些机器独立的控制数据,用来按照统一的方式标明和解释对象文件的内容。对象文件中其余的数据都是按照目标处理器硬编码的,当然不用考虑该文件是在哪个文件上创建的。
对象文件格式中定义的所有数据结构定义都沿守自然尺寸以及对齐原则。必要时,数据结构可以包含填补内容来保证4字节对象的4字节对齐。数据也可以相对于文件起始位置对齐,例如,包含Elf32_Addr成员的数据结构在文件中将会按照4字节对齐。为了保证可移植性,EFL中不使用bit域。
ELF Header结构:
一些对象文件控制结构可能会增长,因为ELF header包含了这些结构的实际尺寸。如果对象文件格式发生改变,那么程序有可能会碰到控制结构比原来大或者比原来小的情况,这样,程序有可能就会忽略一些额外的信息。至于这些丢失的信息如何处理,则依赖于上下文环境。















 1444
1444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









