






JDBC的简介
JDBC(Java Database Connectivity)是Java中用来连接数据可库的一套API,也就是通过Java语言来操作数据库,简单来说,如果不使用JDBC你只能在命令行或SQL数据库图形化工具来操作数据库,而使用JDBC你可以,通过java语言来操作数据库。
数据库驱动的下载
驱动是JDBC接口的实现类,这些实现类是各大数据库厂家自己实现的,所以这些实现类的就需要去数据库厂商相关的网站上下载了。通常这些实现类被全部放到一个xxx.jar包中。
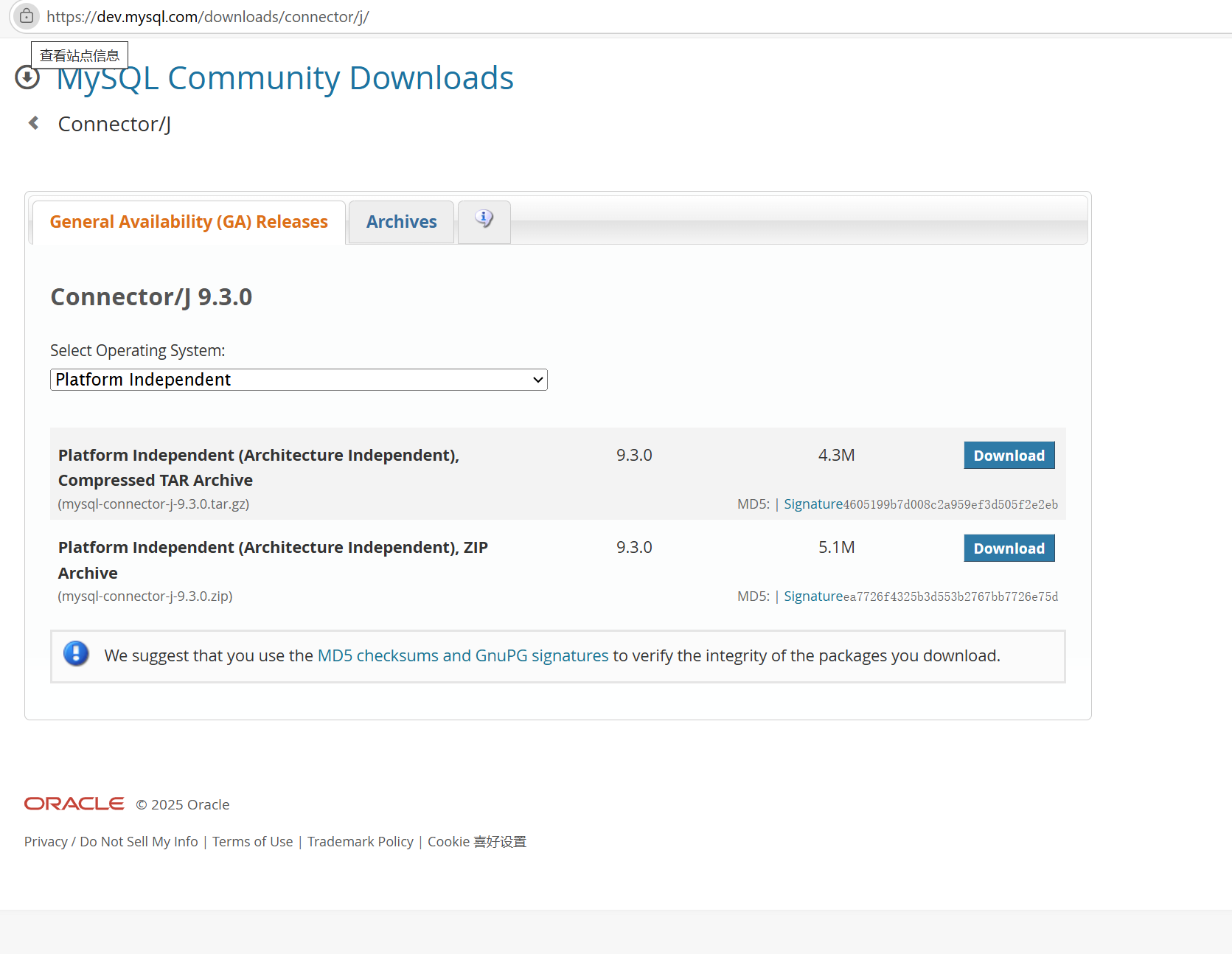
下面演示一下mysql的驱动如何下载【下载mysql的驱动jar包】:
打开页面:https://dev.mysql.com/downloads/connector/j/
JDBC的初级使用
我们已经了解了JDBC的用途,那么我们是如何使用它的呢?(注意:下面使用的官方文档为JDK21的文档)
详细步骤
1.注册驱动
2.获取连接对象
3.获取操作对象,可以有多个
4.使用操作对象,执行sql
5.返回结果集(如果是DQL语句),可以有多个
6.关闭资源(那个先开启,那个先关闭)
具体代码
1.注册驱动
主要有这几个类,
Java.sql.Driver :Java的驱动接口
Java.sql.DriverManager:java的驱动管理类(关于这个类可以去查官网文档)
com.mysql.cj.jdbc.Driver(): mysql提供的核心驱动类
Driver driver =new com.mysql.cj.jdbc.Driver();
DriverManager.registerDriver(driver);//注册驱动
2.获取连接
在DriverManager接口的getConnection(url,user,password);即可
关于这个url:jdbc:mysql://172.28.30.79:3306/jdbc
jdbc:mysql:表示协议
//localhost:3306:表示端口
/jdbc:表示数据库的名字(记得使用自己的)
String url="jdbc:mysql://localhost/jdbc";
String user = "root";//管理员name
String password = "1234";//数据库密码
Connection conn = DriverManager.getConnection(url,user,password);
3.获取数据库操作对象
调用Connection接口的createStatement(),Connection的接口文档在这个网址
Statement stmt = conn.createStatement();
4.执行SQL语句
有多种执行的函数,具体的可去官方文档查[Statement 的使用文档](file:D:/javadoc/docs/api/java.sql/java/sql/Statement.html)
executeUpdate(sql)可用于update delete insert 语句,他只返回执行结果条数
executeQuery(sql)这是用于select 语句,它返回的是结果集ResultSet(其中涉及到结果集操作)
插入
// 4.执行sql语句修改name为wangwu的数据
String sql = "insert into t_user(name,password,ralname,gender,tel) values ('wangwu','123','王五','2','10086')";
// stmt.execute(sql);//这个函数不专业,只有使用DQL语句并查询到结果集才返回true。
int count = stmt.executeUpdate(sql);//返回执行结果条数,适用(insert delete update)
System.out.println(count == 1 ? "插入成功" : "插入失败");
修改
int count = stmt.executeUpdate("update t_user set name='wuwang',password='666',ralname='小三',gender='2',tel='867857' where name='wangwu'");
System.out.println("修改的记录条数为"+count+"条");
删除
int count = stmt.executeUpdate("delete from t_user where name='wuwang'");
System.out.println("修改的记录条数为"+count+"条");
查询
String sql2="select empno as a,ename as b,sal as c from emp";
ResultSet relset=stmt.executeQuery(sql2);
5.获得结果集
注意:查询语句才会获得结果集对象。
String sql2="select empno as a,ename as b,sal as c from emp";
ResultSet relset=stmt.executeQuery(sql2);
6.关闭资源
注意:资源先开后闭,顺序不能乱。
if (relset != null) {
relset.close();
}
if (stmt != null) {
stmt.close();
}
if (conn != null) {
conn.close();
}
总的代码
若需要使用,将数据库信息改成自己的即可。
注意:在使用iDEA的时候,记得将引入驱动jar包。
import java.sql.*;
/*
修改所有名字是wangwu
*/
public class JDBCTest02{
public static void main(String[] args){
Connection conn=null;
Statement stmt=null;
try{
// 1.注册驱动
Driver driver =new com.mysql.cj.jdbc.Driver();
DriverManager.registerDriver(driver);
// 2、建立连接
conn=DriverManager.getConnection("jdbc:mysql://localhost:3306/jdbc","root","1234");
// 3、获取操作对象
stmt=conn.createStatement();
// 4.执行SQL
int count = stmt.executeUpdate("update t_user set name='wuwang',password='666',ralname='小三',gender='2',tel='867857' where name='wangwu'");
System.out.println("修改的记录条数为"+count+"条");
}catch(SQLException e){
e.printStackTrace();
}finally{
// 6、关闭资源
if(stmt != null){
try{
stmt.close();
}catch(SQLException e){
e.printStackTrace();
}
}
if(conn != null){
try{
conn.close();
}catch(SQLException e){
e.printStackTrace();
}
}
}
}
}
驱动注册的特殊手段
-
常规注册
-
类加载,在com.mysql.cj.jdbc.Driver有一个静态代码块,在类加载的时候就会执行 静态代码块,然后就会自动注册驱动。
static {
try {
java.sql.DriverManager.registerDriver(new Driver());
} catch (SQLException E) {
throw new RuntimeException("Can't register driver!");
}
}
import java.sql.*;
public class JDBCTest04{
public static void main(String[] args)throws SQLException{
// 注册驱动
// 1.常规加载
//Driver driver=new com.mysql.cj.jdbc.Driver();
//DriverManager.registerDriver(driver);
// 2.依靠类加载,执行代码块
// class.forName()这个函数会实现类加载
// 这样类就变成字符串了可以在配置文件里面设置属性值,提高拓展性
class.forName("com.mysql.cj.jdbc.Driver");
String url="jdbc:mysql://localhost:3306/jdbc?useUnicode=true&serverTimezone=Asia/Shanghai&useSSL=true&characterEncoding=utf-8";
String user="root";
String password="123520";
Connection conn=DriverManager.getConnection(url,user,password);
System.out.println(conn);
}
}
以上这两种方式,这么说,都可以不要,因为JDBC4.0(java6)之后,系统会自动完成,不过有些数据库驱动程序不支持自动发现功能
设计UbUitls工具类
在了解了JDBC的基本使用之后,我们可以设计一个工具类,解决繁琐的流程
package com.powernode.jdbc.uitls;
import java.sql.*;
import java.util.ResourceBundle;
/**
* JDBC的工具类
*
*/
public class DbUitls {
private DbUitls(){}
private static String url;
private static String user;
private static String password;
private static String driver;
/*
* 在静态代码块里面注册驱动
* 在第一次使用类的时候会加载类,执行动态代码块
* */
static {
//这里我使用了,配置文件的,我在com.powernode.jdbc目录下新建了一个配置文件。里面存放了我的本地数据库的属性信息
//这一不了解属性配置文件的读者可以去先了解一下属性配置就文件的使用。这样可以减少硬编码。
ResourceBundle boundle = ResourceBundle.getBundle("com.powernode.jdbc.jdbc");
driver = boundle.getString("driver");
url = boundle.getString("url");
user = boundle.getString("user");
password = boundle.getString("password");
try {
Class.forName(driver);
} catch (ClassNotFoundException e) {
throw new RuntimeException(e);
}
}
//获取连接,异常往上抛
public static Connection getConnection() throws SQLException {
Connection conn = DriverManager.getConnection(url, user, password);
return conn;
}
// 自动关闭
public static void close(Connection conn, Statement stmt, ResultSet rs){
if (rs != null) {
try {
rs.close();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
if (stmt != null) {
try {
stmt.close();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
}
JDBC的url详细解析
URL 是统一资源定位符 (Uniform Resource Locator) 的缩写,是互联网上标识、定位、访问资源的字符串。它可以用来指定互联网上各种类型的资源的位置,如网页、图片、视频等。
URl通常有协议,服务器名,服务器端口,路径和查询字符串组成。其中:
- 协议是规定了访问资源所采用的通信协议,例如 HTTP、HTTPS、FTP 等;
- 服务器名是资源所在的服务器主机名或 IP 地址,可以是域名或 IP 地址;
- 服务器端口是资源所在的服务器的端口号;
- 路径是资源所在的服务器上的路径、文件名等信息;
URL 在互联网中广泛应用,比如在浏览器中输入 URL 来访问网页或下载文件,在网站开发中使用 URL 来访问 API 接口或文件,在移动应用和桌面应用中使用 URL 来访问应用内部的页面或功能,在搜索引擎中使用 URL 来爬取网页内容等等。
总之,URL 是互联网上所有资源的唯一识别标识,是互联网通信的基础和核心技术之一。
JDBC连接MySQL时的URL格式
JDBC URL 是在使用 JDBC 连接数据库时的一个 URL 字符串,它用来标识要连接的数据库的位置、认证信息和其他配置参数等。JDBC URL 的格式可以因数据库类型而异,但通常包括以下几个部分:
- 协议是jdbc:mysql,其他的数据库厂商就在mysql那里改行了。
- 服务器名是你自己的主机名或ip地址,localhost或172.28.30.79(自己的)
- 端口,一般就是3306
- 数据库名称:表示要连接的数据库的名称。
- 其他可配置的参数,如字符集,链接超出时间,连接池的相关配置。
jdbc:mysql://<host>:<port>/<database_name>?<connection_parameters>
<host>是 MySQL 数据库服务器的主机名或 IP 地址;<port>是 MySQL 服务器的端口号(默认为 3306);<database_name>是要连接的数据库名称;<connection_parameters>包括连接的额外参数,例如用户名、密码、字符集等。
jdbc:mysql://localhost:3306/jdbc
mysql的其他url的其他配置
serverTimezone时区,一般用不上,除非是跨国项目,存在时差。服务器要和数据库统一useSSL:是否使用 SSL 进行连接(Secure Sockets Layer),默认为 true;消耗内存占用CPU的资源,需要权衡利弊。- useUnicode:是否使用Unicode编码进行数据传输,默认是true启用
characterEncoding:连接使用的字符编码,默认为 UTF-8;
下面两个可以不用管。一般都使用默认值。
注意:useUnicode和characterEncoding有什么区别?
- useUnicode设置的是数据在传输过程中是否使用Unicode编码方式。
- characterEncoding设置的是数据被传输到服务器之后,服务器采用哪一种字符集进行编码。
获取结果集合的元数据
集合的元数据就是表的属性,列名,列数,列类型,列长度
结果集调用这个getMetaData()获得元数据
主要代码
// 获取集合元数据,就是表的属性
ResultSetMetaData rsmd = relset.getMetaData();
// 获得列数
int columnCount=rsmd.getColumnCount();
for(int i=1;i<=columnCount;i++){
// 列名
String colName=rsmd.getColumnName(i);
System.out.println("第"+ i +"列的列名是"+colName);
// 列类型
String colTypename=rsmd.getColumnTypeName(i);
System.out.println("第"+ i +"列的列类型是"+colTypename);
// 列长度
int colLongth=rsmd.getColumnDisplaySize(i);
System.out.println("第"+ i +"列长度是"+colLongth);
}
关于SQL注入问题及其解决(PreparedStatement类)
假如你要实现一个等于功能,根据用户名和密码实现登录
使用Statement类实现代码,你可以选择拼接字符串的方式来实现动态SQL语句,但也存在弊端,SQL注入的问题
public class JDBCTest08 {
public static void main(String[] args) {
String name;
String password;
String relName="";
boolean sign=false;
Scanner in=new Scanner(System.in);
System.out.println("用户名:");
name=in.next();
System.out.println("密码:");
password=in.next();
// 实现动态SQL可以使用字符串拼接的方法,但也存在弊端
// 查询数据
String sql="select * from t_user where name='"+name+"' and password='"+password+"'";
try {
Connection conn = DbUitls.getConnection();
Statement stmt = conn.createStatement();
ResultSet resultSet = stmt.executeQuery(sql);
if(resultSet.next()){
relName = resultSet.getString("ralname");
sign=true;
}
System.out.println(sign?"登录成功:欢迎"+relName:"登录失败,用户不存在或密码错误");
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
那么什么是SQL注入?
就拿上面的例子,假如用户输入的password是 1234’ or ‘a’ = 'a
那么SQL语句就变成了
select * from t_user where name 'zhangsan' and password='1234' or 'a' = 'a'
这不就是一个永真语句了吗。
这就是使用字符串拼接的弊端。
SQL注入的本质原因是什么?
- 用户提供的信息中含有SQL的关键字。
- 这些用户提供的关键字参与的SQL语句的编译
SQL是一种安全隐患,黑客通常使用SQL注入来攻击你的系统。
这么避免SQL注入的问题呢?
- java.sql.Statement 它是存在SQL注入现象的,因为它是先进行SQL的拼接在进行SQL的编译的,所以它存在SQL注入的问题。
- java.sql.Statement有一个子接口PreparedStatement可以对SQL语句先进行预编译,然后给编译的好的SQL站位符传值。通过这样就可以解决SQL注入的问题。这样一来虽然用户提供的SQL的关键字,但是不在参与SQL的编译。
使用PreparedStatement解决SQL注入问题
code
Connection conn = DbUitls.getConnection();
// 预编译的操作对象
// 需要提供预编译的SQL语句
// 实现动态SQL可以使用字符串拼接的方法,但也存在弊端
// 查询数据
// 预编译的SQL,其中的值用站位符?代替,不能使用'?'这会被当成一个字符看待。
String sql="select * from t_user where name= ? and password=?";
PreparedStatement ps = conn.prepareStatement(sql);
// 设置站位符的值,数字是指第几个占位符,后面就是提的站位符代替的值,值的类型必须对应。
ps.setString(1,name);
ps.setString(2,password);
ResultSet resultSet = ps.executeQuery();
if(resultSet.next()){
relName = resultSet.getString("relname");
sign=true;
}
System.out.println(sign?"登录成功:欢迎"+relName:"登录失败,用户不存在或密码错误");
all
package com.powernode.jdbc;
import com.powernode.jdbc.uitls.DbUitls;
import java.sql.*;
import java.util.Scanner;
public class JDBCTest09 {
public static void main(String[] args) {
String name;
String password;
String relName="";
boolean sign=false;
Scanner in=new Scanner(System.in);
System.out.println("用户名:");
name=in.nextLine();
System.out.println("密码:");
password=in.nextLine();
// 实现动态SQL可以使用字符串拼接的方法,但也存在弊端
// 查询数据
// 预编译的SQL,其中的值用站位符?代替,不能使用'?'这会被当成一个字符看待。
String sql="select * from t_user where name= ? and password=?";
System.out.println(sql);
try {
Connection conn = DbUitls.getConnection();
// 与编译的操作对象
PreparedStatement ps = conn.prepareStatement(sql);
// 设置站位符的值,数字是指第几个占位符,后面就是提的站位符代替的值,值的类型必须对应。
ps.setString(1,name);
ps.setString(2,password);
ResultSet resultSet = ps.executeQuery();
if(resultSet.next()){
relName = resultSet.getString("relname");
sign=true;
}
System.out.println(sign?"登录成功:欢迎"+relName:"登录失败,用户不存在或密码错误");
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
PreparedStatement与Statement 的区别
区别
- PreparedStatement是预编译SQL语句,Statement是直接执行SQL语句的
- PreparedStatement效率比Statement更高(因为PreparedStatement是编译一次多次运行,每次只需要对占位符传值就可以了,而Statement每次都需要编译并执行SQL语句,因为它就是使用字符串拼接的
PreparedStatement的使用注意事项
- 带有占位符 ? 的SQL语句我们称为:预处理SQL语句。
- 占位符 ? 不能使用单引号或双引号包裹。如果包裹,占位符则不再是占位符,是一个普通的问号字符。
- 在执行SQL语句前,必须给每一个占位符 ? 传值。
- 如何给占位符 ? 传值,通过以下的方法:
- pstmt.setXxx(第几个占位符, 传什么值)
- “第几个占位符”:从1开始。第1个占位符则是1,第2个占位符则是2,以此类推。
- “传什么值”:具体要看调用的什么方法?
- 如果调用pstmt.setString方法,则传的值必须是一个字符串。
- 如果调用pstmt.setInt方法,则传的值必须是一个整数。
- 以此类推…
JDBC批处理
为什么使用批处理
在执行大数据的插入的时候,如果不使用批处理,
那么磁盘的io次数会很多,磁盘之间来回交互,十分耗时,
为了解决这个问题我们可以直接,SQL语句的批处理,不必将SQL一句一句的传输,而是一批一批的传。
使用批处理需要在url的配置路局上添加配置参数rewriteBatchedStatement=true
url=jdbc:mysql://localhost:3306/jdbc?rewriteBatchedStatements=true
ps.addBatch();添加批处理,切记不用不要一次性全部都进行批处理,一次装不下这么多。分几次更佳。
ps.executeBatch();执行批处理。
进行批处理与不进行批处理相差的效率还是很大的(对此读者去试试看两者的速度相差多少)。
package com.powernode.jdbc;
import com.powernode.jdbc.uitls.DbUitls;
import java.io.*;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
/*
* 在执行大数据的插入的时候,如果不使用批处理,
* 那么磁盘的io次数会很多,磁盘之间来回交互,十分耗时,
* 为了解决这个问题我们可以直接,SQL语句的批处理,不必将SQL一句一句的传输,而是一批一批的传。
* 使用批处理需要在url的配置路局上添加配置参数
* rewriteBatchedStatement=true
*
*
* */
public class JDBCTest17 {
public static void main(String[] args) {
Connection conn=null;
PreparedStatement ps = null;
ResultSet rs= null;
long start=System.currentTimeMillis();
try {
conn= DbUitls.getConnection();
String sql = "insert into t_batch(id,name) values (?,?)";
ps = conn.prepareStatement(sql);
int cnt=0;
//向数据库里面插入10000条记录。
for(int i=1;i<=10000;i++){
ps.setInt(1,i);
ps.setString(2,"name"+i);
// ps.executeUpdate();
ps.addBatch();
if(i%500==0){
ps.executeBatch();
}
cnt++;
}
System.out.println("一共插入了"+cnt+"条记录");
} catch (SQLException e) {
e.printStackTrace();
} finally{
DbUitls.close(conn,ps,rs);
}
long end=System.currentTimeMillis();
System.out.println("一共执行了"+(start-end)+"秒");
}
}
JDBC的事务提交
事务是一系列步骤要么成功要么失败。(我讲的事务比较糙,对事务不了解的小伙伴,可以先去了解了解事务的基本概念)。
列如在进行银行账户转账的时候,必须保证账户的两次修改是在同一事务下的。
不使用事务,Connection是自动提交的,如果中间出现异常那么,就会造成数据的丢失。
如a账户转100到b账户,a账户先减100,b账户在加100。但是在这两步直接如果出现了异常,那么可能a账户就白白的减少了100,b账户什么也没有收到。
package com.powernode.jdbc;
import com.powernode.jdbc.uitls.DbUitls;
import java.sql.*;
/*
* 不开启事务实现转账功能
* */
public class JDBCTest19 {
public static void main(String[] args) {
Connection conn=null;
PreparedStatement ps1=null;
PreparedStatement ps2=null;
try {
double d=10000.0;
// 第一条业务
conn = DbUitls.getConnection();
String sql1="update t_act set balance=balance-? where actno=?";
ps1 = conn.prepareStatement(sql1);
ps1.setDouble(1,d);
ps1.setString(2,"act-001");
// 第二条业务
String sql2 = "update t_act set balance=balance+? where actno=?";
ps2 = conn.prepareStatement(sql2);
ps2.setDouble(1,d);
ps2.setString(2,"act-002");
int count1 = ps1.executeUpdate();
int count2 = ps2.executeUpdate();
System.out.println(count1+" "+count2);
} catch (SQLException e) {
throw new RuntimeException(e);
}finally {
DbUitls.close(conn,null,null);
DbUitls.close(null,ps1,null);
DbUitls.close(null,ps2,null);
}
}
}
使用事务可以保证出现异常的时候可以回滚事务。
第一步:开启事务,设置自动提交为false
conn.setAutoCommit(false);
第二步: 提交事务
conn.commit();
第三步:出现异常,事务回滚。
conn.rollback();
package com.powernode.jdbc;
import com.powernode.jdbc.uitls.DbUitls;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
/*
* 开启事务实现转账功能
* */
public class JDBCTest20 {
public static void main(String[] args) {
Connection conn=null;
PreparedStatement ps1=null;
PreparedStatement ps2=null;
try {
double d=10000.0;
// 第一条业务
conn = DbUitls.getConnection();
// 第一步:开启事务,设置自动提交为false
conn.setAutoCommit(false);
String sql1="update t_act set balance=balance-? where actno=?";
ps1 = conn.prepareStatement(sql1);
ps1.setDouble(1,d);
ps1.setString(2,"act-001");
// String s=null;
// s.toString();
// 第二条业务
String sql2 = "update t_act set balance=balance+? where actno=?";
ps2 = conn.prepareStatement(sql2);
ps2.setDouble(1,d);
ps2.setString(2,"act-002");
int count1 = ps1.executeUpdate();
int count2 = ps2.executeUpdate();
System.out.println(count1+" "+count2);
// 第二步: 提交事务
conn.commit();
} catch (Exception e) {
try {
// 第三步:
conn.rollback();
} catch (SQLException ex) {
throw new RuntimeException(ex);
}
throw new RuntimeException(e);
}finally {
DbUitls.close(conn,null,null);
DbUitls.close(null,ps1,null);
DbUitls.close(null,ps2,null);
}
}
}
JDBC中执行存储过程
关于数据库存储过程不太了解的小伙伴可以跳过,如果感兴趣可以先去了解一下数据库存储过程。
- 专门用来执行存储过程的的类:CallableStatement继承PreparedStatement
- 调用存储过程的SQL语句, 注意外边要有个大括号
- 要得到结果必须要注册出参,cs.registerOutParameter(2, Types.INTEGER);
- 获取执行结果 int anInt = cs.getInt(2);
package com.powernode.jdbc;
import com.powernode.jdbc.uitls.DbUitls;
import java.sql.CallableStatement;
import java.sql.Connection;
import java.sql.SQLException;
import java.sql.Types;
/*
* 在java里面调用存储过程
* */
public class JDBCTest21 {
public static void main(String[] args) {
CallableStatement cs=null;
// 专门用来执行存储过程的,CallableStatement
Connection conn = null;
try {
conn = DbUitls.getConnection();
// 调用存储过程的SQL语句
// 注意外边要有个大括号
cs = conn.prepareCall("{call mypro(?,?) }");
// 第一个占位符设置
cs.setInt(1,100);
// 将第二个占位符注册为出参,
// 并且类型为整数类型
cs.registerOutParameter(2, Types.INTEGER);
// 调用存储过程
cs.execute();
// 获取执行结果
int anInt = cs.getInt(2);
System.out.println(anInt);
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
连接池
1.什么是连接池?以及它的作用。
连接池其实是一种缓存技术,就像java里面有一个字符串常量池,创建的字符串常量值,都会放在这个池里面,这样就提高了效率。还有那个-128-127这256个整数也放在一个整数池里面。
在使用JDBC获取连接对象的时候在,需要频繁的进行连接的创建和销毁,这对内存的开销是很大的。这时候就需要使用到连接池了,我们可以将多个连接对象了放到连接池里面,那么每次获取连接池就不需要在创建连接了,大大的提高了性能。
还有一个不使用连接池的弊端,就是无法控制连接的数量,mysql的连接数量是有限的,连接数量太多了,数据库会发生崩溃。使用连接池可以控制连接数量。
javax.sql.DataSource
连接池有很多,不过所有的连接池都实现了 javax.sql.DataSource 接口。也就是说我们程序员在使用连接池的时候,不管使用哪家的连接池产品,只要面向javax.sql.DataSource接口调用方法即可。
另外,实际上我们也可以自定义属于我们自己的连接池。只要实现DataSource接口即可。
Druid连接池的使用
连接池Druid改进DbUitls2
下载Druid的jar包
可以去github下载。
需要属性配置文件
可以通过创建资源文件夹,将配置文件(jdbc.properties)加载到类路径上。
然后通过类路径读取资源文件
配置信息:
url=jdbc:mysql://localhost:3306/jdbc
username=root
password=1234
driverClassName=com.mysql.cj.jdbc.Driver
initialSize=5
minIdle=10
maxActive=20
使用详情
以下是通过类加载器获取资源文件的文件流
// 获取一个输入流,指向一个属性资源文件,从类加载器里面获取属性资源文件的流。
InputStream resourceAsStream =
Thread.currentThread().
getContextClassLoader().
getResourceAsStream("jdbc.properties");
通过这个文件流可以加载属性类对象
// 创建一个属性类
Properties prop = new Properties();
// 将属性配置文件的资源加载到属性类对象里面。
prop.load(resourceAsStream);
获取连接池并在连接池中获取连接对象
// 获取连接池
dataSource = DruidDataSourceFactory.createDataSource(prop);
// 从连接池当中获取连接。
conn = dataSource.getConnection();
package com.powernode.jdbc.uitls;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.InputStream;
import java.sql.*;
import java.util.Properties;
import java.util.ResourceBundle;
/**
* @Description: 使用Druid连接池改进工具类
*/
public class DbUitls2 {
private DbUitls2(){}
// 连接池
private static DataSource dataSource;
static {
Connection conn = null;
try {
// 获取一个输入流,指向一个属性资源文件,从类加载器里面获取属性资源文件的流。
InputStream resourceAsStream = Thread.currentThread().getContextClassLoader().getResourceAsStream("jdbc.properties");
// 创建一个属性类
Properties prop = new Properties();
// 将属性配置文件的资源加载到属性类对象里面。
prop.load(resourceAsStream);
// 获取连接池
dataSource = DruidDataSourceFactory.createDataSource(prop);
// 从连接池当中获取连接。
conn = dataSource.getConnection();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
//获取连接
public static Connection getConnection() throws SQLException {
return dataSource.getConnection();
}
// 自动关闭
public static void close(Connection conn, Statement stmt, ResultSet rs){
if (rs != null) {
try {
rs.close();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
if (stmt != null) {
try {
stmt.close();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
}
n = dataSource.getConnection();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
//获取连接
public static Connection getConnection() throws SQLException {
return dataSource.getConnection();
}
// 自动关闭
public static void close(Connection conn, Statement stmt, ResultSet rs){
if (rs != null) {
try {
rs.close();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
if (stmt != null) {
try {
stmt.close();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
}
总结
学完,JDBC最大的感触就是,学的数据库终于可以用上了,记得写java课程设计的时候只能用文件读写,所有功能硬写,苦不堪言。本来数据库就是用来实现数据操作的,使用编程操作数据库才可以更好的实现业务(个人观点)。最后如果这篇文章有什么问题,希望各位小伙伴可以指出来,欢迎指错。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









