







《数据结构——线性表①(顺序表)》一文中已经讲了线性表顺序存储–顺序表相关内容,
这篇文章一起来学习 线性表的链式存储–链表↓↓↓↓↓
一、链表的定义
线性表的链式存储称为链表,那什么是链式存储呢

其实理解起来就和火车差不多,一节一节的火车车厢被链条连在一起,每节车厢都是独立存在的,根据不同场景的需求,火车的车厢数可以增加或者减少,这是动态可变的;
而链表就拥有以上的这些属性,一节一节的车厢就是链表中的一个一个的节点,这些节点都是独立存在的,而指向下一个节点的指针就是连接下一节车厢的链条。
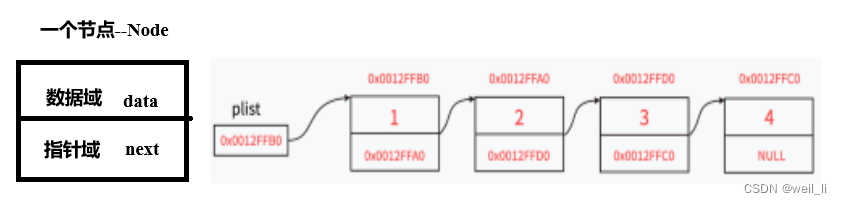
概念:链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
链表其实在内存中的存储并不是连续的,而是随机的,而这里线性意思是,在逻辑上,表中的所有节点都串在一起了,像一条线,可以通过节点的指针域找到其他节点。
二、链表的分类
2.1 单链表
上面介绍链表引用的图片就是一个单链表。下面这也是一个单链表
单链表的每个节点存储有两个元素,一个数据域,一个指针域。

- 单链表的特点是:单链表只能从头节点开始遍历,无法直接访问中间或尾部的节点。
2.2 双链表
双链表的每个节点有三个元素,两个指针域(分别是指向前一个节点和指向下一个节点的指针),一个数据域。

双链表的特点是:双链表打破了单链表只能向后访问的局限性,双链表在除头尾节点之外的节点处,可以向前访问。
2.3 循环链表
-
单向循环链表↓↓↓

链表的最后一个节点指向头节点的单向链表叫 – 单向循环链表 -
双向循环链表↓↓↓

2.4 头节点和头指针
- 头节点:链表中的一个特殊节点,它不存储任何数据,只是作为链表的起始位置
- 头指针:指向链表第一个元素的指针
所以,对于带头结点的链表,头指针指向的是头节点; 对于不带头节点的链表,头指针指向的是链表的第一个节点。
头节点在链表数据结构中有很多好处。
-
头节点可以防止链表为空时指针指向
NULL,从而导致程序出错。在带头结点的链表中,当链表为空时,头结点的指针域指向头结点本身,而不是NULL。 -
头节点方便了单链表的特殊操作,例如在表头插入或删除节点。如果不存在头节点,当进行这些操作时,就需要考虑处理空链表的情况,这会增加代码的复杂性和出现
bug的机会。 -
头节点统一了空表和非空表的处理方式。无论链表是否为空,头指针始终指向头结点,这使得对第一个节点的操作与对中间节点的操作保持一致,减少了代码量,并降低了出现错误的可能性。
链表的结构非常多样,以下情况组合起来就有8种 (2×2×2)链表结构:

三、单链表的基本操作及实现函数
3.1 单链表的类型定义
typedef int elemType;
struct SqList
{
elemType data;
struct SqList* next;
};
typedef struct SqList SList;
3.2 带头结点的单链表代码实例
创建和初始化:创建一个SList类型的结构体变量,数据域不存储有效数据,指针域设置为空
#include<stdio.h>
#include<assert.h>
#include<stdlib.h>
typedef int elemType;
typedef struct SqList
{
elemType data;
struct SqList* next;
}SqList,*pList;
typedef struct SqList SList;
pList CreatList();//创建一个带头结点的单向链表
pList BuyNode(elemType x);//创建一个节点
void HeadAdd(pList list,elemType x);//向链表中插入数据x,头插法
void Delete(pList list,elemType x);//删除链表中的数据x
void Change(pList list, elemType x,elemType newdata);//修改数据
size_t Find(pList list, elemType x);//查找数据X,返回节点位序
void Destroy(pList list);//销毁链表
void Print(pList list);//打印链表中的数据
#include"SqList.h"
pList CreatList()
{
pList list = (pList)malloc(sizeof(SqList));
assert(list);
list->data = -1;//头节点的数据域不存储数据,这里我初始化为-1
list->next = NULL;
return list;
}
pList BuyNode(elemType x)
{
pList node = (pList)malloc(sizeof(SqList));
assert(node);
node->data = x;
node->next = NULL;
return node;
}
void HeadAdd(pList list, elemType x)
{
assert(list);
pList node = BuyNode(x);
node->next = list->next;
list->next = node;
}
void Print(pList list)
{
assert(list);
pList pcur = list->next;
while (pcur)
{
printf("%d->",pcur->data);
pcur = pcur->next;
}
printf("NULL\n");
}
void Delete(pList list, elemType x)
{
assert(list);
pList pcur = list->next;
pList prev = list;
while (pcur)
{
if (pcur->data == x)
{
prev->next = pcur->next;
free(pcur);
pcur = NULL;
return;
}
prev = prev->next;
pcur = pcur->next;
}
printf("Delete fail\n");
}
void Change(pList list, elemType x, elemType newdata)
{
assert(list);
pList pcur = list->next;
while (pcur)
{
if (pcur->data == x)
{
pcur->data = newdata;
return;
}
pcur = pcur->next;
}
printf("Change fail\n");
}
size_t Find(pList list, elemType x)
{
assert(list);
int count = 1;
pList pcur = list->next;
while (pcur)
{
if (pcur->data == x)
{
return count;
}
pcur = pcur->next;
count++;
}
printf("Find fail\n");
}
void Destroy(pList list)
{
pList pcur = list->next;
pList next = NULL;
while (pcur)
{
next = pcur->next;
free(pcur);
pcur = next;
}
free(list);
list = NULL;
}
四、其他链表
3.1 双链表
以下是一个简单的C语言实现双链表的示例代码:
#include <stdio.h>
#include <stdlib.h>
// 定义链表节点结构体
struct Node {
int data; // 存储数据
struct Node* prev; // 指向前一个节点的指针
struct Node* next; // 指向后一个节点的指针
};
// 创建新节点
struct Node* createNode(int data) {
struct Node* newNode = (struct Node*)malloc(sizeof(struct Node));
newNode->data = data;
newNode->prev = NULL;
newNode->next = NULL;
return newNode;
}
// 在链表尾部插入新节点
void appendNode(struct Node** headRef, int data) {
struct Node* newNode = createNode(data);
if (*headRef == NULL) {
*headRef = newNode;
return;
}
struct Node* curr = *headRef;
while (curr->next != NULL) {
curr = curr->next;
}
curr->next = newNode;
newNode->prev = curr;
}
// 在链表中删除指定节点
void deleteNode(struct Node** headRef, int data) {
struct Node* curr = *headRef;
struct Node* prev = NULL;
while (curr != NULL && curr->data != data) {
prev = curr;
curr = curr->next;
}
if (curr == NULL) {
printf("Node with data %d not found.\n", data);
return;
}
if (prev == NULL) {
*headRef = curr->next;
} else {
prev->next = curr->next;
}
if (curr->next != NULL) {
curr->next->prev = prev;
}
free(curr);
}
// 打印链表中的所有节点数据
void printList(struct Node* node) {
while (node != NULL) {
printf("%d ", node->data);
node = node->next;
}
printf("\n");
}
int main() {
struct Node* head = NULL; // 定义链表头指针
appendNode(&head, 1); // 在链表尾部插入节点1
appendNode(&head, 2); // 在链表尾部插入节点2
appendNode(&head, 3); // 在链表尾部插入节点3
printList(head); // 打印链表中的所有节点数据,输出应为:1 2 3
deleteNode(&head, 2); // 删除节点2,输出应为:1 3
printList(head); // 打印链表中的所有节点数据,输出应为:1 3
return 0;
}
3.2 循环链表
以下是C语言实现循环链表的示例代码:
#include <stdio.h>
#include <stdlib.h>
// 定义链表节点结构体
struct Node {
int data; // 存储数据
struct Node* next; // 指向下一个节点的指针
};
// 创建新节点
struct Node* createNode(int data) {
struct Node* newNode = (struct Node*)malloc(sizeof(struct Node));
newNode->data = data;
newNode->next = NULL;
return newNode;
}
// 在链表尾部插入新节点
void appendNode(struct Node** headRef, int data) {
struct Node* newNode = createNode(data);
if (*headRef == NULL) {
*headRef = newNode;
return;
}
struct Node* curr = *headRef;
while (curr->next != NULL) {
curr = curr->next;
}
curr->next = newNode;
newNode->next = *headRef;
}
// 打印链表中的所有节点数据
void printList(struct Node* node) {
while (node != NULL) {
printf("%d ", node->data);
node = node->next;
if (node == NULL) {
printf("\n");
}
}
}
int main() {
struct Node* head = NULL; // 定义链表头指针
appendNode(&head, 1); // 在链表尾部插入节点1
appendNode(&head, 2); // 在链表尾部插入节点2
appendNode(&head, 3); // 在链表尾部插入节点3
printList(head); // 打印链表中的所有节点数据,输出应为:1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3
return 0;
}
3.3 静态链表
静态链表是一种使用数组来模拟链表的数据结构。它通过将数组中的每个元素拆分为两个部分,一个存储数据,一个存储指向下一个元素的索引,来实现链表的功能。
以下是一个简单的C语言实现静态链表的示例代码:
#include <stdio.h>
#define MAXSIZE 100
typedef struct {
int data;
int next;
} Node;
Node array[MAXSIZE];
int head = -1;
int tail = -1;
void init() {
for (int i = 0; i < MAXSIZE; i++) {
array[i].next = -1;
}
}
void insert(int data) {
Node* newNode = &array[tail];
newNode->data = data;
if (head == -1) {
head = tail = 0;
} else {
tail = (tail + 1) % MAXSIZE;
}
newNode->next = head;
head = (head + 1) % MAXSIZE;
}
int search(int data) {
Node* curr = &array[head];
while (curr != &array[head]) {
if (curr->data == data) {
return (curr - array) % MAXSIZE;
} else {
curr = &array[curr->next];
}
}
return -1; // 数据不存在
}
void delete(int data) {
Node* prev = &array[head];
Node* curr = &array[head];
while (curr != &array[head]) {
if (curr->data == data) {
prev->next = (curr->next + 1) % MAXSIZE;
return;
} else {
prev = curr;
curr = &array[curr->next];
}
}
printf("Data not found\n"); // 数据不存在
}
五、顺序表和链表的比较
顺序表和链表是两种不同的线性数据结构,它们各有优缺点,适用于不同的应用场景。
他们在以下几个方面有较大的区别
- 内存空间:顺序表在内存中占据连续的空间,而链表则可以非连续。这使得顺序表在空间利用率上较优,因为它不需要为每个节点额外分配存储空间来存储指针。
- 插入和删除操作:在顺序表中,插入和删除操作需要移动元素来保持连续性,因此时间复杂度通常为O(n)。然而,在链表中,插入和删除操作仅需要更改指针,因此时间复杂度为O(1)。链表在插入和删除操作上更高效。
- 查找操作:在顺序表中,查找操作的时间复杂度通常为O(1),因为我们可以直接通过索引访问元素。而在链表中,查找操作需要从头部开始遍历,时间复杂度为O(n)。
- 动态增长:顺序表通常只能在固定大小的内存空间中操作,而链表可以通过动态分配内存来增长。这意味着链表可以更灵活地处理更多的数据。
- 适用场景:顺序表更适合于小规模数据,因为它在内存中占据连续空间,可以快速访问元素。而链表更适合于大规模数据,因为它可以动态增长并且插入和删除操作更高效。
其实顺序表和链表各有优缺点,选择使用哪种数据结构取决于具体的应用场景和需求。















 181
181











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









