







在第2章中,您学习了如何通过创建一个简单的神经网络来开始计算机视觉,该网络将Fashion MNIST数据集的输入像素与10个标签进行匹配,每个标签代表一种类型(或类别)的服装。虽然你创建了一个非常擅长检测服装类型的网络,但有一个明显的缺点。
你的神经网络是在小的单色图像上训练的,每个图像只包含一件衣服,而那件衣服是在图像的中心。
为了使模型更上一层楼,您需要能够检测图像中的特征。因此,举例来说,与其只看图像中的原始像素,不如我们有一种方法将图像过滤成组成元素。匹配这些元素,而不是原始像素,将有助于我们更有效地检测图像的内容。考虑一下我们在上一章中使用的Fashion MNIST数据集——当检测一只鞋时,神经网络可能被聚集在图像底部的许多暗像素激活,它会将图像视为鞋底。但是当鞋子不再居中,不再填充框架时,这个逻辑就不成立了。
检测特征的一种方法来自摄影和你可能熟悉的图像处理方法。如果你曾经使用像Photoshop或GIMP这样的工具来锐化图像,你正在使用一个数学过滤器来处理图像的像素。这些滤波器的另一个词是卷积(convolution),通过在神经网络中使用这些滤波器,您将创建一个卷积神经网络(CNN)。
在本章中,您将学习如何使用卷积来检测图像中的特征。然后,您将更深入地根据图像中的特征对图像进行分类。我们将探索图像的增强,以获得更多的特征,并将学习转移到其他人已经学习过的先前存在的特征,然后简要地研究如何使用退出来优化您的模型。
卷积(Convolutions)
卷积只是一个权重过滤器,用于将像素与其相邻像素相乘,以获得该像素的新值。例如,考虑来自Fashion MNIST的踝靴图像和它的像素值,如图3-1所示。

如果我们查看选区中间的像素,我们可以看到它的值是192(回想一下,Fashion MNIST使用像素值从0到255的单色图像)。左上方的像素的值为0,紧靠其上的像素的值为64,依此类推。
如果我们随后在相同的3x3网格中定义过滤器,如下面的原始值所示,我们可以通过为其计算新值来变换该像素。我们通过将网格中每个像素的当前值乘以过滤器网格中相同位置的值,并将总数相加来实现这一点。该总和将是当前像素的新值。然后,我们对图像中的所有像素重复此操作。
因此,在本例中,虽然选区中心像素的当前值为192,但应用过滤器后的新值将为:

这等于577,这将是该像素的新值。在图像的每个像素上重复这个过程将得到一个过滤后的图像。
让我们考虑一下在更复杂的图像上应用过滤器的影响:为便于测试而内置到SciPy中的ascent image。这是一个512 × 512的灰度图像,显示了两个人在爬楼梯。
filter(过滤器,滤波器,滤镜)
使用左侧为负值、右侧为正值、中间为零的过滤器将最终从图像中删除除垂直线以外的大部分信息,如图3-2所示。

同样,对过滤器(滤镜)稍作改动就可以突出水平线,如图3-3所示。

这些例子还表明,图像中的信息量减少了,因此我们可以潜在地学习一组过滤器,这些过滤器将图像简化为特征,而这些特征可以像以前一样与标签匹配。在此之前,我们学习了神经元中用来匹配输入和输出的参数。同样,将输入与输出相匹配的最佳过滤器可以随着时间的推移而学习。
当与池化相结合时,我们可以在保持特征的同时减少图像中的信息量。我们接下来将探讨这一点。
池化(Pooling)
池化是在保持图像内容语义的同时消除图像中像素的过程。最好用可视化来解释。图3-4显示了最大池化(max pooling)的概念。

在这种情况下,将左边的框视为单色图像中的像素。然后,我们将它们分组为2 × 2阵列,因此在这种情况下,16个像素被分组为4个2 × 2阵列。这些被称为池。
然后,我们选择每个组中的最大值,并将它们重新组合成一个新的图像。因此,左边的像素减少了75%(从16个减少到4个),每个池中的最大值构成了新图像。
图3-5显示了图3-2的上升版本,在应用了最大池后,垂直线得到了增强。
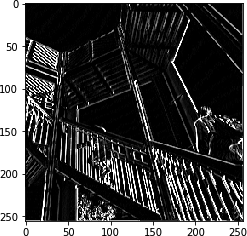
请注意,过滤后的功能不仅得到了维护,还得到进一步增强。此外,图像尺寸从512 × 512变为256 × 256,是原始尺寸的四分之一。
注意:还有其他池化方法,如最小池化(min pooling),从池中获取最小的像素值,以及平均池化,获取整体平均值。
卷积神经网络的实现(Implementing Convolutional Neural Network)
在第二章中,你创建了一个识别Fashion Images的神经网络。为了方便起见,下面是完整的代码:
import tensorflow as tf
data=tf.keras.datasets.fashion_mnist
(training_images,training_labels),(test_images,test_labels)=data.load_data()
training_images=training_images/255
test_images=test_images/255
model=tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=[28,28]),
tf.keras.layers.Dense(128,activation=tf.nn.relu),
tf.keras.layers.Dense(10,activation=tf.nn.softmax)
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(training_images,training_labels,epochs=5)为了将其转换为卷积神经网络,我们在模型定义中简单地使用了卷积层。我们还将添加池层。
为了实现卷积层,您将使用tf.keras.layers.Conv2D类型。这接受层中使用卷积的数量、卷积的大小、激活函数等作为参数。
例如,这里有一个卷积层用作神经网络的输入层:
tf.keras.layers.Conv2D(64,(3,3),activation='relu',input_shape=(28,28,1)),在这种情况下,我们希望该层学习64个卷积(滤镜)。它将随机初始化这些值,随着时间的推移,将学习最适合输入值与其标签相匹配的过滤器值。(3,3)表示过滤器的大小。之前我展示了3 × 3过滤器,这就是我们在这里指定的。这是最常见的过滤器尺寸;您可以根据自己的喜好进行更改,但通常会看到奇数个轴,如5 × 5或7 × 7,这是因为滤镜会从图像边框中移除像素,这一点您将在后面看到。
activation和input_shape参数与之前相同。在这个例子中,我们使用了Fashion MNIST,形状仍然是28 × 28。但是,请注意,因为Conv2D层是为多色图像设计的,所以我们将第三维指定为1,因此我们的输入形状是28 × 28 × 1。彩色图像通常有一个3作为第三个参数,因为它们被存储为R、G和B的值。
以下是如何在神经网络中使用池化层。您通常会在卷积层之后立即执行此操作:
tf.keras.layers.MaxPooling2D(2, 2), 在图3-4的例子中,我们将图像分割成2 × 2个池,并选择每个池中的最大值。此操作可能已被参数化以定义池大小。这些是您可以在这里看到的参数—(2,2)表示我们的池是2 × 2。
现在让我们通过CNN来探索Fashion MNIST的全部代码:
import tensorflow as tf
data=tf.keras.datasets.fashion_mnist
(training_images,training_labels),(test_images,test_labels)=data.load_data()
training_images=training_images.reshape(60000,28,28,1)
training_images=training_images/255
test_images=test_images.reshape(10000,28,28,1)
test_images=test_images/255
model=tf.keras.models.Sequential([
tf.keras.layers.Conv2D(64,(3,3),activation='relu',input_shape=(28,28,1)),
tf.keras.layers.MaxPool2D(2,2),
tf.keras.layers.Conv2D(64,(3,3),activation='relu'),
tf.keras.layers.MaxPool2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128,activation=tf.nn.relu),
tf.keras.layers.Dense(10,activation=tf.nn.softmax)
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(training_images,training_labels,epochs=50)
model.evaluate(test_images,test_labels)
classifications=model.predict(test_images)
i = int(input("请输入训练集图片索引值index=:"))
print(classifications[i])
print(test_labels[i])提前看一下代码运行结果:

这里有几点需要注意。还记得早些时候我说过,图像的输入形状必须符合Conv2D图层的预期,我们将其更新为28 × 28 × 1图像吗?数据也必须进行相应的重新调整。28 × 28是图像中的像素数,1是颜色通道数。通常,您会发现灰度图像为1,彩色图像为3,其中有三个通道(红色、绿色和蓝色),数字表示该颜色的强度。
因此,在对图像进行归一化之前,我们还会对每个阵列进行整形,以获得额外的维度。下面的代码将我们的训练数据集从60,000个图像(每个28 × 28(因此是60,000 × 28 × 28阵列))更改为60,000个图像(每个28 × 28 × 1):
training_images=training_images.reshape(60000,28,28,1)然后我们对测试数据集做同样的事情。
还要注意的是,在最初的深度神经网络(DNN)中,我们在输入到第一个密集层之前,通过一个平坦层运行输入。我们在这里的输入层中丢失了这一点——相反,我们只是指定了输入形状。请注意,在密集层之前,经过卷积和池化后,数据将被展平。
在与第2章所示网络相同的50个批次的相同数据上训练该网络,我们可以看到准确性有很大提高。虽然前一个例子在50个时代的测试集上达到了89%的准确性,但这个例子在24或25个时代的一半左右将达到99%。因此,我们可以看到,向神经网络添加卷积肯定会提高其对图像进行分类的能力。接下来让我们来看看图像通过网络的过程,这样我们就可以更好地理解为什么会这样。
探索卷积网络(Exploring the Convolutional Network)
您可以使用model.summary()命令检查您的模型。当你在我们一直在研究的Fashion MNIST卷积网络上运行它时,你会看到如下所示:

losing pixels(边缘像素损失现象)
让我们先看一下Output Shape列,了解这里发生了什么。我们的第一层将有28 × 28的图像,并对它们应用64个滤镜。但是由于我们的滤镜是3 × 3,图像周围1像素的边框将会丢失,从而将我们的整体信息减少到26 × 26像素。考虑图3 - 6。如果我们把每个方框作为图像中的一个像素,我们可以做的第一个可能的过滤器从第二行和第二列开始。同样的情况也会发生在图的右边和底部。

因此,一个形状为A × B像素的图像在经过3 × 3滤镜时将变成(A - 2) × (B - 2)像素。类似地,一个5 × 5滤波器将使它成为(a - 4) × (B-4),以此类推。因为我们使用的是一个28 × 28的图像和一个3 × 3的过滤器,所以现在我们的输出将是26 × 26。再比如一个512*512的图像和一个9*9的滤镜,会得到(512-8)*(512-8)的输出。
在这之后,池化层是2 × 2,所以图像的大小将在每个轴上减半,然后它将成为(13 × 13)。下一个卷积层将进一步将其缩减为11 × 11,下一个池化(四舍五入)将使图像为5 × 5。
因此,当图像经过两个卷积层时,结果将是许多5 × 5图像。有多少?我们可以在Param # (parameters)列中看到。
每个卷积是一个3 × 3滤波器,加上一个偏置。还记得之前的Dense层吗?每一层都是Y = mX + c,其中m是我们的参数(也就是权重)c是我们的偏差。这是非常相似的,除了因为滤波器是3 × 3有9个参数需要学习。假设我们定义了64个卷积,我们将有640个总的参数(每个卷积有9个参数加上一个偏差,总共10个,总共有64个)。
参数的个数与滤波器直接相关

MaxPooling层不学习任何东西,它们只是减少图像,所以那里没有学习到的参数—因此报告0。
下一个卷积层有64个过滤器,但是每一个都与之前的64个过滤器相乘,每个过滤器有9个参数。我们对每一个新的64个滤波器都有一个偏差,所以我们的参数数应该是(64 × (64 × 9)) + 64,这给了我们36928个网络需要学习的参数。

如果这让人感到困惑,可以尝试将第一层中的卷积数更改为10。您将看到第二层中的参数数量变成了5824,即(64 × (10 × 9)) + 64)。
当我们完成第二次卷积时,我们的图像是5 × 5,我们有64个。如果我们把这个乘起来,我们现在有1600个值,我们将把这些值输入128个神经元的Dense层。每个神经元都有一个权重和一个偏差,我们有128个,所以网络学习的参数数是1600(5 × 5 × 64) × 128 + 128,我们得到204,928个参数。
我们最后的10个神经元Dense层接收了之前128个的输出,所以学习到的参数数将是(128 × 10) + 10,也就是1290。
参数的总数是所有这些参数的总和:243,786。
训练这个网络需要我们学习这243,786个参数的最佳集合,以将输入图像与其标签相匹配。这是一个较慢的过程,因为有更多的参数,但正如我们从结果中看到的,它也建立了一个更准确的模型!
当然,对于这个数据集,我们仍然有图像是28 × 28、单色和居中的限制。接下来,我们将看看如何使用卷积来探索一个更复杂的数据集,该数据集包括马和人的彩色图片,我们将尝试确定一幅图像是否包含其中之一。在这种情况下,主题不会像Fashion MNIST那样总是以图像为中心,所以我们必须依靠卷积来识别特征。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









