







更新一个模板:
这个模板可以不用回溯数据
import java.util.*;
public class Main {
static int[] arr;
static boolean[] b;
static int n = 0;
static int ok;
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int nn = sc.nextInt();
while (nn-- > 0) {
n = sc.nextInt();
arr = new int[n];
b = new boolean[n];
}
}
}
public static void dfs(int one, int k, int bd,int sum) {
if (sum == one) {
bd++;
k = 0;
sum = 0;
}
if (bd == 3) {
ok = 1;
return;
}
for (int i = k; i < n; i++) {
if (b[i] == false & sum + arr[i] <= one) {
b[i] = true;
dfs(one, i, bd,sum +arr[i]);
b[i] = false;
if (ok == 1) {
return;
}
}
}
}
}一
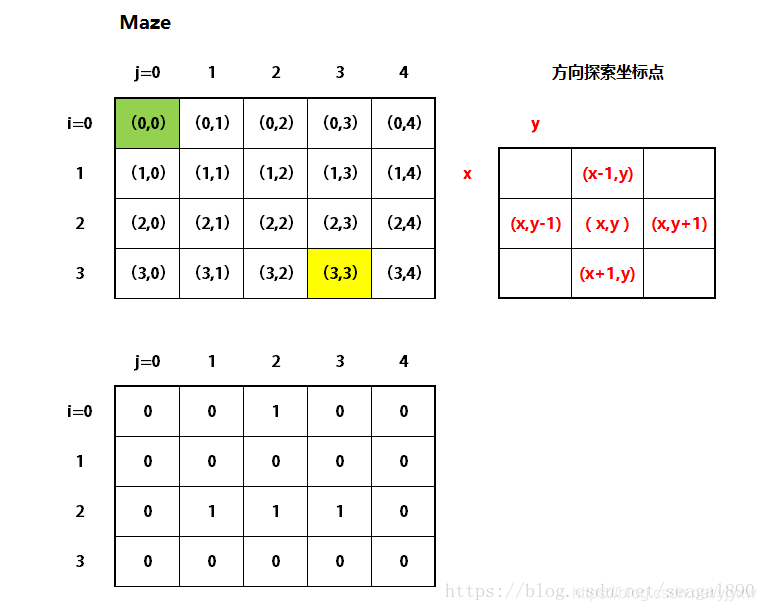
DFS求迷宫路径
DFS(Depth-First-Search,深度优先搜索),顾名思义总是选择深度大的节点去访问,下面的图是一个二叉树,如果从头结点F开始深度优先遍历,若访问了C则下一个节点不可能是E,因为C和E的深度是一样的,违反深度优先原则。深度优先遍历序列不唯一。

例题:
迷宫问题一定一定要标记起点

可以把F想象成零点,C和E想象成上下左右的点,根据题目要求依次搜寻每一条路

从(0,0)开始向下搜索,每一个点又有四个点可以搜索,搜索完就返回到上一个节点,知道所有方案都搜索一遍。
这个题目其实是找从入口(Entrance)到出口(Exit)的可能的路径。矩阵(二维数组)从左上角开始,坐标为(0,0),可以向右走,坐标为(0,1);或者向下走,坐标为(1,0)。对于一般的位置(x,y),可以有4个搜索方向:右(x,y+1),下(x+1,y),左(x,y-1),上(x-1,y)。
根据模板写出:
void dfs()//参数用来表示状态
{
if(到达终点状态)
{
...//根据题意添加
return;
}
if(越界或者是不合法状态)
return;
if(特殊状态)//剪枝
return ;
for(扩展方式)
{
if(扩展方式所达到状态合法)
{
修改操作;//根据题意来添加
标记;
dfs();
(还原标记);
//是否还原标记根据题意
//如果加上(还原标记)就是 回溯法
}
}
}
1.定义dfs函数:
![]()
2.设计返回条件:

3.判断是否到达出口

4.回溯,对于arr[x][y],走过的点设置为障碍,因为每个点都要上下左右搜寻一下,如果搜到来之前那个点,就会返回到之前那个点,成为了死循环,所以要将走过的路设为障碍,搜索完这条路之后将点的值返还!

如果此路不同,还有将path的值返还!
完整代码:
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
public class Main {
static String path = "";
public static void dfs(int x, int y, int[][] arr, int endx, int endy,List<Integer>lists) {
int lengthx = arr.length;
int lengthy = arr[0].length;
//判断是不是到达边界
if (x >= arr.length | y >= arr[0].length) {
return;
}
if (x < 1 | y < 1) {
return;
}
//如果障碍
if (arr[x][y] == 0) {
return;
}
//如果到达了指定位置
if (x == endx && y == endy) {
lists.add(1);
path = path + "(" + x + "," + y + ")";
System.out.println(path);
return;
}
//暂存path
String temp = path;
//加上此时的x,y
path = path + "(" + x + "," + y + ")->";
arr[x][y] = 0;
dfs(x, y - 1, arr, endx, endy,lists);
dfs(x - 1, y, arr, endx, endy,lists);
dfs(x, y + 1, arr, endx, endy,lists);
dfs(x + 1, y, arr, endx, endy,lists);
arr[x][y] = 1;
path = temp;
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int x = sc.nextInt();
int y = sc.nextInt();
int[][] arr = new int[x + 1][y + 1];
for (int i = 1; i < arr.length; i++) {
for (int j = 1; j < arr[0].length; j++) {
arr[i][j] = sc.nextInt();
}
}
List<Integer>lists = new ArrayList<Integer>();
int startx = sc.nextInt();
int starty = sc.nextInt();
int endx = sc.nextInt();
int endy = sc.nextInt();
dfs(startx, starty, arr, endx, endy,lists);
if (lists.size()==0) {
System.out.println("-1");
}
}
}迷宫需要注意的相关问题:
给定一个N*M方格的迷宫,迷宫里有T处障碍,障碍处不可通过。给定起点坐标和终点坐标,问: 每个方格最多经过1次,有多少种从起点坐标到终点坐标的方案。在迷宫中移动有上下左右四种方式,每次只能移动一个方格。数据保证起点上没有障碍。
题目描述
无
输入格式
第一行N、M和T,N为行,M为列,T为障碍总数。第二行起点坐标SX,SY,终点坐标FX,FY。接下来T行,每行为障碍点的坐标。
输出格式
给定起点坐标和终点坐标,问每个方格最多经过1次,从起点坐标到终点坐标的方案总数。
输入输出样例
输入 #1
2 2 1
1 1 2 2
1 2
输出 #1
1简单迷宫问题:
代码实现:
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
public class Main {
static boolean[][] arr = new boolean[1003][1003];
static int dx[] = { 0, 0, 1, -1};
static int dy[] = { 1, -1, 0, 0};
static int n = 0;
static int m = 0;
static int t = 0;
static int x1 = 0;
static int y1 = 0;
static int x2 = 0;
static int y2 = 0;
static int max = 0;
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
n = sc.nextInt();
m = sc.nextInt();
t = sc.nextInt();
x1 = sc.nextInt();
y1 = sc.nextInt();
x2 = sc.nextInt();
y2 = sc.nextInt();
for (int i = 0; i < t; i++) {
int xx = sc.nextInt();
int yy = sc.nextInt();
arr[xx][yy]=true;
}
dfs(0,x1,y1);
System.out.println(max);
}
public static void dfs(int index,int i,int j) {
if(i==x2&j==y2) {
max++;
return;
}
for (int k = 0; k < 4; k++) {
int x = dx[k]+i;
int y = dy[k]+j;
if(x>n|y>m|x<1|y<1) {
continue;
}
if(arr[x][y]==true) {
continue;
}
arr[x][y]=true;
dfs(index+1,x,y);
arr[x][y]=false;
}
}
}评测:

心情可谓是非常难受了,为什么!!!!!!
我的思路明明不是跟第一篇思路一样吗为什么不给过!!!,只不过优化了很多,变成了数组方向!!!
分析:
第一篇与第二篇最大的区别是第一篇将起点标记了。
//因为dfs函数里并没有将起点设为已访问
//所以在后面的访问里,可能访问起点许多次
//所以我的答案可能比标准答案多
纠正:
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
public class Main {
static boolean[][] arr = new boolean[1003][1003];
static int dx[] = { 0, 0, 1, -1};
static int dy[] = { 1, -1, 0, 0};
static int n = 0;
static int m = 0;
static int t = 0;
static int x1 = 0;
static int y1 = 0;
static int x2 = 0;
static int y2 = 0;
static int max = 0;
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
n = sc.nextInt();
m = sc.nextInt();
t = sc.nextInt();
x1 = sc.nextInt();
y1 = sc.nextInt();
x2 = sc.nextInt();
y2 = sc.nextInt();
for (int i = 0; i < t; i++) {
int xx = sc.nextInt();
int yy = sc.nextInt();
arr[xx][yy]=true;
}
arr[x1][y1]=true;//这就是许多人(我)70分的原因
//因为dfs函数里并没有将起点设为已访问
//所以在后面的访问里,可能访问起点许多次
//所以你的答案可能比标准答案多
dfs(0,x1,y1);
System.out.println(max);
}
public static void dfs(int index,int i,int j) {
if(i==x2&j==y2) {
max++;
return;
}
for (int k = 0; k < 4; k++) {
int x = dx[k]+i;
int y = dy[k]+j;
if(x>n|y>m|x<1|y<1) {
continue;
}
if(arr[x][y]==true) {
continue;
}
arr[x][y]=true;
dfs(index+1,x,y);
arr[x][y]=false;
}
}
}重点:不要忘记将起点标记!!!!!
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;public class Main {
static boolean[][] arr = new boolean[1003][1003];
static int dx[] = { 0, 0, 1, -1};
static int dy[] = { 1, -1, 0, 0};
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
for (int i = 0; i < t; i++) {
int xx = sc.nextInt();
int yy = sc.nextInt();
arr[xx][yy]=true;
}
arr[x1][y1]=true;//这就是许多人(我)70分的原因
//因为dfs函数里并没有将起点设为已访问
//所以在后面的访问里,可能访问起点许多次
//所以你的答案可能比标准答案多
dfs(0,x1,y1);
}
类似迷宫题:
题目描述
有一个n*m的棋盘(1<n,m<=400),在某个点上有一个马,要求你计算出马到达棋盘上任意一个点最少要走几步
输入格式
一行四个数据,棋盘的大小和马的坐标
输出格式
一个n*m的矩阵,代表马到达某个点最少要走几步(左对齐,宽5格,不能到达则输出-1)
输入输出样例
输入 #1
3 3 1 1
输出 #1
0 3 2
3 -1 1
2 1 4 这道题做的也是非常悔恨了,感觉为什么自己这么笨,每次做题总感觉离成功差那么一点点,可能这么一点点需要很多的题目来弥补吧!!!
题目思路:
根据跳马的规则,向四面八方跳,写成方向数组,然后搜索每一条路,把没到过的点赋值上到达时的步数。
关键点:
此题关键就是,在赋完值后,可能之后又会遍历到这个点,如果这个点值大于了此时的步数,那么以当前步数再次遍历这个点,如果这个点已经被遍历过并且这个点的值小于当且步数,则略过这个点,找下一个点
疑惑点:
阈值没搞明白咋出来的
import java.util.*;
public class Main {
static int[][] a = new int[1000][1000];
static boolean[][] b = new boolean[1000][1000];
static int[] dx = { 1, 2, 1, 2, -1, -2, -2, -1 };
static int[] dy = { 2, 1, -2, -1, 2, 1, -1, -2 };
static int n = 0;
static int m = 0;
static int x = 0;
static int y = 0;
static int min = 999999;
public static void main(String[] args) {
// TODO Auto-generated method stub
Scanner sc = new Scanner(System.in);
n = sc.nextInt();
m = sc.nextInt();
x = sc.nextInt();
y = sc.nextInt();
b[x][y] = true;
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
if (i == x & j == y) {
continue;
} else {
a[i][j] = -1;
}
}
}
dfs(1, x, y);
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
if (a[i][j] == 0) {
if (i == x & j == y) {
System.out.printf("%-5d", 0);
} else {
System.out.printf("%-5d", -1);
}
} else {
System.out.printf("%-5d", a[i][j]);
}
}
System.out.println();
}
}
public static void dfs(int index, int x1, int y1) {
if (index > 200) {//阈值 150 到200之前
return;
}
for (int k = 0; k < 8; k++) {
int x = dx[k] + x1;
int y = dy[k] + y1;
if (x > n | y > m | x < 1 | y < 1) {
continue;
}
if (b[x][y] == true) {
continue;
}
if (a[x][y] == -1 | a[x][y] > index + 1) {
b[x][y] = true;
a[x][y] = index;
dfs(index + 1, x, y);
b[x][y] = false;
}
}
}
}就差那一个小条件没想到,愁人!哭了
二:
DFS实现全排列(1,2,3)(重复):
全排列其实就是深搜,把每一种情况都要找到,然后输出出来。将其想像成组织图,从1开始往下搜,再从2,再从3,知道搜完全部的路

代码实现:
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int []a = new int[4];
dfs(1,a);
}
public static void dfs(int index,int[]arr) {
if(index == 4) {//临界条件,输出
for (int i = 1; i < arr.length; i++) {
System.out.print(arr[i]+" ");
}
System.out.println();
return;
}
for (int i = 1; i <=3; i++) {
arr[index]=i;
dfs(index+1,arr);//让参数加一,知道调出3个数
}
}
}分析:
此全排列简单,不需要记住每个数走没走过,只要有路口就走,直到所有路口走完

元素可重复,但是每个元素重复的个数有限
全排列带重复元素问题:
题目描述
设R={r1,r2,……,rn}是要进行排列的n个元素。其中元素r1,r2,……,rn可能相同。使设计一个算法,列出R的所有不同排列。
给定n以及待排列的n个元素。计算出这n个元素的所有不同排列。
输入格式
第1行:元素个数n(1<=n<500)
第2行:一行字符串,待排列的n个元素
输出格式
计算出的n个元素的所有不同排列,最后一行是排列总数。
输入输出样例
输入 #1
4
aacc输出 #1
aacc
acac
acca
caac
caca
ccaa
6这题刚拿来做的时候,直接用的其他全排列的方法,就是遍历每一个索引,然后将其标记,然后以该点的节点再次向下搜索,结果全部超时
分析:
分析一下发现,如果按照遍历索引展开搜索。很有可能造成很多很多的重复搜索 ,因为有很多重复的元素,从而导致超时。比如aaaabbcc,如果按照搜因肯定是以 a开头搜索,再以a开头,四次之后再轮到b,就会产生很多很多的重复答案,所以不能按照索引,按照元素 直接搜索 a,b,c

所以我们必须得想出一种方法,就是搜索过的相同节点不去搜索
所以我们不按照索引去搜索,我们按照元素去搜索,原因是按照索引去搜索,会搜索到相同元素,但是按照元素的不同去搜索,搜索不到重复元素
举例:aabbbcc
我们将问题理解为 搜索 a b c ,在一次排列中a必须用两次,b必须用3次,c必须用两次,所以当a用完两次后再次搜索到a就会略过。
搜索a b c ,然后将每一个元素有多少个存放在一个数组当中。
代码分析:
1.
for (int i = 0; i < chars.length; i++) {
a[(int) chars[i] - 97]++;
}计数
2.
for (int j = 0; j < 26; j++) { a b c
if (a[j] > 0) { 判断只有当个数大于0的时候
a[j]--;
String strk = strs.toString();
strs.append(String.valueOf((char) (97 + j)));
dfs(chars, index + 1);
strs = new StringBuffer(strk);
a[j]++; 回溯
}
} 
具体代码实现:
import java.util.*;
public class Main {
static int n = 0;
static boolean[] b = new boolean[1000];
static int arr[][] = new int[1000][1000];
static int num = 0;
static int[] a = new int[1000];
static String str = "";
static StringBuffer strs = new StringBuffer("");
static List<String> lists = new ArrayList<String>();
static List<String> listf = new ArrayList<String>();
public static void main(String[] args) {
// TODO Auto-generated method stub
Scanner sc = new Scanner(System.in);
n = sc.nextInt();
sc.nextLine();
str = sc.nextLine();
char[] chars = str.toCharArray();
for (int i = 0; i < chars.length; i++) {
a[(int) chars[i] - 97]++;
}
Arrays.sort(chars);
dfs(chars, 0);
System.out.println(num);
}
public static void dfs(char[] chars, int index) {
if (index == chars.length) {
System.out.println(strs);
num++;
return;
}
for (int j = 0; j < 26; j++) {
if (a[j] > 0) {
a[j]--;
String strk = strs.toString();
strs.append(String.valueOf((char) (97 + j)));
dfs(chars, index + 1);
strs = new StringBuffer(strk);
a[j]++;
}
}
}
}
无重复:
import java.util.*;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int[] a = new int[4];
boolean[] arr = new boolean[4];// 初始默认值是flase,用来判断是否用过次标记,如果用过就让其等于true
dfs(1, a, arr);
}
public static void dfs(int index, int[] a, boolean[] arr) {
if (index == 4) {//等于临界条件
for (int i = 1; i < a.length; i++) {
System.out.print(a[i] + " ");
}
System.out.println();
return;
}
for (int i = 1; i <= 3; i++) {
if (arr[i] != true) {//如果这个数没被用过
a[index] = i;
arr[i]=true;//这个数被标记上,表示用过
dfs(index + 1, a, arr);
arr[i]=false;//回溯
}
}
}
}
分析:无重复全排列,重点在与走过点选择抛弃,不能再走,对于这个问题,创建一个布尔数组,对走过的点也就是i标记,走过的路标记为true,重点是当用完这个点回来的时候要将其初始化,也就是回溯
举个例子:当经过1时,1从false变成了true,当1 3 2输出后,这个数组的头(1)变成2的,此时以2打头向下选,如果1没有被初始化成flase,还是ture的话,2就直接找到了3,而不是1


原方案:先保存,再输出,超时
public static void dfs(int index) {
if(index==str.length()+1) {
jj++;
for (int i = 1; i < index; i++) {for循环遍历输出
System.out.print(chark[i]);
}
System.out.println();
return;
}
for (int i = 1; i <= 26; i++) {
if (arr[i] > 0) {
chark[index] = (char) (i + 96);将每一个元素保存
arr[i]--;
dfs(index + 1);
arr[i]++;
}
}
}
}
优化:通过
public static void dfs(int index) {
if (index == str.length() + 1) {
jj++;
System.out.println(strs);直接输出
return;
}
for (int i = 1; i <= 26; i++) {
if (arr[i] > 0) {
arr[i]--;
String strk = strs.toString();
strs.append(String.valueOf((char) (i+96)));在搜索中加到字符串中
dfs(index + 1);
strs = new StringBuffer(strk);回溯
arr[i]++;
}
}
}
无重复并且无123 321的:
import java.util.Scanner;
public class Main2 {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int[] arr = new int[5];
for (int i = 1; i < arr.length; i++) {
arr[i] = sc.nextInt();
}
int[] b = new int[5];
int[] a = new int[5];
dfs(arr, 1, b, a);
}
public static void dfs(int[] arr, int index, int[] b, int[] a) {
if (index+1 == arr.length) {
for (int i = 1; i <=3; i++) {
System.out.print(a[i]+" ");
}
System.out.println();
return;
} else {
for (int i = 1; i < arr.length; i++) {
if (i > b[index - 1]) {
a[index] = arr[i];
b[index] = i;
dfs(arr, index + 1, b, a);
}
}
}
}
}
分析:得到此排列关键步骤就是if判断,当前的i值必须大于上一个数的i值,此时就需要一个数组来保存上一个i值,进行比较,才能往下寻找这样就不会有321 和123 这样的反复数组

优化方案:(常用)
for (int i = ii+1; i <= m; i++) {
a[index]=arr[i];
dfs(index+1,i);
}直接将下一次循环的起点定在上一个数之后,会缩短运行时间!
如果我想通过一次深搜,挑出搜索长度在1到n的序列,比如 1,12,123
public static void dfs(int k, int index) {
for (int i = k; i <= n; i++) {从下一个数开始,优化
a[k] = i;找到一个数
for (int j = 1; j <= index; j++) {
System.out.print(a[j] + " ");
}
System.out.println();
dfs(i + 1, index + 1);
}
}实现:长度在1到n的序列全部找出

例题实践:


从题目中我们知道,就是让我们搜索到一种组合让suma和sumb的差值最小。这个时候我们用到这种任意长度序列搜索,因为没告诉我们必须挑几件事干,可能是第一件事和第二件事,也有可能是只有第一件事
代码实现:
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.Queue;
import java.util.Scanner;
public class Hdu1231 {
static int n = 0;
static int v = 0;
static int[][] arr = new int[35][35];
static int a[] = new int[50];
static int suma = 0;
static int sumb = 0;
static int abs = 99999999;
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
n = sc.nextInt();
v = sc.nextInt();
for (int i = 1; i <= n; i++) {
arr[i][1] = sc.nextInt();
arr[i][2] = sc.nextInt();
}
dfs(1);
if (abs == 99999999) {
System.out.println(-1);
} else {
System.out.println(abs);
}
}
public static void dfs(int index) {
if(abs==0) {
return;
}
if (suma + sumb >= v) {每到一个节点判断一次
abs = Math.min(abs, Math.abs(suma - sumb));
}
for (int i = index; i <= n; i++) {
suma += arr[i][1];
sumb += arr[i][2];
dfs(i + 1);
suma -= arr[i][1];
sumb -= arr[i][2];
}
}
}
带有杨辉三角性质的题目:
1.例题:
到了Pizza Hut,爱与愁大神由于不爽,所以存心想坑月落乌啼的钱,ta点了m样菜,每样菜ai元。月落乌啼预计只用n元,于是他让爱与愁大神重新从这m样菜中选r样。爱与愁大神还是想坑钱,于是ta打电话给你,让你编一个程序告诉ta有几种方案可以从m样菜中点取r样菜但是还能超过月落乌啼的预计n元。
输入格式
第1行:三个数 m,r,n。
第2行:m个数,每道菜需要的钱ai,两个数之间有空格。
输出格式
只有一个整数,表示方案总数。
输入输出样例
输入 #1
5 2 8
1 7 2 5 4输出 #1
4题目思路:
就是从m中挑r个数,这r个数的和要大于n,其实就是无反复重复的全排列,但是需要剪枝!
剪枝一:如果当前已经选出的菜的钱数f>nf>nf>n,那么就说明接下来不管怎么选都是可行的,根据组合数的性质(杨辉三角):
![]()
所以根据地推将值预先处理出来:
c[0][0]=1;
for(int i=1;i<=m;i++){
c[i][0]=1;
for(int j=1;j<=i;j++) {
c[i][j]=c[i-1][j]+c[i-1][j-1];
}
}剪枝二:从后面的菜选
for(int i=ii+1;i<=m-r+index;i++) {
sum+=arr[i];
dfs(index+1,i);
sum-=arr[i];
}
代码:
import java.util.*;
public class Main {
static int m = 0;
static int r = 0;
static int n = 0;
static int[]arr = new int[103];
static int[] b = new int[103];
static int num = 0;
static int sum = 0;
static int c[][] = new int[103][103];
public static void main(String[] args) {
// TODO Auto-generated method stub
Scanner sc = new Scanner(System.in);
m = sc.nextInt();
r = sc.nextInt();
n = sc.nextInt();
for (int i = 1; i <= m; i++) {
arr[i]=sc.nextInt();
}
c[0][0]=1;
for(int i=1;i<=m;i++){
c[i][0]=1;
for(int j=1;j<=i;j++) {
c[i][j]=c[i-1][j]+c[i-1][j-1];
}
}
dfs(1,0);
System.out.println(num);
}
public static void dfs(int index,int ii) {
if(index==r+1||sum>n) {
if(sum>n) {
num+=c[m-ii][r-(index-1)];
}
return;
}
for(int i=ii+1;i<=m-r+index;i++) {
sum+=arr[i];
dfs(index+1,i);
sum-=arr[i];
}
}
}
2.


现在给出N和最后一个数sum,求字典序最小的一个序列。
题目思路:
最开始我是找出所有的全排列,看哪个符合条件,得了七十分,超时三个点
想要AC此题,就必须搞懂这个三角形的本质究竟是神马。
大家可以算一算,设一个较小的数,模拟一下。
比如偶设n=5,按照题目中的要求一步步模拟:
a b c d e
a+b b+c c+d d+e
a+2b+c b+2c+d c+2d+e
a+3b+3c+d b+3c+3d+e
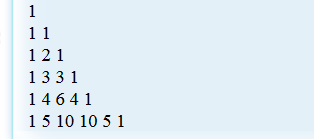
a+4b+6c+4d+e好,最终我们通过一步步的模拟,算出当n=5时,1~5位上对应的权值应该是:
位数 1 2 3 4 5
权值 1 4 6 4 1看到这很激动——这不就是杨辉三角的第五行么!!!
所以结论已经很明显,系数已经给出,每找一个数乘相应系数,找n个数,看是否符合sum,必须先将系数处理出来:
c[1][1] = 1;
for (int i = 2; i <= n; i++) {
c[i][1] = 1;
for (int j = 2; j <= n; j++) {
c[i][j] = c[i - 1][j - 1] + c[i - 1][j];
}
}剪枝:
如果sum大于k直接返回
全部代码:
import java.math.BigDecimal;
import java.util.*;
public class Main2 {
static int n = 0;
static int k = 0;
static int sum = 0;
static boolean[] b = new boolean[20];
static int[] arr = new int[20];
static int[] arrs = new int[20];
static int c[][] = new int[20][20];
static StringBuffer str = new StringBuffer("");
static int kb = 0;
public static void main(String[] args) {
// TODO Auto-generated me 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 218
218











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









