






一、链表理论基础
创建链表节点:
// 单链表
struct ListNode {
int val; // 节点上存储的元素
ListNode *next; // 指向下一个节点的指针
ListNode(int x) : val(x), next(NULL) {} // 节点的构造函数——使用了初始化列表的方式为类内成员变量赋值
};
通过自己定义构造函数初始化节点:
ListNode* head = new ListNode(5);
使用默认构造函数初始化节点:
ListNode* head = new ListNode(); head->val = 5;
所以如果不定义构造函数使用默认构造函数的话,在初始化的时候就不能直接给变量赋值!
二、203.移除链表元素
题目链接:力扣
我一开始的思路如下,但我的代码不对,原因是有2个很严重的问题:
-
我完全没有考虑头节点会不会是待删结点(重点问题)
-
没有把要删除的结点的空间释放掉
-
没有考虑传入的链表是空链表这种极端情况
但是优点就是链表的删除思路记的还蛮清楚的。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* removeElements(ListNode* head, int val)
{
ListNode*point=head;
while(point->next!=NULL)
{
if(point->val==val)
{
point->next=point->next->next;
}
else
{
point=point->next;
}
}
return head;
}
};
正确的代码:
1.不使用虚拟头节点
class Solution {
public:
ListNode* removeElements(ListNode* head, int val) {
// 删除头结点
while (head != NULL && head->val == val) { // 注意这里不是if;而且考虑了传入的链表是空链表的情况
ListNode* tmp = head;
head = head->next;//直接动head指针
delete tmp;
}
// 删除非头结点
ListNode* cur = head;
while (cur != NULL && cur->next!= NULL) {//考虑了传入的链表是空链表的情况
if (cur->next->val == val) {
ListNode* tmp = cur->next;
cur->next = cur->next->next;
delete tmp;
} else {
cur = cur->next;
}
}
return head;
}
};
注意点:
-
删除头节点的情况也需要使用while循环,因为有可能原来的头节点被删除后,新的头节点又是一个需要被删除的值
-
删除头节点的while循环执行结束后,头节点的值就再也不会等于待删结点了(所以不要傻傻地想要是删除非头节点的时候头节点等于待删数值了怎么办;不会出现这种情况!!)
2.使用虚拟头节点(推荐)
class Solution {
public:
ListNode* removeElements(ListNode* head, int val) {
ListNode* dummyHead = new ListNode(0); // 设置一个虚拟头结点
dummyHead->next = head; // 将虚拟头结点指向head,这样方面后面做删除操作
ListNode* cur = dummyHead;
while (cur->next != NULL) {
if(cur->next->val == val) {
ListNode* tmp = cur->next;
cur->next = cur->next->next;
delete tmp;
} else {
cur = cur->next;
}
}
head = dummyHead->next;
delete dummyHead;
return head;
}
};
通过这题,我发现链表的删除思路虽然很简单;但是需要考虑的情况还是较多的,但是使用虚拟节点可以规避很多问题——传入链表是否为空的问题和链表头节点是不是待删结点的问题
所以以后涉及链表全写个虚拟头节点。
三、707.设计链表
题目链接:力扣
我一开始的代码:
class MyLinkedList {
public:
MyLinkedList() {//构造函数
dummyHead->next = NULL;
}
int get(int index) {
MyLinkedList* cur = dummyHead;
for (int i = 0; i <= 0; i++)
{
cur = cur->next;
}
return cur->val;
}
void addAtHead(int val) {
MyLinkedList* Head = new MyLinkedList;
Head->val = val;
Head->next = dummyHead->next;
dummyHead->next = Head;
}
void addAtTail(int val) {
MyLinkedList* search = new MyLinkedList;
MyLinkedList* insert = new MyLinkedList;
insert->val = val;
insert->next = NULL;
search = dummyHead;
while (search->next != NULL) {
search = search->next;
}
search->next = insert;
}
void addAtIndex(int index, int val) {
MyLinkedList* insert = new MyLinkedList;
insert->val = val;
insert->next = NULL;
MyLinkedList* pre = dummyHead;
for (int i = 0; i < index; i++) {
pre = pre->next;
}
insert->next = pre->next;
pre->next = insert;
}
void deleteAtIndex(int index) {
MyLinkedList* pre = dummyHead;
for (int i = 0; i < 0; i++)
{
pre = pre->next;
}
MyLinkedList* del = pre->next;
pre->next = pre->next->next;
del->next = NULL;
delete del;
}
int val;
MyLinkedList* next;
MyLinkedList* dummyHead = new MyLinkedList();
};
int main()
{
MyLinkedList *myLinkedList = new MyLinkedList();
myLinkedList->addAtHead(1);
myLinkedList->addAtTail(3);
myLinkedList->addAtIndex(1, 2); // 链表变为 1->2->3
myLinkedList->get(1); // 返回 2
myLinkedList->deleteAtIndex(1); // 现在,链表变为 1->3
myLinkedList->get(1); // 返回 3
}
不过上述代码会出现堆区的内存异常的错误。
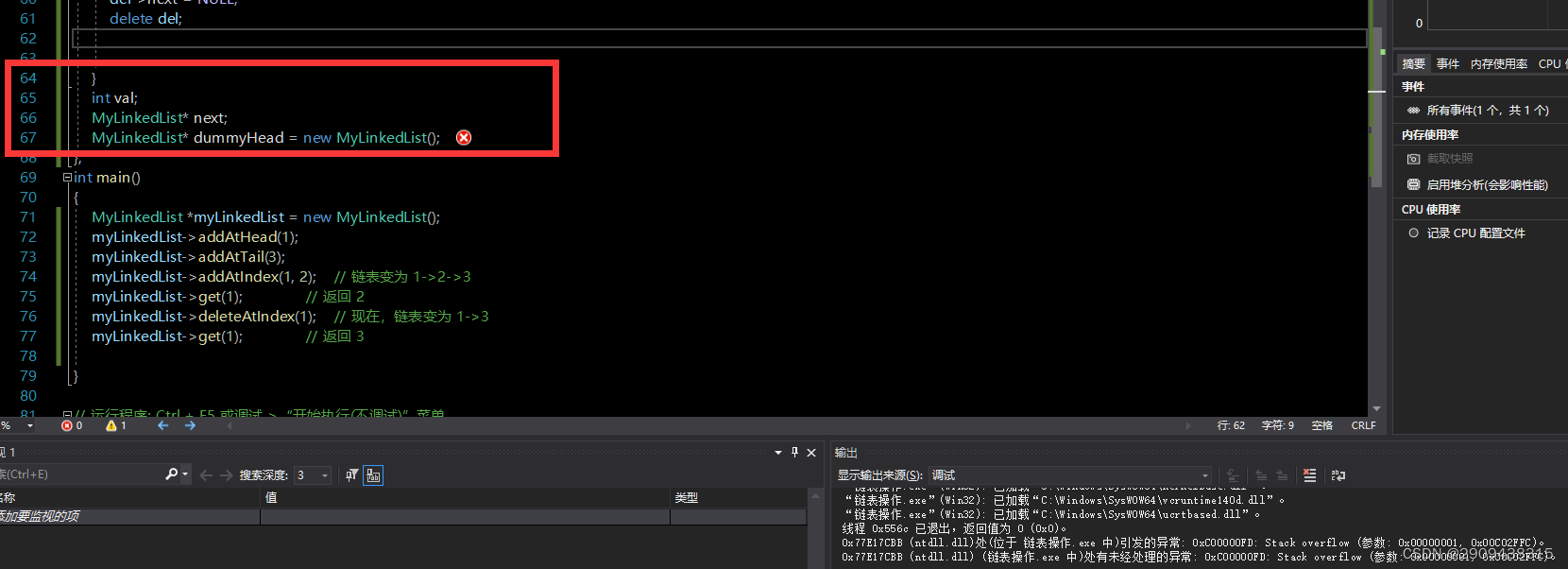
错误的原因:
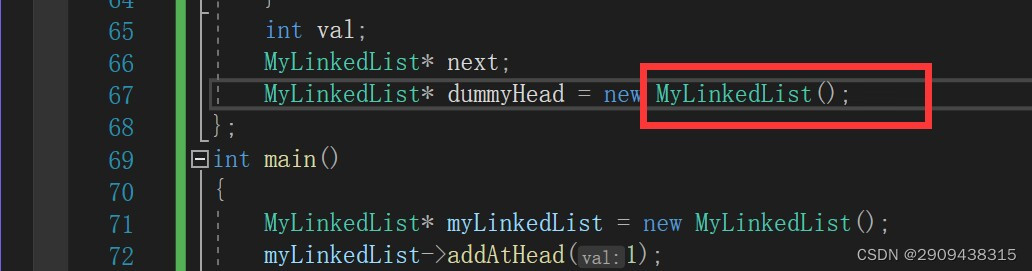
在构造函数调用的时候 调用了这个new——于是这个new 又调用了一个新的构造函数——在构造函数调用的时候 调用了这个new——于是这个new 又调用了一个新的构造函数....
卡子哥的解法里面就是通过把结点和链表的类分开写,如何在链表的初始构造函数里面new了一个虚拟头节点,这样就可以避免我上面的错误。
正确答案:关键——》添加了一个链表节点结构体
值得学习的地方:
-
在类里面还可以定义结构体!(虽然在类内不能再定义类了)
-
善用初始化列表来定义简单的构造函数。
-
写完了addAtHead(int val)函数后,后面的插入函数中需要创建新节点时就可以调用前面的addAtHead(int val)函数
-
c语言中才用NULL,c++中用nullptr
-
在MyLinkedList类中加入了size后,就可以判断需要插入的位置的编号index是否合理,这样子就是代码的逻辑性更严密了
-
使用delete函数删除一个指针指向的内存空间后,要将这个指针指向nullptr
class MyLinkedList {
public:
// 定义链表节点结构体
struct LinkedNode {
int val;
LinkedNode* next;
LinkedNode(int val):val(val), next(nullptr){}
};
// 初始化链表
MyLinkedList() {
_dummyHead = new LinkedNode(0); // 这里定义的头结点 是一个虚拟头结点,而不是真正的链表头结点
_size = 0;
}
// 获取到第index个节点数值,如果index是非法数值直接返回-1, 注意index是从0开始的,第0个节点就是头结点
int get(int index) {
if (index > (_size - 1) || index < 0) {
return -1;
}
LinkedNode* cur = _dummyHead->next;
while(index--){ // 如果--index 就会陷入死循环
cur = cur->next;
}
return cur->val;
}
// 在链表最前面插入一个节点,插入完成后,新插入的节点为链表的新的头结点
void addAtHead(int val) {
LinkedNode* newNode = new LinkedNode(val);
newNode->next = _dummyHead->next;
_dummyHead->next = newNode;
_size++;
}
// 在链表最后面添加一个节点
void addAtTail(int val) {
LinkedNode* newNode = new LinkedNode(val);
LinkedNode* cur = _dummyHead;
while(cur->next != nullptr){
cur = cur->next;
}
cur->next = newNode;
_size++;
}
// 在第index个节点之前插入一个新节点,例如index为0,那么新插入的节点为链表的新头节点。
// 如果index 等于链表的长度,则说明是新插入的节点为链表的尾结点
// 如果index大于链表的长度,则返回空
// 如果index小于0,则在头部插入节点
void addAtIndex(int index, int val) {
if(index > _size) return;
if(index < 0) index = 0;
LinkedNode* newNode = new LinkedNode(val);
LinkedNode* cur = _dummyHead;
while(index--) {
cur = cur->next;
}
newNode->next = cur->next;
cur->next = newNode;
_size++;
}
// 删除第index个节点,如果index 大于等于或者小于链表的长度,直接return,注意index是从0开始的
void deleteAtIndex(int index) {
if (index >= _size || index < 0) {
return;
}
LinkedNode* cur = _dummyHead;
while(index--) {
cur = cur ->next;
}
LinkedNode* tmp = cur->next;
cur->next = cur->next->next;
delete tmp;
//delete命令指示释放了tmp指针原本所指的那部分内存,
//被delete后的指针tmp的值(地址)并非就是NULL,而是随机值。也就是被delete后,
//如果不再加上一句tmp=nullptr,tmp会成为乱指的野指针
//如果之后的程序不小心使用了tmp,会指向难以预想的内存空间
tmp=nullptr;
_size--;
}
// 打印链表
void printLinkedList() {
LinkedNode* cur = _dummyHead;
while (cur->next != nullptr) {
cout << cur->next->val << " ";
cur = cur->next;
}
cout << endl;
}
private:
int _size;
LinkedNode* _dummyHead;
};
四、206.反转链表
2种办法:双指针、递归
一、双指针写法
注意点:
-
cur指针、pre指针的初始化、temp指针——cur初始化为head;pre初始化为NULL;temp指向cur->next
-
遍历结束的条件
-
先改变pre的值,再改变cur的值。
class Solution {
public:
ListNode* reverseList(ListNode* head) {
ListNode* temp; // 保存cur的下一个节点
ListNode* cur = head;
ListNode* pre = NULL;//翻转前,指向cur指针指向的结点的前一个结点 ;翻转后,指向cur指针指向的结点的下一个节点
while(cur) {
temp = cur->next; // 保存一下 cur的下一个节点,因为接下来要改变cur->next
cur->next = pre; // 翻转操作
// 更新pre 和 cur指针
pre = cur;
cur = temp;
}
return pre;
}
};
双指针的思路:因为链表是单向的,所以必须从头节点开始,那么要使得指针指向反过来,就只能将一前一后的两个链表结点的地址都记录下来。
二、递归
递归的写法就是循着双指针的写法写出来的,递归的代码和双指针的代码就是一一对应的:
关键——》在双指针中结束一层循环的时候==递归中要进行下一次递归
class Solution {
public:
ListNode* reverse(ListNode* pre,ListNode* cur){
if(cur == NULL) return pre;
ListNode* temp = cur->next;
cur->next = pre;
// 可以和双指针法的代码进行对比,如下递归的写法,其实就是做了这两步
// pre = cur;
// cur = temp;
return reverse(cur,temp);
}
ListNode* reverseList(ListNode* head) {
// 和双指针法初始化是一样的逻辑
// ListNode* cur = head;
// ListNode* pre = NULL;
return reverse(NULL, head);
}
};
三、从后往前翻转
面的递归写法和双指针法实质上都是从前往后翻转指针指向,其实还有另外一种与双指针法不同思路的递归写法:从后往前翻转指针指向
class Solution {
public:
ListNode* reverseList(ListNode* head) {
// 边缘条件判断
if(head == NULL) return NULL;
if (head->next == NULL) return head;
// 递归调用,翻转第二个节点开始往后的链表
ListNode *last = reverseList(head->next);
// 翻转头节点与第二个节点的指向
head->next->next = head;
// 此时的 head 节点为尾节点,next 需要指向 NULL
head->next = NULL;
return last;
}
};
图片整理递归思路:
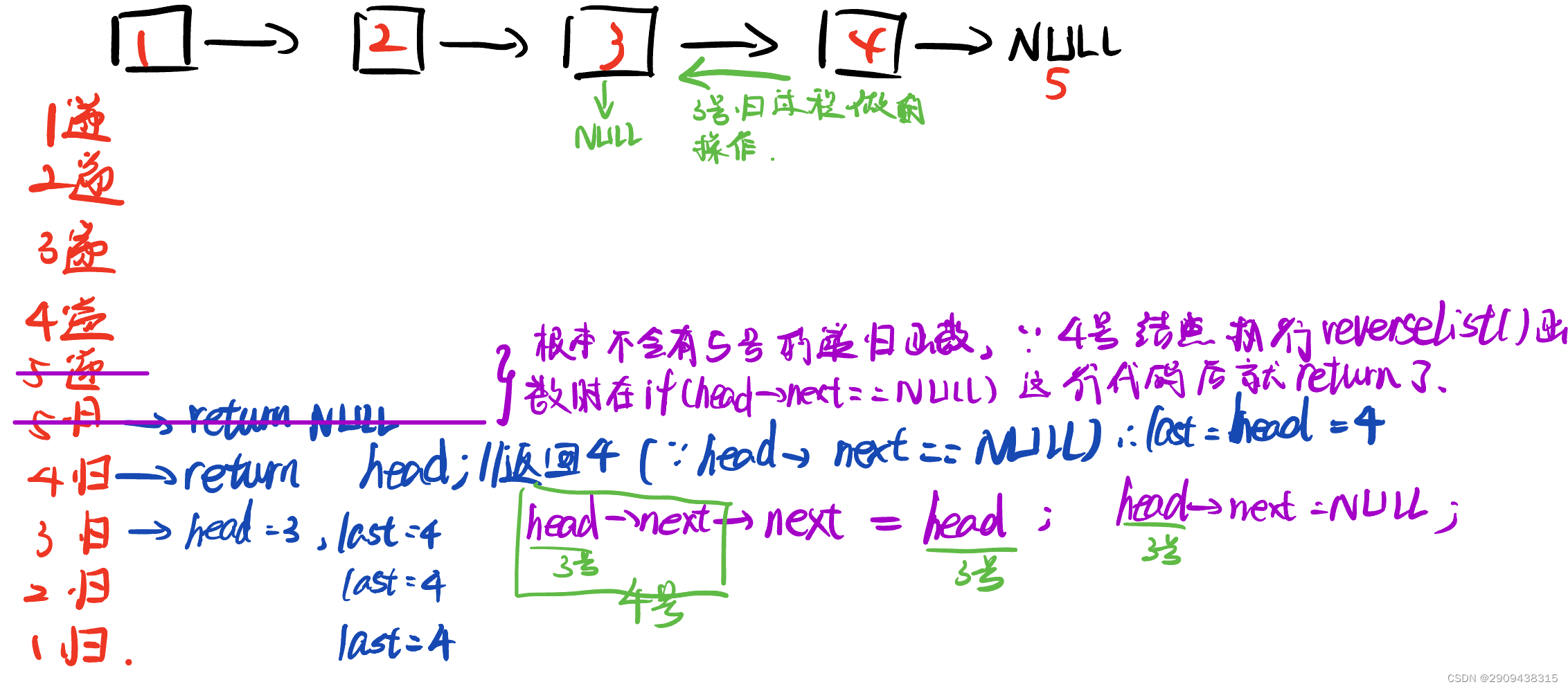
这种方法需要对递归的递过程和归过程有很深的理解才能写出这种办法:
-
递过程找到链表的最后一个结点
-
归过程逆向处理链表的每一个结点。















 467
467











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









