







使用Linq提供的扩展方法Distinct可以去除序列中的重复元素。
该方法具有以下两种重载形式:
(1)public static IEnumerable<TSource> Distinct<TSource>(this IEnumerable<TSource> source) (重载1)
通过使用默认的相等比较器对值进行比较并返回序列中的非重复元素。
(2)publicstatic IQueryable<TSource> Distinct<TSource>(this IQueryable<TSource> source,IEqualityComparer<TSource> comparer) (重载2)
通过使用自定义的相等比较器对值进行比较返回序列中的非重复元素。 自定义的相等比较器需要实现接口IEqualityComparer<T>。
使用默认的相等比较器时,比较器是如何工作的?
对于值类型,比较器通过比较对象的值来确认对象是否相等;
对于引用类型,比较器通过比较对象的引用来确认对象是否相等;
而对于字符串类型,尽管是引用类型,但比较器同样通过比较对象的值来确认对象是否相等。
下面给出两个使用Distinct方法去除序列重复元素的实例,其中,例1采用默认的比较器来工作,例2采用自定义的比较器工作。
例1 使用Distinct方法去除序列中的同名元素。
List<string> nameList = new List<string> { "张三", "李四", "张三", "张三", "李四"};
Console.WriteLine("原始序列:");
foreach (var s in nameList)
{
Console.WriteLine("Name = {0}", s);
}
var newNameList = nameList.Distinct();
Console.WriteLine("去重操作后的序列:");
foreach (var s in newNameList)
{
Console.WriteLine("Name = {0}", s);
}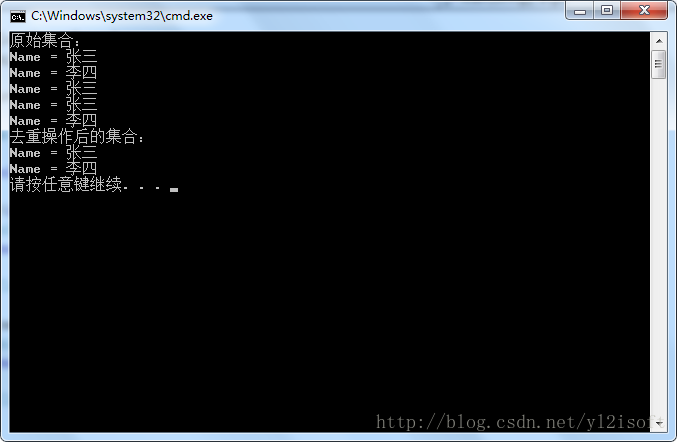
例1中采用Distinct方法的重载1来对序列进行去重操作,即使用默认的比较器来工作,同时,序列的元素类型为字符串,所以会通过比较字符串的值来确认字符串是否相等,这样一来,在返回的结果中,重复的“张三”与“李四”将会被去除。
例2-1 使用Distinct方法去除序列中的重复的学生元素。
public class Student
{
public string StudentName { get; set; }
public int StudentCode { get; set; }
}
List<Student> studentList = new List<Student>();
studentList.Add(new Student() { StudentName = "张三", StudentCode = 1 });
studentList.Add(new Student() { StudentName = "李四", StudentCode = 1 });
studentList.Add(new Student() { StudentName = "张三", StudentCode = 1 });
studentList.Add(new Student() { StudentName = "张三", StudentCode = 2 });
studentList.Add(new Student() { StudentName = "李四", StudentCode = 1 });
Console.WriteLine("原始集合:");
foreach (var s in studentList)
{
Console.WriteLine("StudentName = {0}, StudentCode = {1}", s.StudentName, s.StudentCode);
}
var newStudentList = studentList.Distinct();
Console.WriteLine("去重操作后的集合:");
foreach (var s in newStudentList)
{
Console.WriteLine("StudentName = {0}, StudentCode = {1}", s.StudentName, s.StudentCode);
}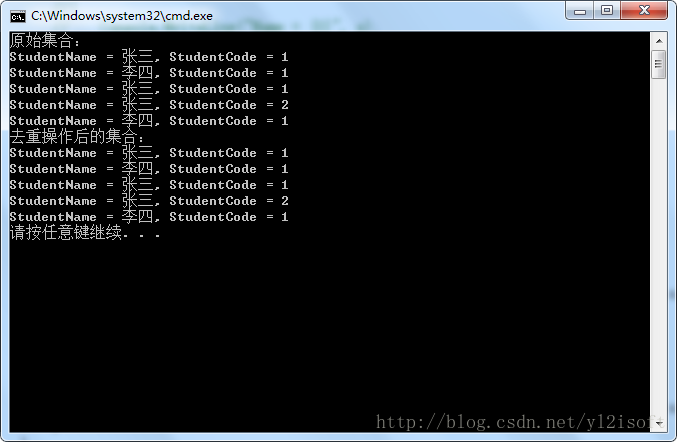
从结果可以看出,对序列执行Distinct方法并没有去除序列中的重复元素。因为例2-1采用的仍是Distinct方法的重载1来对序列进行去重操作,那么将会使用默认的比较器来工作,默认的比较器在比较引用类型时是通过比较对象的引用来确认对象是否相等,很显然,实例序列中的各个元素的引用是不相等的,因此比较器会认为,序列中的全部元素都不相同,因此不会进行去重操作。
例2-2 使用Distinct方法去除序列中的重复的学生元素。(该自定义的比较器出场了吧)
public class StudentComparer : IEqualityComparer<Student>
{
public bool Equals(Student x, Student y)
{
if (Object.ReferenceEquals(x, y)) return true;
if (Object.ReferenceEquals(x, null) || Object.ReferenceEquals(y, null))
return false;
return x.StudentName == y.StudentName && x.StudentCode == y.StudentCode;
}
public int GetHashCode(Student student)
{
if (Object.ReferenceEquals(student, null)) return 0;
int hashStudentName = student.StudentName == null ? 0 : student.StudentName.GetHashCode();
int hashStudentCode = student.StudentCode.GetHashCode();
return hashStudentName ^ hashStudentCode;
}
}
Console.WriteLine("原始集合:");
foreach (var s in studentList)
{
Console.WriteLine("StudentName = {0}, StudentCode = {1}", s.StudentName, s.StudentCode);
}
var newStudentList = studentList.Distinct(new StudentComparer());//将自定义的比较器作为参数传入
Console.WriteLine("去重操作后的集合:");
foreach (var s in newStudentList)
{
Console.WriteLine("StudentName = {0}, StudentCode = {1}", s.StudentName, s.StudentCode);
}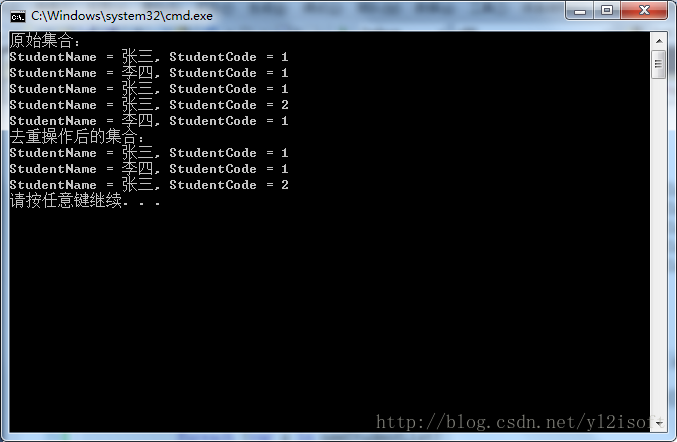
从结果可以看出,此次成功去除了序列中的重复记录,功劳归功于我们自定义的比较器,因为自定义的比较器不再通过比较引用来确认对象是否相等了,而是通过比较Student对象的StudentName与StudentCode的值来确认对象是否相等,很显然,只要着两个字段的值相等将会被认为是重复记录而被去除,所以得到了我们想要的结果。
扩展阅读:

















 786
786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









