










让我们比较一下数据仓库、数据湖和数据流。他们是现代数据堆栈中的朋友、敌人还是敌人?
数据仓库、数据湖和数据流的概念和架构是解决业务问题的补充。存储静态数据以进行报告和分析与为实时工作负载持续处理动态数据相比,需要不同的功能和 SLA。存在许多开源框架、商业产品和 SaaS 云服务。不幸的是,底层技术经常被误解,过度使用于单一和不灵活的架构,并被供应商推向错误的用例。
数据的价值:事务性与分析性工作负载
过去十年提供了许多关于数据成为新石油的文章、博客和演示文稿。今天,没有人质疑数据驱动的业务流程会改变世界并支持跨行业的创新。
数据驱动的业务流程需要实时数据处理和批处理。考虑以下跨应用程序、域和组织的事件流:
事件是业务信息或技术信息。事件无时无刻不在发生。现实世界中的业务流程需要各种事件的关联。
事件有多重要?
事件的严重性决定了结果。潜在影响可能是增加收入、降低风险、降低成本或改善客户体验。
- 业务交易:理想情况下,零停机和零数据丢失。示例:付款需要只处理一次。
- 关键分析:理想情况下,零停机时间。单个传感器事件的数据丢失可能没问题。对事件聚合发出警报更为关键。示例:持续监控 IoT 传感器数据和(预测性)机器故障警报。
- 非关键分析:停机和数据丢失不好,但不会扼杀整个业务。这是一场意外,但不是一场灾难。示例:用于预测需求的报告和商业智能。
何时处理事件
实时通常意味着毫秒或秒内的端到端处理。如果您不需要实时决策,批处理(即,在几分钟、几小时、几天之后)或按需(即,请求-答复)就足够了。
- 业务交易通常是实时的:像付款这样的交易通常需要实时处理(例如,在客户离开商店之前;在您发货之前;在您离开网约车之前)。
- 关键分析通常是实时的:关键分析通常需要实时处理(例如,在欺诈发生之前检测;在机器故障之前预测机器故障;在客户离开商店之前向其追加销售)。
- 非关键分析通常不是实时的:在历史数据中发现洞察力通常是使用复杂 SQL 查询、map-reduce 或复杂算法(例如,报告;使用机器学习算法进行模型训练;预测)等范例在批处理过程中完成的)。
通过这些关于处理事件的基础知识,让我们了解为什么将所有事件存储在单个中央数据湖中并不是解决所有问题的方法。
通过权力下放和同类最佳的灵活性
传统的数据仓库和数据湖方法是将来自所有来源的所有数据摄取到中央存储系统中,以实现集中的数据所有权。天空(和您的预算)是当前大数据和云技术的极限。
然而,领域驱动设计、微服务和数据网格等架构概念表明,分散所有权是现代企业架构的正确选择。
不用担心。 数据仓库和数据湖并未消亡,但在数据驱动的世界中比以往任何时候都更加重要。两者都适用于许多用例。即使在其中一个领域中,大型组织也不使用单个数据仓库或数据湖。为工作(在您的领域或业务部门)选择正确的工具是解决业务问题的最佳方式。
人们对用于批处理 ETL、机器学习甚至数据仓库的 Databricks 感到满意是有充分理由的,但在某些用例中仍然更喜欢 AWS RDS(完全托管的 PostgreSQL)这样的轻量级云 SQL 数据库。
快乐的 Splunk 用户也有充分的理由将一些数据引入 Elasticsearch。以及为什么 Cribl 在这个领域也越来越受到关注。
一些项目利用 Apache Kafka 作为数据库是有充分理由的。在 Kafka 中长期存储数据仅对某些特定用例(如压缩主题、键/值查询和流分析)有意义。Kafka 不会取代其他数据库或数据湖。
为分散数据所有权的工作选择合适的工具!
考虑到这一点,让我们探索现代数据仓库的用例和附加值(以及它与数据湖和新的嗡嗡声 - 湖库的关系)。
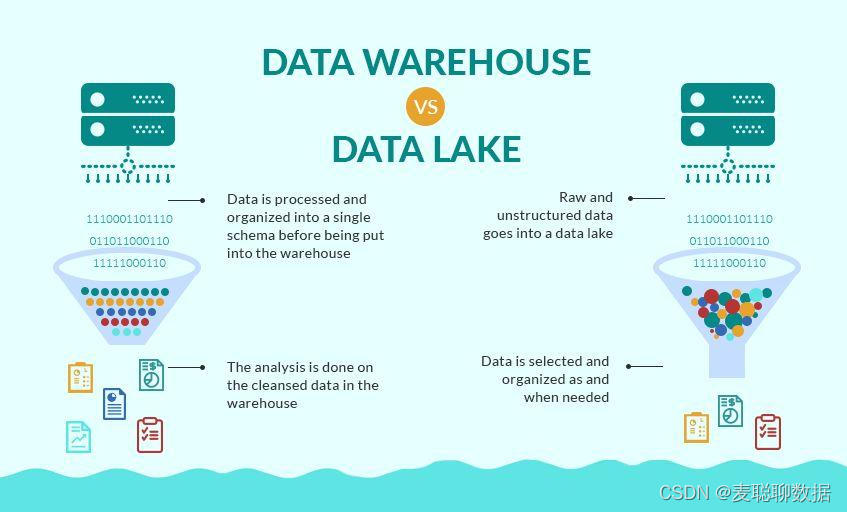
数据仓库:静态数据的报告和商业智能
数据仓库 (DWH) 提供报告和数据分析功能。它被认为是商业智能的核心组成部分。
静态数据用例
无论您使用的是称为数据仓库、数据湖还是湖屋的产品。数据以静态方式存储以供进一步处理:
- 报告和商业智能:报告、统计数据和关键数据的快速灵活可用性,例如,识别市场和服务提供之间的相关性
- 数据工程:整合来自不同结构和分布式数据集的数据,以识别数据之间的隐藏关系
- 大数据分析和人工智能/机器学习:源数据的全局视图,从而进行总体评估,以找到未知的见解,以改进业务流程和相互关系。
有读者可能会说:只有第一个是数据仓库的用例,另外两个是数据湖或湖屋!这一切都取决于定义。
数据仓库架构
DWH 是来自不同来源的综合数据的中央存储库。它们将历史数据存储在一个存储系统中。数据以静态方式存储,即保存以供以后分析和处理。业务用户分析数据以找到见解。
数据是从操作系统上传的,例如物联网数据、ERP、CRM 和许多其他应用程序。数据清理和数据质量保证是 DWH 管道中的关键部分。提取、转换、加载 (ETL) 或提取、加载、转换 (ELT) 是构建数据仓库系统的两种主要方法。数据集市有助于专注于数据仓库生态系统中的单个主题或业务线。
数据仓库与数据湖和Lakehouse的关系
数据仓库的重点是使用结构化数据进行报告和商业智能。相反,数据湖是存储和处理原始大数据的同义词。过去,数据湖是使用 Hadoop、HDFS 和 Hive 等技术构建的。如今,数据仓库和数据湖已合并为一个解决方案。云原生 DWH 支持大数据。同样,云原生数据湖需要使用传统工具的商业智能。
Databricks:从数据湖到数据仓库的演变
几乎所有供应商都是如此。例如,看看领先的大数据供应商之一的历史:Databricks,以 Apache Spark 公司而闻名。该公司最初是大数据批处理平台 Apache Spark 背后的商业供应商。该平台通过使用微批处理的(一些)实时工作负载得到了增强。几个里程碑之后,Databricks 今天是一家完全不同的公司,专注于云、数据分析和数据仓库。Databricks 的策略从:
- 开源到云端
- 自管理软件到完全管理的无服务器产品
- 专注于 Apache Spark 到 AI/机器学习以及后来添加的数据仓库功能
- 从单一产品到围绕数据分析的庞大产品组合,包括标准化数据格式(“Delta Lake”)、治理、ETL 工具(Delta Live Tables)等,
Databricks 和 AWS 等供应商还为这种数据湖、数据仓库、商业智能和实时功能的合并创造了一个新的流行语:The Lakehouse。
Lakehouse(有时称为 Data Lakehouse) 并不是什么新鲜事。它结合了不同平台的特点。我写了一篇关于 使用 Kafka 和 AWS 分析平台在 AWS 上构建云原生无服务器湖库的文章。
Snowflake:从数据仓库到数据湖的演变
雪花从另一个方向传来。它是所有主要云上可用的第一个真正的云原生数据仓库。如今,Snowflake 提供了超出传统商业智能范围的更多功能。例如,数据和软件工程师具有通过其他技术和 API 与 Snowflake 的数据湖交互的功能。数据工程师需要 Python 接口来分析历史数据,而软件工程师更喜欢任何规模的实时数据摄取和分析。
无论您是构建数据仓库、数据湖还是湖库:关键在于了解动态数据和静态数据之间的区别,以便为您的解决方案找到合适的企业架构和组件。以下部分探讨了为什么一个好的数据仓库架构需要两者以及它们如何很好地相互补充。
事务性实时工作负载不应在数据仓库或数据湖中运行!由于不同的正常运行时间 SLA、监管和合规法律以及延迟要求,关注点分离至关重要。
数据流:用动态数据补充现代数据仓库
让我们澄清一下:数据流与数据摄取不同!您可以使用 Apache Kafka 等数据流技术将数据摄取到数据仓库或数据湖中。大多数公司都这样做。精致而有价值。
但是:像 Apache Kafka 这样的数据流平台不仅仅是一个摄取层。因此,它与 AWS Kinesis、Google Pub/Sub 和类似工具等摄取引擎有很大不同。
数据流与数据摄取不同
数据流 提供消息传递、持久性、集成和处理能力。每秒数百万条消息的高可扩展性、高可用性(包括向后兼容和任务关键型工作负载的滚动升级)以及云原生功能是一些内置功能。
数据流的事实标准是 Apache Kafka。因此,我主要将 Kafka 用于数据流架构和用例。
使用 Apache Kafka 进行数据流式处理的事务和分析用例
数据流的不同用例的数量几乎是无穷无尽的。请记住,数据流不仅仅是用于数据摄取的消息队列!虽然将数据摄取到数据湖中是第一个突出的用例,但这意味着实际 Kafka 部署的比例不到 5%。业务应用程序、流式 ETL 中间件、实时分析和边缘/混合场景是其他一些示例:
Kafka的持久层为敏捷和真正解耦的应用程序提供分散的微服务架构。
请记住, Apache Kafka 支持事务和分析工作负载。两者通常具有非常不同的正常运行时间、延迟和数据丢失 SLA。查看这篇文章和幻灯片,了解有关 由 Apache Kafka 提供支持的跨行业数据流用例的更多信息。
不要(尝试)将数据仓库或数据湖用于数据流
本文探讨了静态数据和动态数据之间的区别:
- 数据仓库非常适合报告和商业智能。
- 数据湖非常适合大数据分析和人工智能/机器学习。
- 数据流支持实时用例。
- 围绕微服务和数据网格构建现代数据堆栈需要 一个分散的、灵活的企业架构 。
这些技术都不是灵丹妙药。为问题选择正确的工具。单体架构并不能解决当今的业务问题。仅以静态方式存储所有数据无助于满足实时用例的需求。
Kappa 架构是一种用于实时和批处理工作负载的现代方法,可以避免使用 Lambda 架构的更复杂的基础架构。数据流补充了数据仓库和数据湖。如果您选择合适的供应商(通常是战略合作伙伴,而不是某些人认为的竞争对手),这些系统之间的连接是开箱即用的。
您今天如何结合数据仓库和数据流?Kafka 只是您进入数据湖的摄取层吗?您是否已经将数据流用于其他实时用例?或者 Kafka 是否已经是企业架构中用于解耦微服务和数据网格的战略组件?















 520
520











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









