






如下图的错误解决方法
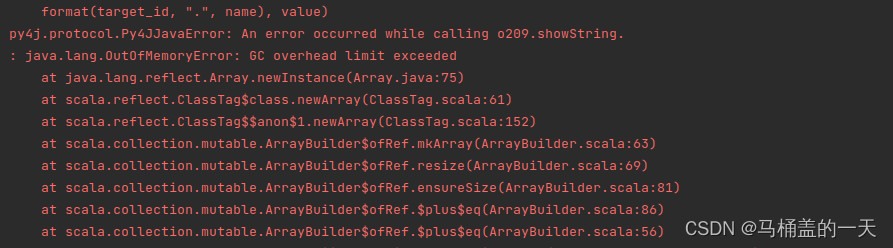
出现该错误的原因是因为迭代处理的数据量太大,jvm的自动回收垃圾机制不完善导致的,比如我在这里对2千万的数据迭代处理24次,数据就报错了。![]()
![]()
解决方法一:可以利用isin函数代替24次迭代过程
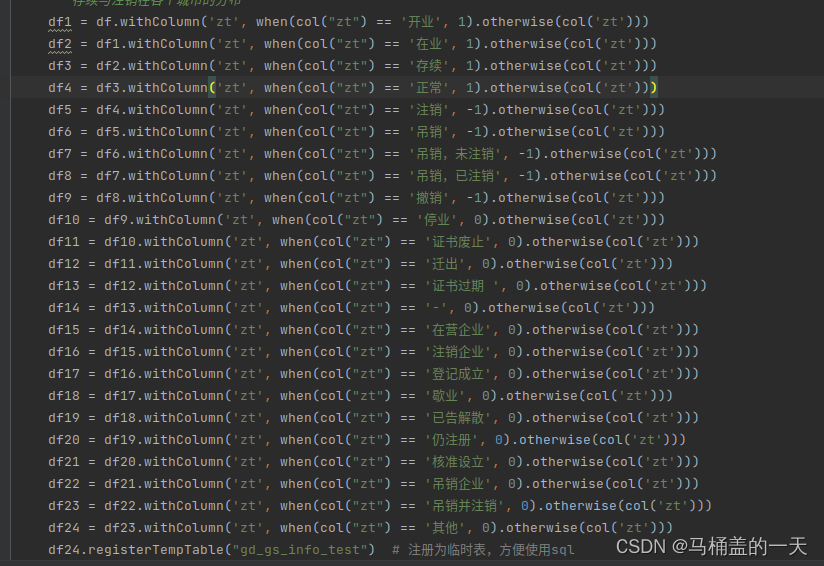
改为

在这里提一句
df1 = df.withColumn('zt', when(col("zt") == '开业', 1).otherwise(col('zt')))
这一句的作用是把zt列,值为开业的改为1
解决方法二:利用spark的缓存机制df.persist()函数
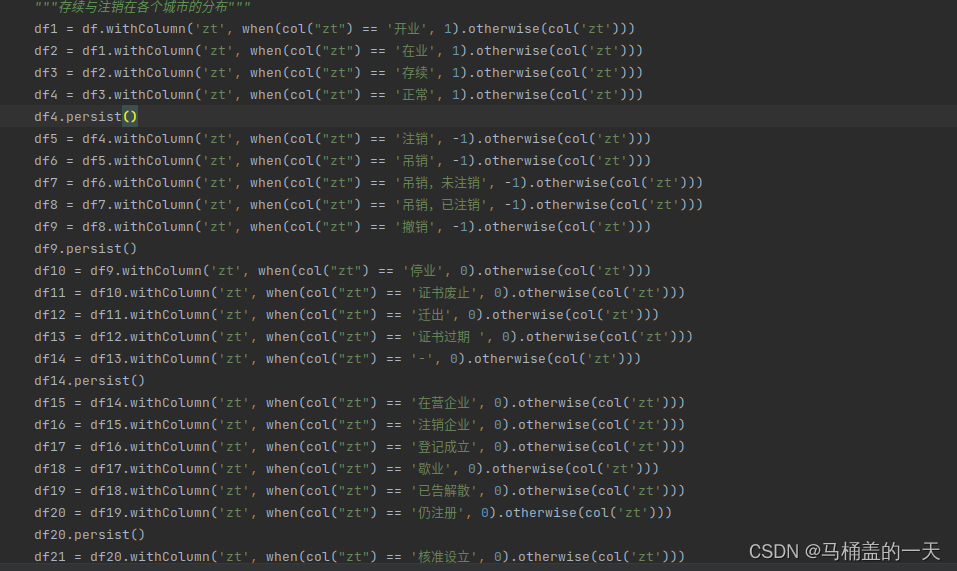
分别在df4,df9,df14,df20利用缓存机制把数据先存储到硬盘上释放 内存空间,方便我们执行下面迭代程序,解决jvm内存不足问题。(在这里提一句话可以根据需求多设几处perrsist,用时间换取空间)
最后程序跑完可以释放缓存
df4.unpersist()
df9.unpersist()
df14.unpersist()
df20.unpersist()
解决问题完成。
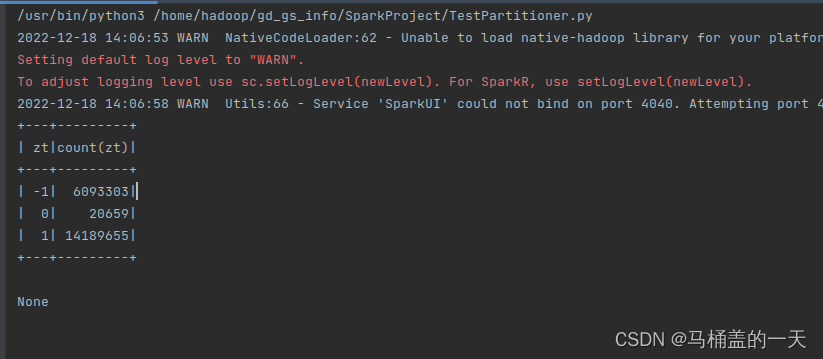
df.persist()函数还可以大大节省运行时间,如在多次需要运行一个数据集情况下,这里属于空间换时间















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









