








大数据产业创新服务媒体
——聚焦数据 · 改变商业
在大模型这个领域,我们看到两种截然不同的发展思路,一种是做商业闭源大模型,在进行技术产品提升的同时,也在进行商业化落地;另外一种,就是开源大模型。
那么,这两种发展路径哪一个是对的,哪一个更可能成功?

有哪些不错的开源大模型?
笔者基于公开资料,搜集了一些目前开源的大模型。
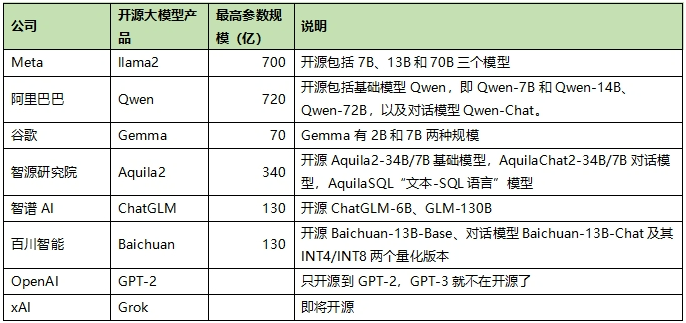
需要指出的是,这不是一份完整的名单,实际开源的大模型还有很多。但是,其实很多大模型都是开源“玩玩”而已,意义并不大。为什么这么说呢?不少开源的大模型,本身能力并不强,自己做闭源商用的可能性也不大。
真正有实力的开源大模型,才能是市场的一个“鲶鱼”,比如Meta开源的llama系列,现在已经成为开源大模型的“金标准”,或者说开源大模型领域的关键基础设施。国内在不到一年时间出现“百模大战”的盛况,一个重要原因,就是llama。所以,有一个玩笑话,“llama每更新一代,国内大模型的基础设施就升级一代。”
当然,除了llama,越来越多公司开始加入开源的队伍。比如国内阿里巴巴开源的Qwen系列,最新已经开源到720亿参数的版本了,至少从纸面战力上追平了llama2。
最新的消息是,马斯克也即将加入开源大模型的行业,其Grok即将开源。
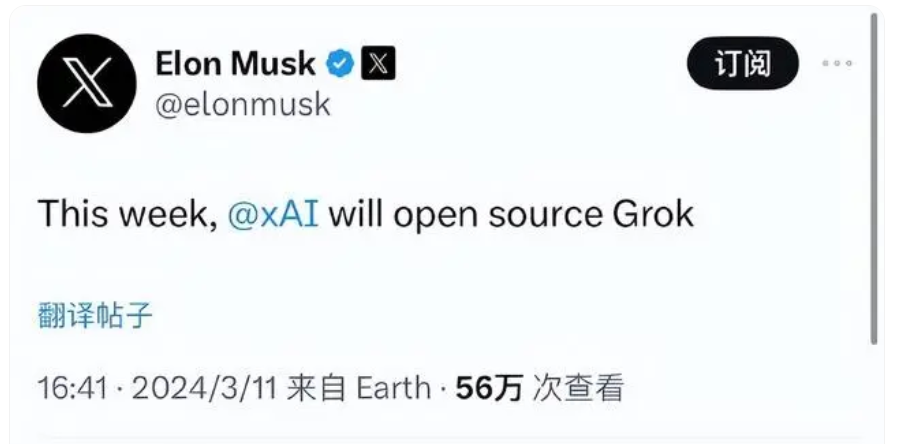
可以说,马斯克对大模型开源有着异乎常人的执念。某种意义上,是他促成了OpenAI的成立,这个公司名字就是他起的。这个组织成立的宗旨,就在名字上清清楚楚的写着了。结果,创业未半,OpenAI的“Open”变成“Close”了。这我“马某人”能忍?
为此,马斯克没少怼OpenAI,并且画风越来越“抽象”。
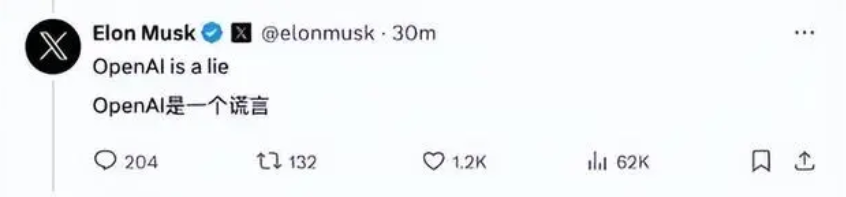
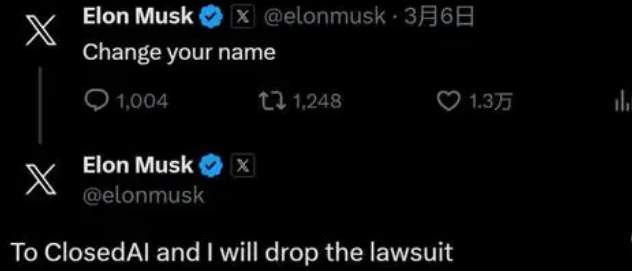

其实,OpenAI最开始是坚定的开源主义者,但却只开源到GPT-2,当研发出GPT-3,出现智能涌现之后,他们就闭源了。他们自己给出的说辞是,AGI这条路要很多钱,只有建立商业闭环,才能支撑OpenAI走下去。
最近,OpenAI放出来一个观点,大致意思是:OpenAI的开源并不是要开放技术代码,只要大部分人能用上他们开发出的智能产品就也算开源了。(你忽悠谁呢?按这个说法,微信也开源了,所有互联网APP都开源了,因为大家都可以用。)
为什么开源?
OpenAI背弃他们当初开源分布式AI的初衷,最终成为一个商业公司,这虽然令人遗憾,但也让我们思考一个问题——非盈利组织的开源大模型真的走不通么?
我们发现一个有意思的现象,就是现在比较知名的开源大模型,都是商业公司在做,而且他们是闭源和开源两条腿走路。非商业机构开源出来的大模型,最后都慢慢走向落寞了。为什么会出现这个现象?
评价一个开源大模型的关键指标,是其是否能够持续开源出更强大的模型。
从这个角度来说,非盈利机构是没办法持续迭代开源大模型的。更好、更大参数规模的大模型,往往意味着更多的资金投入,大模型的更新维护也需要很多钱,这是非盈利机构无法承受的。
也就是说,接下来,不仅最好的闭源大模型是商用公司做出来,就是最好、能够持续迭代的开源大模型,大概率也是商用公司在维护,这是我们不得不面对的一个现实。
既然出现这样一个现象,那我们就来分析一下其内部的逻辑:为什么商业公司要推出开源的大模型,跟他们自己的商用大模型业务会起冲突么?
在商业社会,一直流传这样一句话,“一流的企业做标准,二流的企业做品牌,三流的企业做产品”。能够做成行业标准,构建一个产业生态,不仅能够做大企业规模,还能一定程度上保证基业长青。微软做PC操作系统,谷歌做移动操作系统,以及后来谷歌发布的TensorFlow,都是这个思路。

在大模型领域,这个规律很可能也成立。在开源大模型领域做到头部,成为事实上的行业标准,商业价值也非常大。Meta就是最好的证明,从市值上看,Meta从2023年开始,就一路长虹,目前市值已经超过万亿美元。
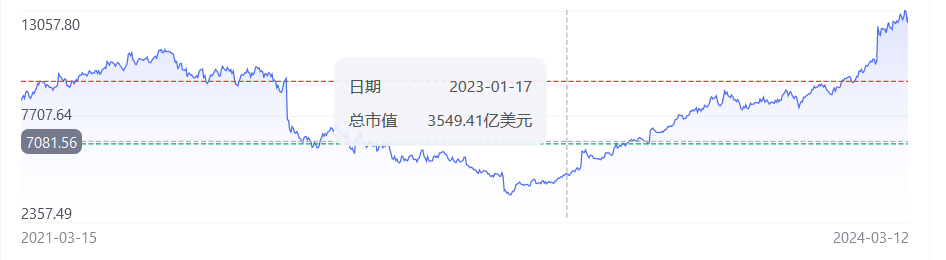
Meta近三年市值变化
可以说,Meta在元宇宙上跌得有多惨,在大模型上笑得就有多开心。而Meta在大模型领域,最拿得出手的就是llama系列开源大模型,其开源大模型的成功,让人们看到了其在AI领域构建类似安卓那样生态的巨大潜力。

开源真的可以干掉闭源么?
目前,有一种声音是,有了开源大模型,所以那些在底层通用大模型赛道创业的公司就没戏了,朱啸虎就持这种观点。而且,头部大公司也经常劝说创业者要在应用场景上找机会,不要在通用大模型上面重复造轮子,这样浪费社会资源,百度的李彦宏就经常这样说。
那么,通用大模型的创业机会真的没有了么?
实事求是的讲,因为开源大模型的存在,通用大模型的创业门槛的确提升了不少。
事实上,大公司开源大模型,有一个摆不上台面的理由,就是要拉高通用大模型的创业门槛。你花几亿研发出的大模型,还没有我开源的好用,那你还花那个冤枉钱干啥?至少,这个逻辑在朱啸虎这样的投资人那里是成立的。从这个意义上讲,科技巨头们开源大模型,就是向赛道上扔了一块不大不小的石头,绊倒了一大片潜在的竞争者,让他们只能在自己搭的台子上唱戏。
而且,开源的往往是比闭源商用的大模型要落后一代,这直接从参数规模上就能看出来。虽然参数规模并不是性能的唯一指标,更小规模的模型表现更好也不是没有可能。但整体上看,更大参数规模,往往意味着更强的能力。这样一来,科技巨头们开源落后一代的大模型,是其延缓竞争的一种策略——基于开源大模型来进行研发的竞争对手,在能力上始终比自己弱一些。这就好像古代君王安抚臣子,“不要想着谋反,好好跟着我干,保你荣华富贵”。

至于智谱AI、百川智能这些创业公司,他们开源大模型,更主要的是为了证明自己的技术能力。当然,能够让自己的技术成为业界标准,那就更好了。
但需要指出的是,开源也存在不少的问题,其中,最核心的就是科技巨头们开源与商用的左右手互搏。
无论是国外的Meta、谷歌,还是国内的阿里巴巴、智谱AI、百川智能,他们都有自己的大模商用产品,并且还指望着这个来巩固甚至扩大其“帝国”的疆域。这种情况下,开源与商用这两条腿,就可能成为互相掐架的两只手。以百川智能为例,客户是直接调用它的商用版本呢,还是在其开源的Baichuan-13B-Base基础上定制?这其中的商业关系怎么来处理?
还有一个很重要的问题,科技企业开源的大模型,是随时可以闭源的。最典型的就是OpenAI,它在GPT-2之前都是开源的,只是在见识到GPT-3强大的能力之后,就偷偷藏起来自己用了。发生在OpenAI身上的事情,能保证在其他开源科技企业身上不会重演?

如果只开源一两代,后面就没有下文了,那这个开源大模型不仅无用,而且有害。好比你修了一条路,前面修的很漂亮,让很多人慕名而来,开车沿着你的道路前进,结果开出去几十公里后,发现一个大大的牌子“此路不通”。那对于已经在路上的人来说,就是一个巨大的沉没成本。
最后,从AI行业本身的演进来看,笔者也希望看到更多在通用大模型领域的创业公司诞生。现在大谈通用大模型的创业窗口已经关闭,还为时尚早。在AGI这条道路上,人类才刚刚摸到一点门道,前路还很漫长。目前,可行的技术路线不止一条,前路还需要很多人去试错,去创新。而创新,却不是大公司的强项。远的不说,就是这次大模型的路线,就是OpenAI这个创业公司趟出来的,而不是谷歌、微软、亚马逊、苹果这种巨头。事实上,这群科技巨头是后知后觉的,现在还处在努力追赶的行列。
因此,现在就把通用大模型创业的路封死,对这个行业而言也许不是一件好事。
文:一蓑烟雨 / 数据猿
责编:凝视深空 / 数据猿



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









